今天就来说说selenium的八种定位方式,八种定位方式基本上可以解决我们自动化测试中定位的绝大部分问题,当然,如果出现定位不到或者元素属性不可见,这就需要我们了解更多的前端知识,通过操作Frame,Dom或者Javascript来解决。
首先WebDriver提供的两个API具有查找元素的能力;
1. 
2. 八种定位当时都封装在By类中

那今天我们就先来看看有哪八种基本的定位方式呢?
1.通过-id来定位元素,html中的id属性一般用来唯一标记一个元素,换句话说,一个元素的id在一个网页中应该是唯一的。
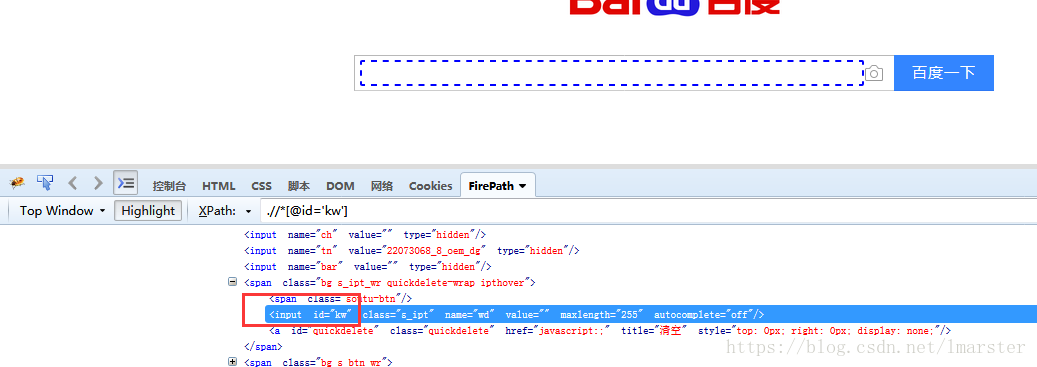
我们以百度为例,通过-id来定位他的搜索框,利用fireBug我们可以看到他的id="kw",所以我们可以通过代码来看一下。
public class EightMthods {public static void main(String[] args) throws Exception { WebDriver driver = new FirefoxDriver(); driver.manage().window().maximize();/**1. 根绝id来定位元素 */String Url = "https://www.baidu.com";driver.get(Url); //输入框driver.findElement(By.id("kw")).sendKeys("you are beautiful");driver.manage().timeouts().pageLoadTimeout(5, TimeUnit.SECONDS);//百度一下按钮driver.findElement(By.id("su")).click();
大家可以运行一下,看看效果吧,但是前提是你的selenium版本要和FireFox或者你的Chrome版本匹配哦
2.通过-xpath来定位,我们还是以百度首页来举个栗子。。。
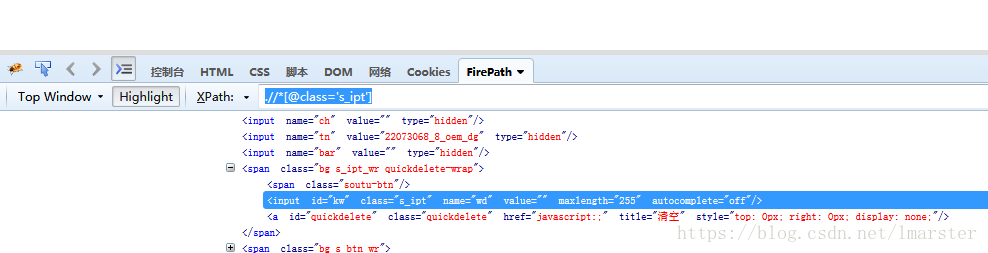
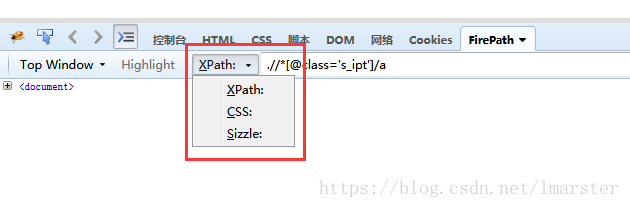
通过F12,我们可以看到输入框的位置 xpath = ".//*[@id='kw']" ,今天这里先不说xpath的构造,之后我会专门写一篇相关的文章介绍,xpath还有一个很好的功能就是他可以debug,比如我们在xpath定位栏输入 xpath = .//*[@class='s_ipt'] ,然后点回车,这个时候如果这个xpath是有效的,那么他就会根据xpath路径去定位到相关的元素,如下图
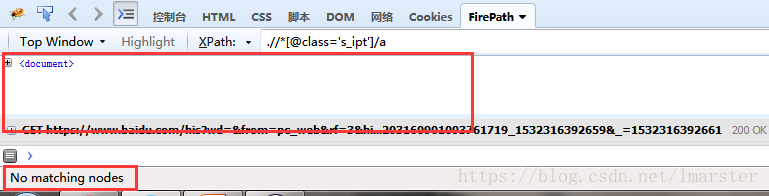
如果xpath格式错误,那么他会是显示红色的,如下图

如果xpath路径错误,那么他会找不到页面元素的信息
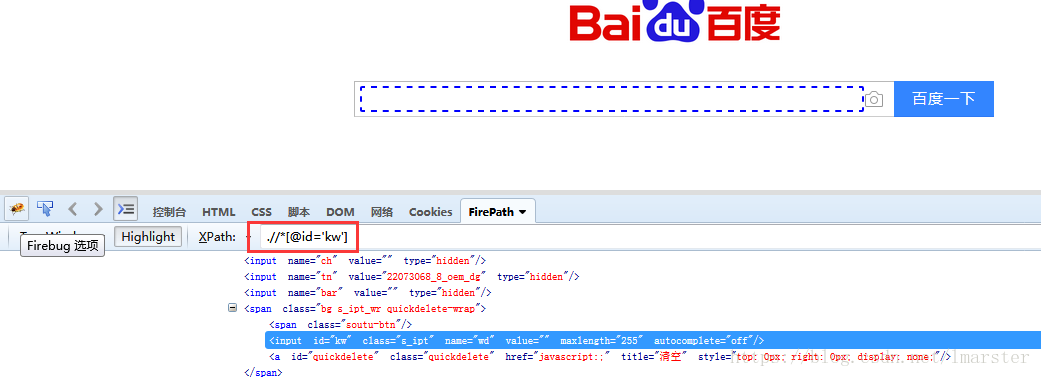
ok,那我们来看一下代码如何实现的
public class EightMthods {public static void main(String[] args) throws Exception { WebDriver driver = new FirefoxDriver(); driver.manage().window().maximize();/**1. 根绝xpath来定位元素 */String PhotoUrl = "https://www.baidu.com";driver.get(PhotoUrl); //通过xpath定位driver.findElement(By.xpath(".//*[@id='kw']")).sendKeys("Lions"); driver.findElement(By.xpath(".//*[@id='su']")).click();
下面我在介绍几个xpath的其他写法
/** xpath--text()方法,百度首页的新闻链接*/driver.findElement(By.xpath(".//*[@id='u_sp']/a[text()='新闻']")).click();/** 对于动态的元素定位,可以使用contains()*///eg 百度首页的【新闻元素】driver.findElement(By.xpath(".//*/a[contains(@href,'news')]")).click();/** xpath相对路径的写法* URL=http://news.baidu.com/* 先根据for = newstitle 或者text()=新闻标题来定位“新闻标题”这个标签。 *///使用for属性来定位driver.findElement(By.xpath(".//*/label[@for='newstitle']/../input[@id='newstitle']")).click();//使用text来定位driver.findElement(By.xpath(".//*/label[text()='新闻标题']/../input[@id='newstitle']")).click();
3.PartialLinkText(String partialLinkText)方法定位,超链接部分文本,基于LinkText (String linkText )-超链接完整文本,不想写那么多的字的时候,选取其中的一部分字段,但是必须在该页面有唯一性, 一般我会选择使用LinkText()方法
public class EightMthods {public static void main(String[] args) throws Exception { WebDriver driver = new FirefoxDriver(); driver.manage().window().maximize();/**1. 根绝linkText&partialLinkText来定位元素 */String PhotoUrl = "http://photo.163.com";driver.get(PhotoUrl); //通过xpath定位/**使用下面这段代码请把地址更换为百度首页地址*driver.findElement(By.linkText("把百度设为主页")).click();*/WebElement LearnMoreLink = driver.findElement(By.partialLinkText("了解更多"));//点击了解更多LearnMoreLink.click();
4.用样式选择器定位cssSelector (String cssSelector),css即层叠样式表,通过 css可以描述标签的样式,如字体的大小,颜色,标签布局,间距等, 样式选择器是一种非常使用又容易被开发者忽略的定位方式。
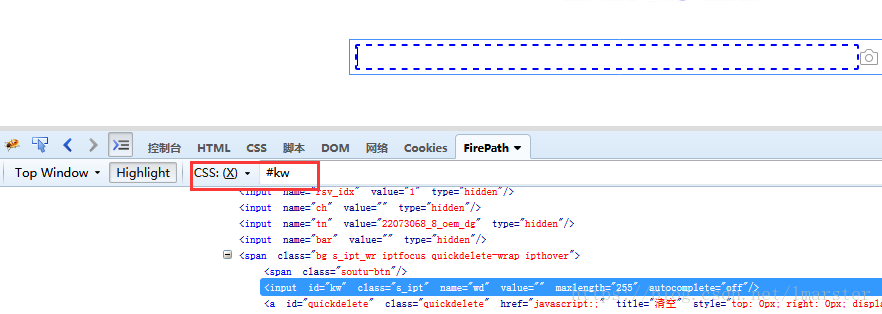
如百度首页的输入框元素,用#id的值表示这个元素的css表达式
public class EightMthods {public static void main(String[] args) throws Exception { //首先要创建一个driver驱动的实例对象,这里用Firefox浏览器来演示WebDriver driver = new FirefoxDriver(); driver.manage().window().maximize();/**1. 根绝cssSelector来定位元素 */String PhotoUrl = "https://www.baidu.com";driver.get(PhotoUrl); //通过iddriver.findElement(By.cssSelector("#kw")).sendKeys("For beauty");//By.cssSelector("标签名#id")//如百度输入框:By.cssSelector("input#kw"));//通过className(样式名)方式 By.cssSelector(".className");//如百度输入框: By.cssSelector(".s_ipt");//By.cssSelector("标签名.className") ;//如百度输入框:By.cssSelector("input.s_ipt");//通过元素属性,语法:By.cssSelector("标签名[属性名1 = '属性值'][属性名2 = '属性值']") 可以是多属性也可以是单属性,非常实用。//By.cssSelector("input[value='255'][autocomplete ='off']")//By.cssSelector(input[autocomplete='off'])driver.findElement(By.cssSelector("#su")).click();
如果感觉自己写的不准确的话,可以使用Firepath,切换为CSS选择器就ok了




 京公网安备 11010802041100号
京公网安备 11010802041100号