1. AirFlow介绍【了解】
- 功能、特点
- 架构角色、安装部署
2. **AirFlow使用【掌握】**
- 核心:调度脚本【Python | Shell】
- 定时调度:Linux Crontab表达式
- 邮件告警:配置
3. 回顾Spark核心概念
- 存储:安全性、高效性
- 计算:使用【API:类、方法】、原理【资源使用】
- 零碎:采集、调度、选举、可视化
- Spark概念
- 分布式资源:Master | ResourceManager、Worker | NodeManager
- 分布式程序:Driver 、Executor、Task
- 原理性概念:Job、DAG、Stage
目标:回顾任务流调度的需求及常用工具
路径
- step1:需求
- step2:常用工具
实施
需求
- 相同的业务线,有不同的需求会有多个程序来实现,这多个程序共同完成的需求,组合在一起就是工作流或者叫做任务流
- 基于工作流来实现任务流的自动化运行
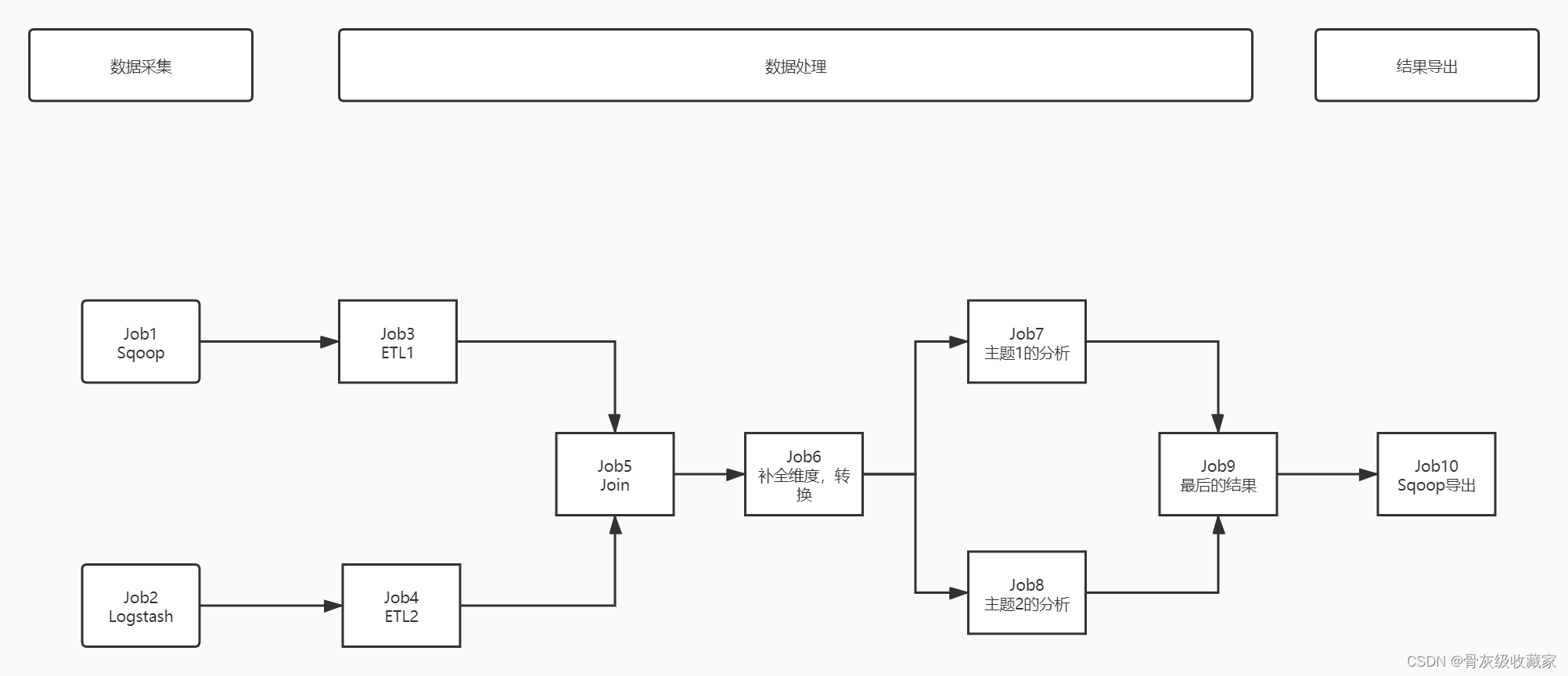
- 需求1:基于时间的任务运行
- job1和job2是每天0点以后自动运行
- 需求2:基于运行依赖关系的任务运行
- job3必须等待job1运行成功才能运行
- job5必须等待job3和job4都运行成功才能运行
- 调度类型
定时调度:基于某种时间的规律进行调度运行
- 调度工作流
依赖调度:基于某种依赖关系进行调度运行
- 工作流中的程序的依赖关系
常用工具
- Oozie:Cloudera公司研发,功能强大,依赖于MR实现分布式,集成Hue开发使用非常方便
- 传统开发:xml文件
```xml
- 现在开发:Hue通过图形化界面自主编辑DAG
- 场景:CDH大数据平台
- Azkaban:LinkedIn公司研发,界面友好、插件支持丰富、自主分布式,可以使用properties或者JSON开发
- 开发properties文件,压缩成zip压缩包
```properties
name='appname2'
type=command
dependencies=appname1
comman='sh xxxx.sh'
```
- 上传到web界面中
- 场景:Apache平台
- AirFlow:Airbnb公司研发,自主分布式、Python语言开发和交互,应用场景更加丰富
- 开发Python文件
```python# step1:导包# step2:函数调用```
- 提交运行
- 场景:整个数据平台全部基于Python开发
- DolphinScheduler:易观公司研发,国产开源产品,高可靠高扩展、简单易用
目标:了解AirFlow的功能特点及应用场景
路径
- step1:背景
- step2:设计
- step3:功能
- step4:特点
- step5:应用
实施

起源
- 2014年,Airbnb创造了一套工作流调度系统:Airflow,用来替他们完成业务中复杂的ETL处理。从清洗,到拼接,只用设置好一套Airflow的流程图。
- 2016年开源到了Apache基金会。
- 2019年成为了Apache基金会的顶级项目:http://airflow.apache.org/。
- **设计**:利用Python的可移植性和通用性,快速的构建的任务流调度平台
- **功能**:基于Python实现依赖调度、定时调度
特点
- 分布式任务调度:允许一个工作流的Task在多台worker上同时执行
- DAG任务依赖:以有向无环图的方式构建任务依赖关系
- Task原子性:工作流上每个task都是原子可重试的,一个工作流某个环节的task失败可自动或手动进行重试
- 自主定制性:可以基于代码构造任何你需要调度的任务或者处理工具
- 优点:灵活性好
- 缺点:开发复杂
应用
- 基于Python开发背景下的系统建议使用
目标:了解AirFlow的工具部署及管理
路径
- step1:安装部署
- step2:启动测试
- step3:关闭
实施
安装部署
- 自行安装:《参考附录一》
- 放弃安装:请将虚拟机快照恢复到《AirFlow安装完成》
启动测试


- 测试网络端口
- Airflow Web UI:`node1:8085`
- 用户名密码:admin
- Celery Web UI:`node1:5555`
目标:了解AirFlow的架构组件
路径
- step1:架构
- step2:组件
实施
架构

- Client:开发AirFlow调度的程序的客户端,用于开发AirFlow的Python程序
- Master:分布式架构中的主节点,负责运行WebServer和Scheduler
- Worker:负责运行Execution执行提交的工作流中的Task
组件

```A scheduler, which handles both triggering scheduled workflows, and submitting Tasks to the executor to run.An executor, which handles running tasks. In the default Airflow installation, this runs everything inside the scheduler, but most production-suitable executors actually push task execution out to workers.A webserver, which presents a handy user interface to inspect, trigger and debug the behaviour of DAGs and tasks.A folder of DAG files, read by the scheduler and executor (and any workers the executor has)A metadata database, used by the scheduler, executor and webserver to store state.```
- WebServer:提供交互界面和监控,让开发者调试和监控所有Task的运行
- Scheduler:负责解析和调度Task任务提交到Execution中运行
- Executor:执行组件,负责运行Scheduler分配的Task,运行在Worker中
- DAG Directory:DAG程序的目录,将自己开发的程序放入这个目录,AirFlow的WebServer和Scheduler会自动读取
- airflow将所有程序放在一个目录中
- 自动检测这个目录有么有新的程序
- MetaData DataBase:AirFlow的元数据存储数据库,记录所有DAG程序的信息
目标:掌握AirFlow的开发规则
路径
- step1:开发Python调度程序
- step2:提交Python调度程序
实施
- 官方文档
- 概念:http://airflow.apache.org/docs/apache-airflow/stable/concepts/index.html
- 示例:http://airflow.apache.org/docs/apache-airflow/stable/tutorial.html
开发Python调度程序
- 开发一个Python程序,程序文件中需要包含以下几个部分
- 注意:该文件的运行不支持utf8编码,**不能写中文**
step1:导包
# 必选:导入airflow的DAG工作流from airflow import DAG# 必选:导入具体的TaskOperator类型from airflow.operators.bash import BashOperator# 可选:导入定时工具的包from airflow.utils.dates import days_ago```
step2:定义DAG及配置
# 当前工作流的基础配置default_args = {# 当前工作流的所有者'owner': 'airflow',# 当前工作流的邮件接受者邮箱'email': ['airflow@example.com'],# 工作流失败是否发送邮件告警'email_on_failure': True,# 工作流重试是否发送邮件告警'email_on_retry': True,# 重试次数'retries': 2,# 重试间隔时间'retry_delay': timedelta(minutes=1),}# 定义当前工作流的DAG对象dagName = DAG(# 当前工作流的名称,唯一id'airflow_name',# 使用的参数配置default_args=default_args,# 当前工作流的描述description='first airflow task DAG',# 当前工作流的调度周期:定时调度【可选】schedule_interval=timedelta(days=1),# 工作流开始调度的时间start_date=days_ago(1),# 当前工作流属于哪个组tags=['itcast_bash'],)```
- 构建一个DAG工作流的实例和配置
step3:定义Tasks
- Task类型:http://airflow.apache.org/docs/apache-airflow/stable/concepts/operators.html
- 常用
- [`BashOperator`](http://airflow.apache.org/docs/apache-airflow/stable/_api/airflow/operators/bash/index.html#airflow.operators.bash.BashOperator) - executes a bash command
- 执行Linux命令
- [`PythonOperator`](http://airflow.apache.org/docs/apache-airflow/stable/_api/airflow/operators/python/index.html#airflow.operators.python.PythonOperator) - calls an arbitrary Python function
- 执行Python代码
- [`EmailOperator`](http://airflow.apache.org/docs/apache-airflow/stable/_api/airflow/operators/email/index.html#airflow.operators.email.EmailOperator) - sends an email
- 发送邮件的
- 其他
- [`MySqlOperator`](http://airflow.apache.org/docs/apache-airflow-providers-mysql/stable/_api/airflow/providers/mysql/operators/mysql/index.html#airflow.providers.mysql.operators.mysql.MySqlOperator)
- [`PostgresOperator`](http://airflow.apache.org/docs/apache-airflow-providers-postgres/stable/_api/airflow/providers/postgres/operators/postgres/index.html#airflow.providers.postgres.operators.postgres.PostgresOperator)
- [`MsSqlOperator`](http://airflow.apache.org/docs/apache-airflow-providers-microsoft-mssql/stable/_api/airflow/providers/microsoft/mssql/operators/mssql/index.html#airflow.providers.microsoft.mssql.operators.mssql.MsSqlOperator)
- [`OracleOperator`](http://airflow.apache.org/docs/apache-airflow-providers-oracle/stable/_api/airflow/providers/oracle/operators/oracle/index.html#airflow.providers.oracle.operators.oracle.OracleOperator)
- [`JdbcOperator`](http://airflow.apache.org/docs/apache-airflow-providers-jdbc/stable/_api/airflow/providers/jdbc/operators/jdbc/index.html#airflow.providers.jdbc.operators.jdbc.JdbcOperator)
- [`DockerOperator`](http://airflow.apache.org/docs/apache-airflow-providers-docker/stable/_api/airflow/providers/docker/operators/docker/index.html#airflow.providers.docker.operators.docker.DockerOperator)
- [`HiveOperator`](http://airflow.apache.org/docs/apache-airflow-providers-apache-hive/stable/_api/airflow/providers/apache/hive/operators/hive/index.html#airflow.providers.apache.hive.operators.hive.HiveOperator)
- [`PrestoToMySqlOperator`](http://airflow.apache.org/docs/apache-airflow-providers-mysql/stable/_api/airflow/providers/mysql/transfers/presto_to_mysql/index.html#airflow.providers.mysql.transfers.presto_to_mysql.PrestoToMySqlOperator)
- ……
- BashOperator:定义一个Shell命令的Task
# 导入BashOperatorfrom airflow.operators.bash import BashOperator# 定义一个Task的对象t1 = BashOperator(# 指定唯一的Task的名称task_id='first_bashoperator_task',# 指定具体要执行的Linux命令bash_command='echo "hello airflow"',# 指定属于哪个DAG对象dag=dagName)```
- PythonOperator:定义一个Python代码的Task
# 导入PythonOperatorfrom airflow.operators.python import PythonOperator# 定义需要执行的代码逻辑def sayHello():print("this is a programe")#定义一个Task对象t2 = PythonOperator(# 指定唯一的Task的名称task_id='first_pyoperator_task',# 指定调用哪个Python函数python_callable=sayHello,# 指定属于哪个DAG对象dag=dagName)```
step4:运行Task并指定依赖关系
- 定义Task
Task1:runme_0
Task2:runme_1
Task3:runme_2
Task4:run_after_loop
Task5:also_run_this
Task6:this_will_skip
Task7:run_this_last
- 需求
- Task1、Task2、Task3并行运行,结束以后运行Task4
- Task4、Task5、Task6并行运行,结束以后运行Task7

- 代码
task1 >> task4task2 >> task4task3 >> task4task4 >> task7task5 >> task7task6 >> task7```
- 如果只有一个Task,只要直接写上Task对象名称即可
```task1```
提交Python调度程序
- 哪种提交都需要等待一段时间
- 自动提交:需要等待自动检测
- 将开发好的程序放入AirFlow的DAG Directory目录中
- 默认路径为:/root/airflow/dags
- 手动提交:手动运行文件让airflow监听加载
python xxxx.py
- 调度状态
- No status (scheduler created empty task instance):调度任务已创建,还未产生任务实例
- Scheduled (scheduler determined task instance needs to run):调度任务已生成任务实例,待运行
- Queued (scheduler sent task to executor to run on the queue):调度任务开始在executor执行前,在队列中
- Running (worker picked up a task and is now running it):任务在worker节点上执行中
- Success (task completed):任务执行成功完成
目标:实现Shell命令的调度测试
实施
需求:使用BashOperator调度执行一条Linux命令
代码
- 创建
# 默认的Airflow自动检测工作流程序的文件的目录mkdir -p /root/airflow/dagscd /root/airflow/dagsvim first_bash_operator.py
- 开发
# importfrom airflow import DAGfrom airflow.operators.bash import BashOperatorfrom airflow.utils.dates import days_agofrom datetime import timedelta# define argsdefault_args = {'owner': 'airflow','email': ['airflow@example.com'],'email_on_failure': True,'email_on_retry': True,'retries': 1,'retry_delay': timedelta(minutes=1),}# define dagdag = DAG('first_airflow_dag',default_args=default_args,description='first airflow task DAG',schedule_interval=timedelta(days=1),start_date=days_ago(1),tags=['itcast_bash'],)# define task1run_bash_task = BashOperator(task_id='first_bashoperator_task',bash_command='echo "hello airflow"',dag=dag,)# run the taskrun_bash_task
- 工作中使用bashOperator
bash_command='sh xxxx.sh'
xxxx.sh:根据需求
- Linux命令
- hive -f
- spark-sql -f
- spark-submit python | jar
提交
python first_bash_operator.py
查看

执行

目标:实现AirFlow的依赖调度测试
实施
需求:使用BashOperator调度执行多个Task,并构建依赖关系
代码
- 创建
cd /root/airflow/dagsvim second_bash_operator.py```
- 开发
# importfrom datetime import timedeltafrom airflow import DAGfrom airflow.operators.bash import BashOperatorfrom airflow.utils.dates import days_ago# define argsdefault_args = {'owner': 'airflow','email': ['airflow@example.com'],'email_on_failure': True,'email_on_retry': True,'retries': 1,'retry_delay': timedelta(minutes=1),}# define dagdag = DAG('second_airflow_dag',default_args=default_args,description='first airflow task DAG',schedule_interval=timedelta(days=1),start_date=days_ago(1),tags=['itcast_bash'],)# define task1say_hello_task = BashOperator(task_id='say_hello_task',bash_command='echo "start task"',dag=dag,)# define task2print_date_format_task2 = BashOperator(task_id='print_date_format_task2',bash_command='date +"%F %T"',dag=dag,)# define task3print_date_format_task3 = BashOperator(task_id='print_date_format_task3',bash_command='date +"%F %T"',dag=dag,)# define task4end_task4 = BashOperator(task_id='end_task',bash_command='echo "end task"',dag=dag,)say_hello_task >> [print_date_format_task2,print_date_format_task3] >> end_task4
提交
python second_bash_operator.py
查看

目标:实现Python代码的调度测试
实施
需求:调度Python代码Task的运行
代码
- 创建
cd /root/airflow/dagsvim python_etl_airflow.py
- 开发
# import packagefrom airflow import DAGfrom airflow.operators.python import PythonOperatorfrom airflow.utils.dates import days_agoimport json# define argsdefault_args = {'owner': 'airflow',}# define the dagwith DAG('python_etl_dag',default_args=default_args,description='DATA ETL DAG',schedule_interval=None,start_date=days_ago(2),tags=['itcast'],) as dag:# function1def extract(**kwargs):ti = kwargs['ti']data_string = '{"1001": 301.27, "1002": 433.21, "1003": 502.22, "1004": 606.65, "1005": 777.03}'ti.xcom_push('order_data', data_string)# function2def transform(**kwargs):ti = kwargs['ti']extract_data_string = ti.xcom_pull(task_ids='extract', key='order_data')order_data = json.loads(extract_data_string)total_order_value = 0for value in order_data.values():total_order_value += valuetotal_value = {"total_order_value": total_order_value}total_value_json_string = json.dumps(total_value)ti.xcom_push('total_order_value', total_value_json_string)# function3def load(**kwargs):ti = kwargs['ti']total_value_string = ti.xcom_pull(task_ids='transform', key='total_order_value')total_order_value = json.loads(total_value_string)print(total_order_value)# task1extract_task = PythonOperator(task_id='extract',python_callable=extract,)extract_task.doc_md = """\#### Extract taskA simple Extract task to get data ready for the rest of the data pipeline.In this case, getting data is simulated by reading from a hardcoded JSON string.This data is then put into xcom, so that it can be processed by the next task."""# task2transform_task = PythonOperator(task_id='transform',python_callable=transform,)transform_task.doc_md = """\#### Transform taskA simple Transform task which takes in the collection of order data from xcomand computes the total order value.This computed value is then put into xcom, so that it can be processed by the next task."""# task3load_task = PythonOperator(task_id='load',python_callable=load,)load_task.doc_md = """\#### Load taskA simple Load task which takes in the result of the Transform task, by reading itfrom xcom and instead of saving it to end user review, just prints it out."""# runextract_task >> transform_task >> load_task
提交
python python_etl_airflow.py
查看











 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有 