作者:xuncijins | 来源:互联网 | 2023-06-20 15:34
JanusGraph索引入门及模糊查询-JanusGraph模糊查询与索引1.索引JanusGraph支持两种不同类型的索引来加快查询处理:图形索引和中心顶点索引图形索引
JanusGraph模糊查询与索引
1. 索引
JanusGraph 支持两种不同类型的索引来加快查询处理:图形索引和中心顶点索引
图形索引使从由其属性标识的顶点或边列表开始遍历的全局检索操作在大型图形上高效
中心顶点索引可加快通过图形的实际遍历,尤其是在遍历具有许多入射边的顶点时
1.1 图形索引
图形索引又分为两种类型的图形索引: 复合索引和混合索引
复合索引非常快速、高效,但仅限于对以前定义的特定属性键组合的相等查找
混合索引可用于索引键的任意组合上的查找,并且除了根据支持索引存储的相等性外,还支持多个条件谓词
复合索引不需要配置索引后端,混合索引依赖索引后端
| 特性 |
复合索引 |
混合索引 |
| 依赖后端 |
依赖存储后端(Cassandra, HBase, Berkeley DB) |
依赖索引后端(ElasticSearch, solr, Lucene) |
| 模糊查询,范围查询等 |
不支持 |
支持 |
| 速度 |
快速 |
比复合慢 |
| 灵活性 |
仅限于固定组合属性键 |
可以任意组合属性键 |
| 支持条件谓词 |
不支持 |
支持 |
| 索引唯一性约束 |
支持 |
不支持 |
Label Constraint 只针对特定label的顶点或边进行索引,可以在创建索引时添加indexOnly()方法来进行限制
name = mgmt.getPropertyKey('name')
olt = mgmt.getVertexLabel('olt')
mgmt.buildIndex('byNameAndLabel',Vertex.class).addKey(name).indexOnly(olt).buildCompositeIndex()
mgmt.commit()
Ordering 对查询结果进行排序
- 复合索引不支持排序查询,其会查询到的所有的符合条件的数据放入内存中进行排序
- 混合索引支持排序查询,但是查询的属性必须是混合索引中存在的,否则会将所有查询结果放入内存中进行排序
1.2 中心顶点索引
中心顶点索引是按顶点单独生成的局部索引结构。
中心顶点索引是用来解决图库中臭名昭著的超级节点问题(有很多条边的节点)
在大型图形中,顶点可以有数千个入射边。遍历这些顶点可能非常慢,因为必须检索事件边的很大一部分,然后在内存中筛选以匹配遍历的条件。中心顶点索引可以使用本地化的索引结构仅检索需要遍历的边来加快此类遍历速度。
graph.tx().rollback() //Never create new indexes while a transaction is active
mgmt = graph.openManagement()
time = mgmt.getPropertyKey('time')
battled = mgmt.getEdgeLabel('battled')
//构建中心顶点索引参数列表(边标签名,自定义索引名称,边方向,排序顺序,属性键)
mgmt.buildEdgeIndex(battled, 'battlesByTime', Direction.BOTH, Order.desc, time)
mgmt.commit()
//Wait for the index to become available
ManagementSystem.awaitRelationIndexStatus(graph, 'battlesByTime').call()
//Reindex the existing data
mgmt = graph.openManagement()
mgmt.updateIndex(mgmt.getRelationIndex(battled, "battlesByTime"), SchemaAction.REINDEX).get()
mgmt.commit()
1.3 索引的生命周期
(1)索引状态和转换
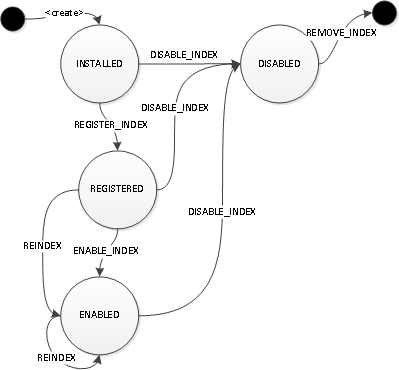
(2)状态
-
INSTALLED 索引安装在系统中,但尚未在群集中的所有实例中注册
-
REGISTERED 索引已注册为群集中的所有实例,但未(尚未)启用
-
ENABLED 索引已启用且正在使用中
-
DISABLED 索引已禁用且不再使用
(3)操作
可通过 以下操作对索引执行以下操作,以便通过 更改其状态:mgmt.updateIndex()
-
REGISTER_INDEX 使用图形群集中的所有实例注册索引。安装索引后,必须将其注册到所有图形实例
-
REINDEX 从图形重新生成索引
-
ENABLE_INDEX 启用索引,以便查询处理引擎可以使用索引。必须先注册索引,然后才能启用索引。
-
DISABLE_INDEX 禁用图形中的索引,以便不再使用它。
-
REMOVE_INDEX 从图形中删除索引(可选操作)。仅在复合索引上。
2. 模糊查询
图库支持模糊查询,但模糊查询需要遍历所有的顶点/边,所以需要混合索引的支持
如果模糊查询时没有索引支持,gremlin会给出警告
10:24:38 WARN org.janusgraph.graphdb.transaction.StandardJanusGraphTx - Query requires iterating over all vertices [(name textRegex .合肥.)]. For better performance, use indexes
2.1 全文搜索
当该值被索引为文本时,字符串被标记成单词包,允许用户有效地查询包含一个或多个单词的所有匹配项。这通常称为全文搜索。
默认情况下, 字符串作为文本索引, 也可以在定义时显示的定义(比标准的混合索引定义多了Mapping.TEXT.asParameter()):
mgmt = graph.openManagement()
summary = mgmt.makePropertyKey('booksummary').dataType(String.class).make()
mgmt.buildIndex('booksBySummary', Vertex.class).addKey(summary, Mapping.TEXT.asParameter()).buildMixedIndex("search")
mgmt.commit()
当字符串作为文本编制索引时, JanusGraph默认标记拆分非字母数字的字符串, 并删除少于2个字符的任何标记(具体看索引后端默认配置)
当字符串属性作为文本编制索引时,索引后端在图形查询中仅支持全文搜索谓词。全文搜索不区分大小写。
-
textContains: 如果(至少)文本字符串中的一个单词与查询字符串匹配, 则为true
-
textContainsPrefix: 如果(至少)文本字符串中的一个单词以查询字符串开头, 则为true
-
textContainsRegex: 如果(至少)文本字符串中的一个单词与给定正则表达式匹配, 则为true
-
textContainFuzzy: 如果(至少)文本字符串中的一个单词与查询字符串类似(基于 Levenshtein 编辑距离), 则为true
g.V().has('booksummary', textContains('unicorns'))
g.V().has('booksummary', textContainsPrefix('uni'))
g.V().has('booksummary', textContainsRegex('.*corn.*'))
g.V().has('booksummary', textContainsFuzzy('unicorn'))
2.2 字符串搜索
当该值作为字符串编制索引时,该字符串是索引"样",无需任何进一步分析或标记化。这便于查询查找确切的字符序列匹配。这通常称为字符串搜索。
要将字符串属性键索引为字符序列, 而无需进行任何分析或标记化, 请将映射指定为: Mapping.STRING
mgmt = graph.openManagement()
name = mgmt.makePropertyKey('bookname').dataType(String.class).make()
mgmt.buildIndex('booksBySummary', Vertex.class).addKey(name,Mapping.STRING.asParameter()).buildMixedIndex("search")
mgmt.commit()
当字符串属性被索引为字符串时,索引后端在图形查询中仅支持以下谓词。字符串搜索区分大小写。
-
eq: 如果字符串与查询字符串相同
-
neq: 如果字符串与查询字符串不同
-
textPrefix: 如果字符串以给定的查询字符串开头
-
textRegex: 如果字符串值与给定正则表达式完全匹配
-
textFuzzy: 如果字符串值与给定的查询字符串类似(基于 Levenshtein 编辑距离)
g.V().has('bookname', eq('unicorns'))
g.V().has('bookname', neq('unicorns'))
g.V().has('bookname', textPrefix('uni'))
g.V().has('bookname', textRegex('.*corn.*'))
g.V().has('bookname', textFuzzy('unicorn'))
2.3 字符串和全文搜索
如果索引后端使用ElasticSearch, 则可以将属性索引为文本和字符串, 从而允许您使用所有的谓词进行精确和模糊匹配
mgmt = graph.openManagement()
summary = mgmt.makePropertyKey('booksummary').dataType(String.class).make()
mgmt.buildIndex('booksBySummary', Vertex.class).addKey(summary,Mapping.TEXTSTRING.asParameter()).buildMixedIndex("search")
mgmt.commit()
2.4 TinkerPop文本谓词
也可以将 TinkerPop 文本谓词与 JanusGraph 一起使用,但这些谓词不使用索引,这意味着它们需要在内存中进行筛选,这可能非常耗费内存。
g.V().has('bookname', startingWith('uni'))
g.V().has('bookname', endingWith('corn'))
g.V().has('bookname', containing('nico'))
3. 总结
JanusGraph的索引支持已经相对比较完善,对于不同种类的索引需求分别用复合索引、混合索引及中心顶点索引来实现不同的功能。在具体场景实现中,需要谨慎考虑索引的构建,其重要性应与Schema结构一样且息息相关。
索引中的混合索引需要配置索引后端,在索引后端的选择中应该考虑以ElasticSearch优先。ElasticSearch不仅支持多种多样的查询功能,如全文搜索、范围搜索、模糊查询和评分算法等,还支持Lucene查询语法,同时使用人数多,社区活跃。






 京公网安备 11010802041100号
京公网安备 11010802041100号