作者:shannnon | 来源:互联网 | 2023-10-12 20:26
霍夫曼树基本概念:
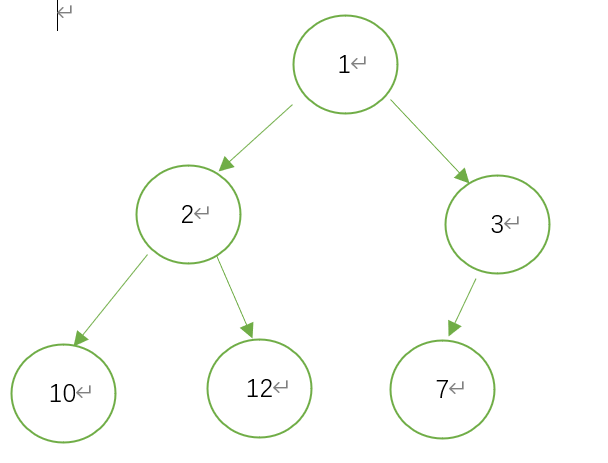
路径:从一个结点往下到孩子或孙子结点之间的同理
路径长度:如结点1到结点7的路径长度=2
结点的权:将结点的某一属性值作为结点的权
带权路径长度:从根节点到该结点*该结点的权;如结点1到结点7的带权路径长度:7*2=14
的带权路径长度(WPL):该树的所有叶子结点的带权路径长度之和
霍夫曼树:给定n个权值,构造一颗二叉树并由这n个权值作为数的叶子结点,且该树的带权路径长度(WPL)达最小,这样的二叉树成为最优二叉树,也叫霍夫曼树
霍夫曼树特点:权值越大的叶子结点离根节点越近


霍夫曼编码:
编码规则:
(1)给定一个字符串,统计各个字符出现的次数,将次数作为权值构成霍夫曼树;例如“i like like like java do you like a java”转化为霍夫曼树为:

(2)规定路径向左为0,向右为1,则各个权值的路径即为他们的霍夫曼编码

注意:
(1)霍夫曼编码为前缀编码,即任何编码不会是其他编码的前缀(因为叶子结点)
(2)若出现权值相同的结点,则根据排序方法不同,对应的霍夫曼编码也不完全相同,但压缩率是相同的。
代码实现:
以“i like like like java do you like a java”为例
结点
class ByteNode implements Comparable {Byte data;//存放字符本身,注意用包装类方便存入集合中int weight;//权值,表示字符出现的次数ByteNode left;ByteNode right;public ByteNode(Byte data, int weight) {this.data = data;this.weight = weight;}@Overridepublic int compareTo(ByteNode o) {return this.weight - o.weight;}@Overridepublic String toString() {return "ByteNode{" +"data=" + data +", weight=" + weight +'}';}//前序遍历public void preOrder() {System.out.println(this);if (this.left != null)this.left.preOrder();if (this.right != null)this.right.preOrder();}
}
字符串->生成结点并放入List中
private static List getList(String str) {byte[] bytes&#61;str.getBytes();//转换为byte数组,得到一个个字符HashMap counts &#61; new HashMap<>();//统计字符&#43;次数&#xff0c;需要Map实现//遍历bytes,统计每个byte出现的次数&#xff0c;存放到Hashmap中for (byte b : bytes) {Integer count &#61; counts.get(b);//get(key)&#xff0c;返回valueif (count &#61;&#61; null)counts.put(b, 1);elsecounts.put(b, count &#43; 1);//如果放入相同的key&#xff0c;则新的值会替换旧的}//将Map保存的字符&#43;次数生成结点&#xff0c;并存放到List中ArrayList nodesList &#61; new ArrayList<>();for (Map.Entry entry : counts.entrySet()) {//遍历map,将node结点加入到list中nodesList.add(new ByteNode(entry.getKey(), entry.getValue()));}return nodesList;}
输出&#xff1a;
List->霍夫曼树
//list生成霍夫曼树private static ByteNode getHuffManTree(List list) {while (list.size() > 1) {Collections.sort(list);ByteNode leftNode &#61; list.get(0);ByteNode rightNode &#61; list.get(1);ByteNode parent &#61; new ByteNode(null, leftNode.weight &#43; rightNode.weight);//注意父节点都设为nullparent.left &#61; leftNode;parent.right &#61; rightNode;list.remove(leftNode);list.remove(rightNode);list.add(parent);}return list.get(0);}
返回的为Root结点&#xff0c;非叶子节点的Byte属性都为null&#xff0c;叶子结点的Byte属性不为null
霍夫曼树->霍夫曼编码表&#xff0c;将表存在Map中
//由霍夫曼树得到霍夫曼编码表static Map huffmanCodes &#61; new HashMap();//存放编码static StringBuilder stringBuilder &#61; new StringBuilder();//初始为null/*** &#64;param node 传入root结点* &#64;param code 路径&#xff1a;左子结点&#61;0&#xff1b;右子结点&#61;1* &#64;param stringBuilder 用于拼接路径*/private static void getCodes(ByteNode node, String code, StringBuilder stringBuilder) {StringBuilder stringBuilder1 &#61; new StringBuilder(stringBuilder);//每次调用getCodes方法都要new一个StringBuilder,否则回溯时StringBuilder的值并不会回溯stringBuilder1.append(code);if (node !&#61; null) {if (node.data &#61;&#61; null) {//非叶子结点getCodes(node.left, "0", stringBuilder1);//向左递归getCodes(node.right, "1", stringBuilder1);//向右递归} else//到达叶子结点huffmanCodes.put(node.data, stringBuilder1.toString());}}
输出&#xff1a;Map

字符串->根据霍夫曼编码进行压缩&#xff0c;存放到byte[]数组
//数据压缩&#xff1a;将一个字符串利用霍夫曼编码压缩后存入byte[]数组public static byte[] zip(String str) {//获得霍夫曼编码表List list &#61; getList(str);ByteNode root &#61; getHuffManTree(list);getCodes(root, "", new StringBuilder());//将编码表按原字符串的顺序放入StringBuilder中byte[] bytes &#61; str.getBytes();StringBuilder stringBuilder &#61; new StringBuilder();for (byte b : bytes)stringBuilder.append(huffmanCodes.get(b));//再存放在Byte[]数组中&#xff0c;每个元素存8位int len;//返回的byte数组的长度 等价于len&#61;(stringBuilder.length()&#43;7)/8if (stringBuilder.length() % 8 &#61;&#61; 0)len &#61; stringBuilder.length() / 8;elselen &#61; stringBuilder.length() / 8 &#43; 1;byte[] by &#61; new byte[len];int index &#61; 0;for (int i &#61; 0; i stringBuilder.length()) {//最后不足8位strByte &#61; stringBuilder.substring(i);//截取从第i位开始&#xff0c;一直到结束的字符串} else {strByte &#61; stringBuilder.substring(i, i &#43; 8);}//8位二进制会被识别为补码&#xff0c;将转换为原码&#xff0c;再转为10进制保存在by[]数组中by[index] &#61; (byte) Integer.parseInt(strByte, 2);index&#43;&#43;;}return by;}
8位霍夫曼编码对应存储在byte[ ]数组中&#xff1a;
10101000原码是&#xff1a;11010110&#xff0c;转为10进制为-88

对压缩后的数组解压&#xff1a;
&#xff08;1&#xff09;先写一个方法&#xff0c;能将byte转为二进制字符串
//数据解压&#xff08;1&#xff09;&#xff1a;将存储霍夫曼编码的byte数组中每个值转为原字符串//flag:判断是否是byte数组的最后一个值&#xff0c;因为最后一个值对应的霍夫曼编码可能不足8位private static String byteToBitString(boolean flag, byte b) {int temp &#61; b;if (flag) {temp |&#61; 256;//当b为正数&#xff0c;原码&#61;补码&#xff0c;但结果可能不足8位->将其转为二进制&#xff0c;再与1 0000 0000求或进行位数扩充&#xff0c;取后八位仍是b的原码}String str &#61; Integer.toBinaryString(temp);//b转换为二进制&#xff0c;再转为其补码保存在s里&#xff1b;由于String存储的字节数更大&#xff0c;只需要s的后8位if (flag) {return str.substring(str.length() - 8);//从str.length()-8开始&#xff0c;至字符串结束&#xff0c;共8位}else return str;//若byte数组最后一个值为正&#xff0c;其对应的霍夫曼编码可能8位也可能不足8位&#xff0c;直接返回即可&#xff1b;为负&#xff0c;其对应的霍夫曼编码仍为8位}


&#xff08;2&#xff09;对压缩后的byte[ ]数组进行解压
//数据解压&#xff08;2&#xff09;//by[] 是原字符串经霍夫曼编码后的数组private static byte[] decode(Map huffmanCodes,byte[] by){StringBuilder stringBuilder &#61; new StringBuilder();//存放二进制字符串//将byte数组转为二进制的字符串for (int i&#61;0;i map&#61;new HashMap();for (Map.Entry entry:huffmanCodes.entrySet()){map.put(entry.getValue(),entry.getKey());}List list&#61;new ArrayList();//截取的字符存放到List中//开始截取for (int i&#61;0;i 
将一个文件进行压缩&#xff1a;
//将一个文件进行压缩public static void zipFile(String srcFile, String dstFile) throws Exception {FileInputStream fis &#61; new FileInputStream(srcFile);byte[] b &#61; new byte[fis.available()];//fis.available()返回文件的大小fis.read(b);//文件的内容写入byte数组中fis.close();byte[] zip &#61; zip(new String(b));FileOutputStream fos &#61; new FileOutputStream(dstFile);ObjectOutputStream oos &#61; new ObjectOutputStream(fos);//利用对象流&#xff0c;写入霍夫曼编码&#xff0c;有利于恢复原文件oos.writeObject(zip);oos.writeObject(huffmanCodes);oos.close();fos.close();}
将一个文件进行解压&#xff1a;
//将文件进行解压public static void decodeFile(String zipFile, String dstFile) throws Exception {FileInputStream fis &#61; new FileInputStream(zipFile);//用对象输入流得到输入的文件ObjectInputStream ois &#61; new ObjectInputStream(fis);byte[] by &#61; (byte[]) ois.readObject();Map map &#61; (Map) ois.readObject();//解码byte[] decode &#61; decode(map, by);//将数据写入文件FileOutputStream fos &#61; new FileOutputStream(dstFile);fos.write(decode);fos.close();ois.close();fis.close();}
注意点&#xff1a;
(1)输出字符类型&#xff0c;byte型与int型比较
byte b &#61; &#39;a&#39;;
sout&#xff08;b&#xff09;-> 97
byte b1 &#61; 40;
sout(b1) -> 40
int i &#61; 97;
int i1 &#61; 40;
sout(i &#61;&#61; b) -> true
sout(i1 &#61;&#61; b1) -> true
(2)String与byte关系&#xff0c;以及相互转换
String&#61;byte[8]&#xff0c;1个byte字节能存8位无符号数字
byte[ ] b &#61; {&#39;a&#39;,&#39;b&#39;};
sout(b); -> [b&#64;41628346
sout(Arrays.toString(b)); -> [97,98]
sout(new String(b)); -> ab
String转为byte[ ]数组&#xff1a;
String str &#61;"I like java";
byte[ ] by &#61; str.getBytes();
(3)String拼接使用StringBuilder
StringBuilder线程不安全&#xff0c;StringBuffer线程安全&#xff0c;一般用前者&#xff1b;
拼接方法一&#xff1a;

String s &#61; "hello" 会在常量池开辟一个内存空间来存储”hello"。
s &#43;&#61; "world"会先在常量池开辟一个内存空间来存储“world"。然后再开辟一个内存空间来存储”helloworld“。
这么以来&#xff0c;001与002就成为了垃圾内存空间了。这么简单的一个操作就产生了两个垃圾内存空间&#xff0c;如果有大量的字符串拼接&#xff0c;将会造成极大的浪费。
拼接方法二&#xff1a;
StringBuilder的字符串拼接是直接在原来的内存空间操作的&#xff0c;即直接在hello这个内存空间把hello拼接为helloworld。
StringBuilder s1 &#61; new StringBuilder("hello");
s1.append("world");
sout(s1) ->"helloword"
转为String&#xff1a;
s1.toString();






 京公网安备 11010802041100号
京公网安备 11010802041100号