在人类视觉感知中,很容易将注意力集中在场景的显着目标上。在计算机视觉的许多问题中,需要类似的机制以允许计算机更好地理解场景。特别是具有明确人类目的的应用场景。
用户的照片通常在背景中很复杂。该算法实际上需要关注用户在拍照时感兴趣的目标(这通常是场景中最重要的目标),然后转到数据库以检索相同和相似的对象。
最近,南开大学媒体计算实验室提出的最新边缘检测和图像过分割(可用于生成超像素)被IEEE PAMI接受。

该研究的第一作者也在微博上说:“这是第一个在最广泛使用的图像分割数据集BSD500上手动平均F-Measure评估值的实时算法。图像分割效果也得到了更新。准确度记录 该算法也是开源的。“

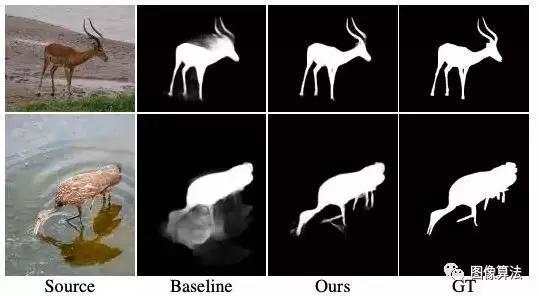
下图显示了EGNet在本文中检测到的重要目标的示例:
算法原理
从EGNet:EGNet: Edge Guidance Network for Salient Object Detection,我们可以看到本文的最大创新是使用边缘信息来指导网络进行重要的目标检测。
这很容易理解,显着性目标和背景之间通常有明显的优势。
从由重要目标数据集标记的掩模中提取边缘并不困难。如何使用边缘信息?
下图显示了作者的算法设计原则:

其核心是更丰富的特征:每个阶段的所有转换层都是有用的,而不是传统的,只要每个阶段的最后一个转换层。这是一种非常通用的技术,基本上是使用什么任务,并且可以实现几行代码。
使用VGG16网络,我们的方法在几个常见数据集上具有最佳性能(最先进的)。在BSDS500基准数据集上进行测试和评估时,F-Measure得分(F-measure)得分为0.811,速度为8 FPS。此外,RCF方法的快速版本实现了0.806和30 FPS的速度。为了证明所提方法的多功能性,我们还将RCF检测的边缘应用于图像分割问题。
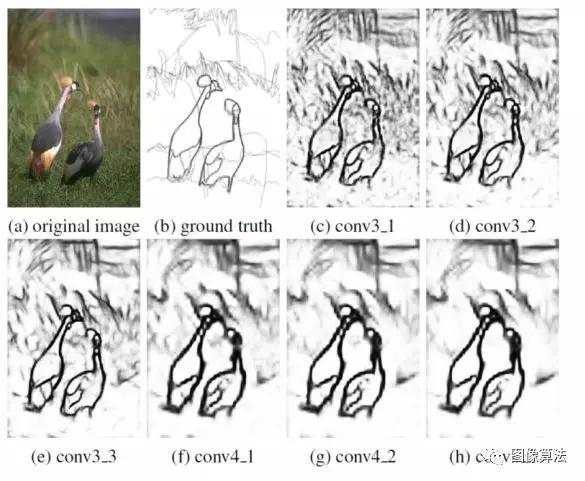
我们构建了一个基于VGG16的简单神经网络,得到conv3_1,conv3_2,conv3_3,conv4_1,conv4_2和conv4_3各层的输出。从上图可以清楚地看出,卷积特征逐渐变得粗糙,并且中间层conv3_1,conv3_2,conv4_1和conv4_2包含许多有用的精确细节,并且这些细节不出现在其他层中。

上图显示了RCF网络架构。网络的输入是任何大小的图像,并且网络的输出是相同大小的边缘检测图。我们将每个卷积层的层次特征组合成一个整体框架,并训练所有参数进行学习。由于VGG16的感受域在大小上彼此不同,我们的网络可以学习多尺度,包括低尺度和对象级信息,这些信息将有助于边缘检测。
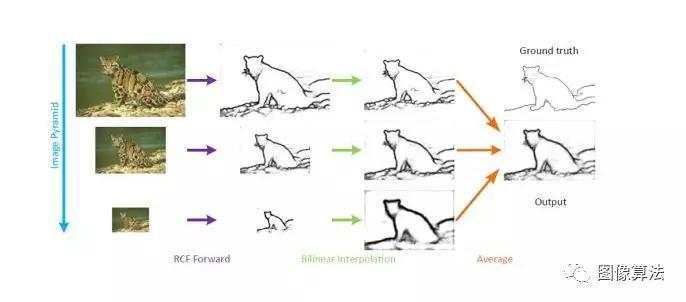
上图是多尺度算法的流水线图。调整原始图像的大小以构建图像金字塔。然后将这些多尺度图像输入RCF网络以进行前向传送。接下来,我们使用双线性插值将生成的边缘检测图恢复为其原始大小。这些边缘图的简单平均计算产生高质量的边缘图。
BSDS500数据集的评估结果

上图是50年来边缘检测方法性能的总结。我们的方法是第一个获得比人类注释器更好的F-Measure分数的实时系统。

论文地址:https://arxiv.org/pdf/1908.08297v1.pdf
论文源码关注微信公众号:“图像算法”或者微信搜索账号imalg_cn关注公众号












 京公网安备 11010802041100号
京公网安备 11010802041100号