
1 问题情况
[root@cdh4 scripts]# cat createSourceTable.sql
create database if not exists iot_test;
use iot_test;
create table if not exists hive_table_text (
ordercoldaily BIGINT,
smsusedflow BIGINT,
gprsusedflow BIGINT,
statsdate TIMESTAMP,
custid STRING,
groupbelong STRING,
provinceid STRING,
apn STRING )
PARTITIONED BY ( subdir STRING )
ROW FORMAT DELIMITED FIELDS TERMINATED BY "," ;
./hivesql_exec.sh createSourceTable.sql
查看测试表,在beeline中
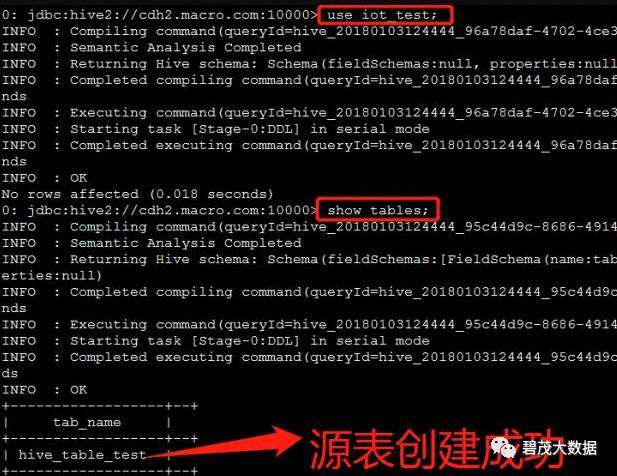
执行命令,查看表结构
show create table hive_table_test;

[root@cdh4 scripts]# cat gendata.sh
function rand(){
min=$1
max=$(($2-$min+1))
num=$(($RANDOM+1000000000))
echo $(($num%$max+$min))
}
let i=1
while [ $i -le 3 ];
do
let n=1
while [ $n -le $1 ];
do
let mOnth=$n%12+1
if [ $month -eq 2 ];then
let day=$n%28+1
else
let day=$n%30+1
fi
let hour=$n%24
rnd=$(rand 10000 10100)
echo "$i$n,$i$n,$i$n,2017-$month-$day $hour:20:00,${rnd},$n,$n,$n" >> data$i.txt
let n=n+1
done
let i=i+1
done
./gendata.sh 300000
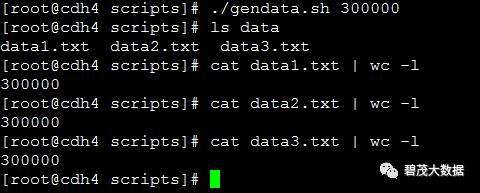
# 运行upLoad.sh脚本,将测试数据上传至HDFS的/tmp/hive目录下
[root@cdh4 scripts]# cat upLoadData.sh
#!/bin/sh
num=3
path='/tmp/hive'
#create directory
sudo -u hdfs hdfs dfs -mkdir -p $path
sudo -u hdfs hdfs dfs -chmod 777 $path
#upload file
let i=1
while [ $i -le $num ];
do
hdfs dfs -put data${i}.txt $path
let i=i+1
done
#list file
hdfs dfs -ls $path
验证
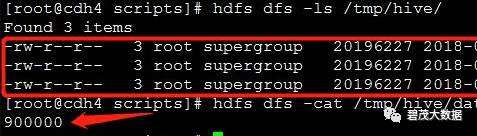
加载数据进入测试表
# 执行./hivesql_exec.sh loadData.sql命令,加载数据
[root@cdh4 scripts]# cat loadData.sql
use iot_test;
LOAD DATA INPATH '/tmp/hive/data1.txt' INTO TABLE hive_table_test partition (subdir="10");
LOAD DATA INPATH '/tmp/hive/data2.txt' INTO TABLE hive_table_test partition (subdir="20");
LOAD DATA INPATH '/tmp/hive/data3.txt' INTO TABLE hive_table_test partition (subdir="30");
# 生成Parquet表语句如下,其中“statsdate”字段为TIMESTAMP类型
[root@cdh4 scripts]# cat genParquet.sql
use iot_test;
create table hive_table_parquet (
ordercoldaily BIGINT,
smsusedflow BIGINT,
gprsusedflow BIGINT,
statsdate TIMESTAMP,
custid STRING,
groupbelong STRING,
provinceid STRING,
apn STRING )
PARTITIONED BY ( subdir STRING )
STORED AS PARQUET;
set hive.exec.dynamic.partition=true;
set hive.exec.dynamic.partition.mode=nonstrict;
insert overwrite table hive_table_parquet partition (subdir) select * from hive_table_test
./hivesql_exec.sh genParquet.sql
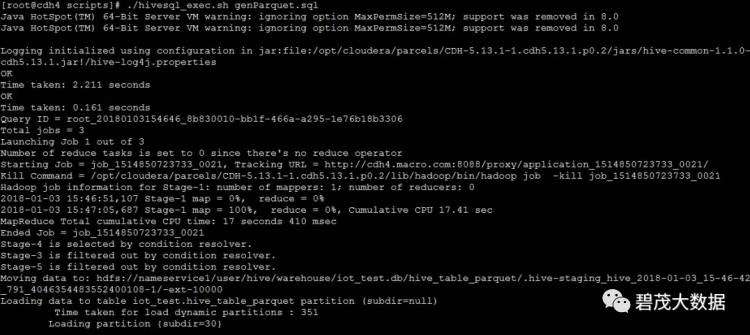
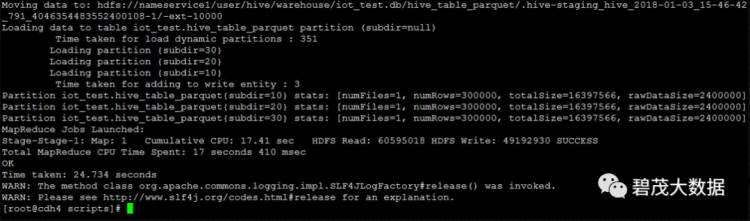
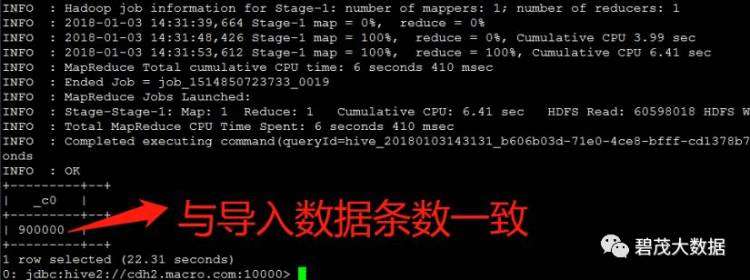
select count(*) from hive_table_parquet;
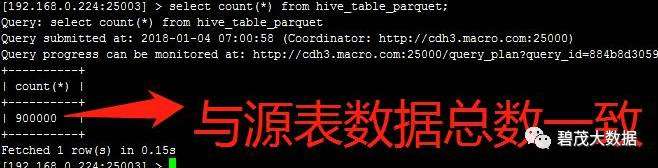
[root@cdh4 scripts]# hdfs dfs -ls -R user/hive/warehouse/iot_test.db/hive_table_parquet/
[root@cdh4 scripts]# parquet-tools meta hdfs://cdh3.macro.com:8020/user/hive/warehouse/iot_test.db/hive_table_parquet/subdir=10/000000_0
creator: parquet-mr version 1.5.0-cdh5.13.1 (build ${buildNumber})
file schema: hive_schema
# Impala负载均衡地址为:cdh4.macro.com:25003
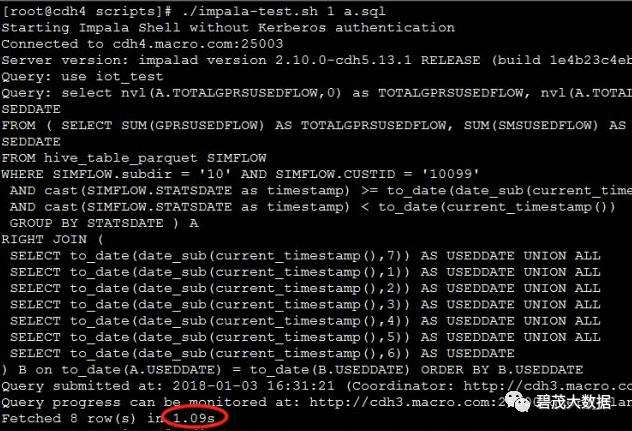
[root@cdh4 scripts]# cat impala-test.sh
#!/bin/sh
#Concurrency test
let i=1
while [ $i -le $1 ];
do
impala-shell -B -i cdh4.macro.com:25003 -u hive -f $2 -o log/${i}.out &
let i=i+1
done
wait
SELECT
nvl(A.TOTALGPRSUSEDFLOW,0) as TOTALGPRSUSEDFLOW, nvl(A.TOTALSMSUSEDFLOW,0) as TOTALSMSUSEDFLOW, B.USEDDATE AS USEDDATE
FROM ( SELECT SUM(GPRSUSEDFLOW) AS TOTALGPRSUSEDFLOW, SUM(SMSUSEDFLOW) AS TOTALSMSUSEDFLOW, cast(STATSDATE as timestamp) AS USEDDATE
FROM hive_table_parquet SIMFLOW
WHERE SIMFLOW.subdir = '10' AND SIMFLOW.CUSTID = '10099'
AND cast(SIMFLOW.STATSDATE as timestamp) >= to_date(date_sub(current_timestamp(),7))
AND cast(SIMFLOW.STATSDATE as timestamp) GROUP BY STATSDATE ) A
RIGHT JOIN (
SELECT to_date(date_sub(current_timestamp(),7)) AS USEDDATE UNION ALL
SELECT to_date(date_sub(current_timestamp(),1)) AS USEDDATE UNION ALL
SELECT to_date(date_sub(current_timestamp(),2)) AS USEDDATE UNION ALL
SELECT to_date(date_sub(current_timestamp(),3)) AS USEDDATE UNION ALL
SELECT to_date(date_sub(current_timestamp(),4)) AS USEDDATE UNION ALL
SELECT to_date(date_sub(current_timestamp(),5)) AS USEDDATE UNION ALL
SELECT to_date(date_sub(current_timestamp(),6)) AS USEDDATE
) B on to_date(A.USEDDATE) = to_date(B.USEDDATE) ORDER BY B.USEDDATE
测试Impala并发
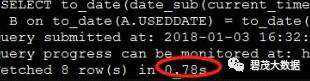
测试1个并发查询,以下共三次测试返回查询结果:

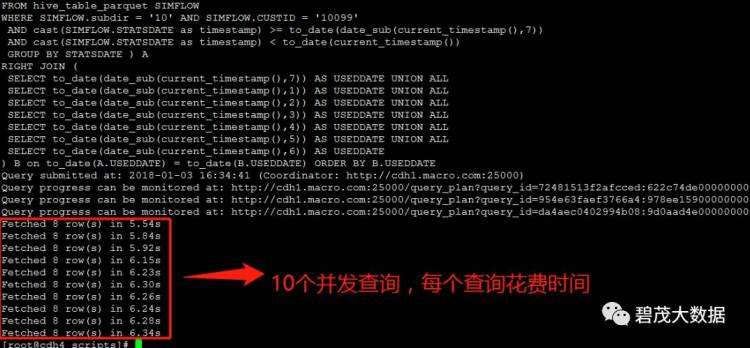
测试10个并发查询,以下共三次测试返回查询结果:
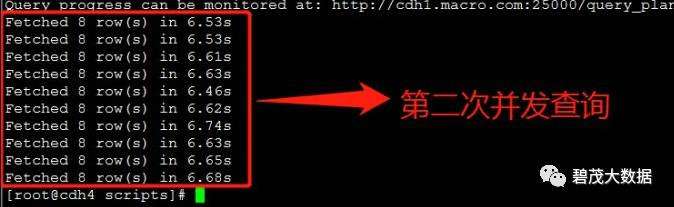
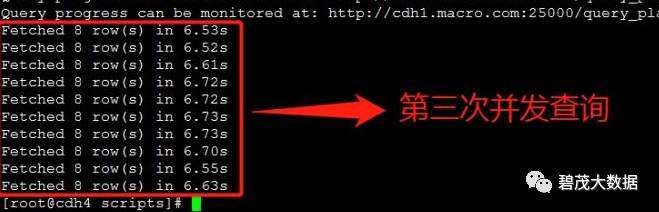
测试30个并发查询,以下共三次测试返回查询结果:
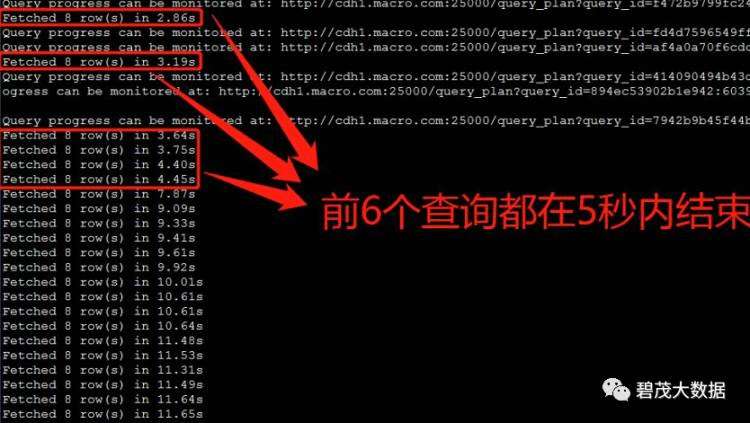
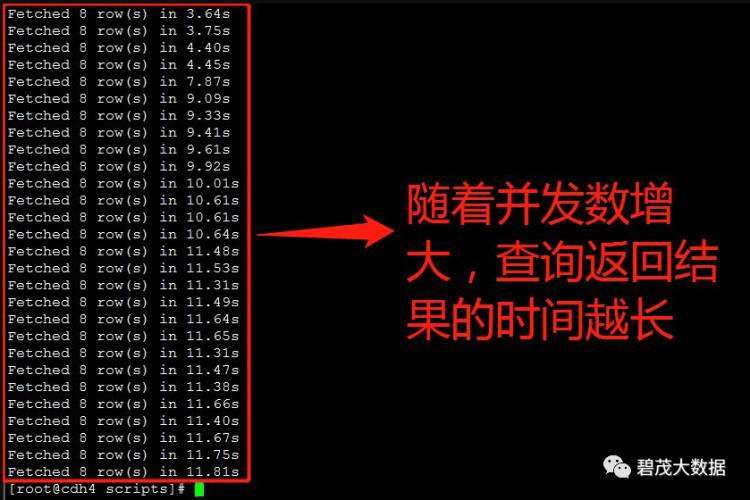
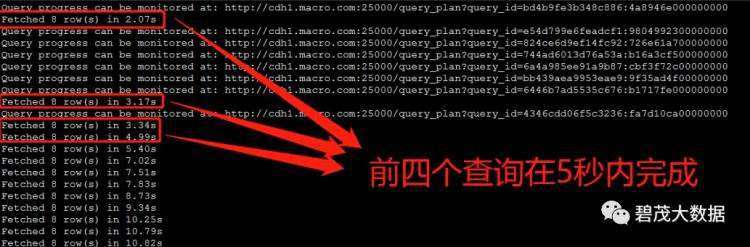
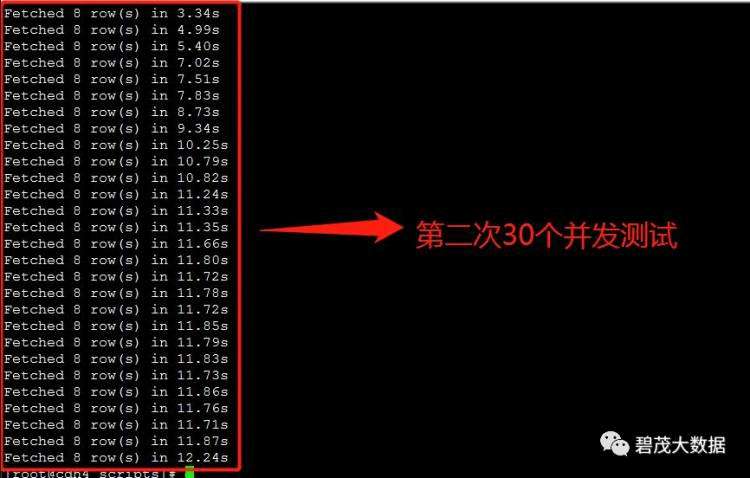
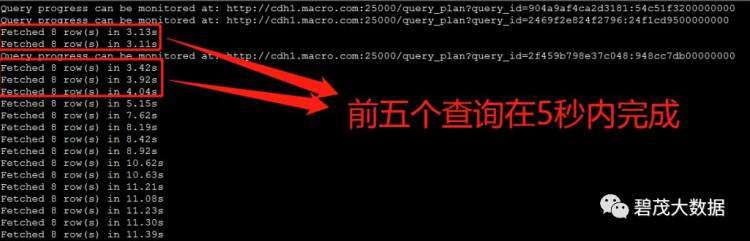
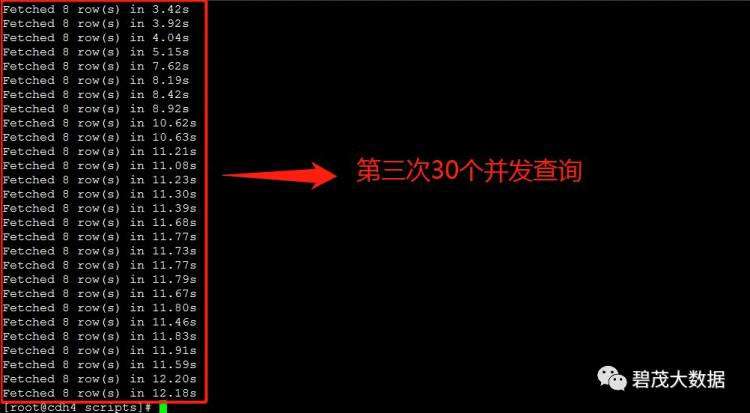
随着并发查询数量的增多,Impala查询性能越差
2 问题分析

3 解决方法
方法一:
方法二:
方法三:
关注公众号:领取精彩视频课程&海量免费语音课程









 京公网安备 11010802041100号
京公网安备 11010802041100号