大家好,我是来自盒子科技研发部支付线刘恒,目前主要是负责公司的一个聚合支付系统的研发工作。今天主要是讲一下我们这个支付系统从2016年年初到现在,一个整个的技术演变。
首先我会从那三个方向,第一个就是聚合支付的介绍,聚合支付在我们公司它承担一个什么样的地位,还有一个就是在我们前面有什么样的使用场景。
第二个就是从公司开始做聚合支付最开始的版本是什么样子的?
还有一个是在1.0版本之上,我们做了什么样的优化,然后达到了现在也是什么样的架构?
基本介绍
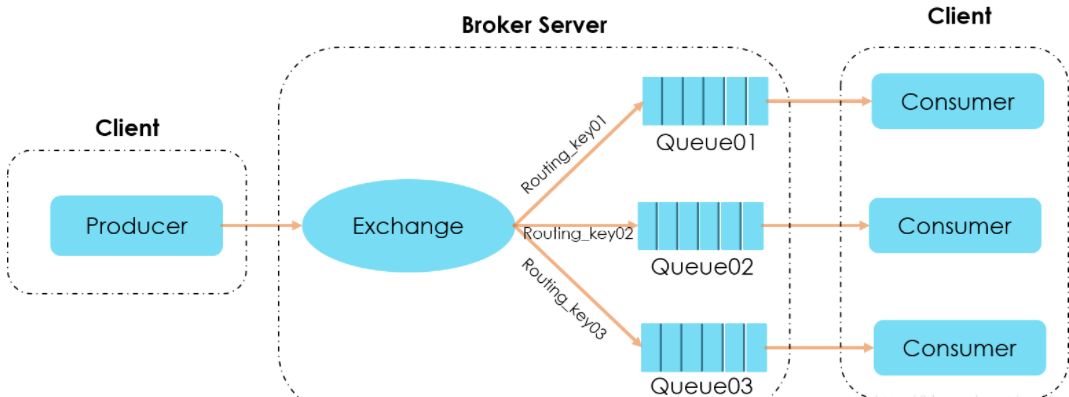
首先从第一个主题讲什么是聚合支付,聚合支付主要是就是一个将所有的第三方支付,就是通过借助形式融合在一起,就相当于对接一个支付消费接口的话,就可以使用各种支付的场景,就比如说各位有可能去那种超市便利店去买东西,贴着一个码,码上有什么微信支付,支付宝支付,还有一个京东QQ各种支付,然后我们公司也有一个,就是一个好哒,相当于这个用户就是图上两个男生,然后扫橙色的那个二维码,所以我们公司做了一个好哒一个牌。
它主要是针对一个微小商户进行一个收款工具,让商家他那边会有一个好哒的商务通,第一个可以实时的收听语音报告,就是说当前用户付款多少钱,第二个就是他可以去关注他的一个营业额,他的账单。

还有一个产品就是我们公司的一个pos机。
这个主要是一款生态pos,它里面不仅继承了我们一个我们这个具备支付系统提供的服务,就比如微信支付宝,它们还集成了一个刷卡的功能,就是磁条卡芯片卡,还有各种支付方式。然后这次我们那个巨额支付,主要是涉及到一个交易流,就不涉及到资金流,资金流是其他项目组他们负责的,我们这边只涉及到一个交易流。
背景
好,进入一个背景,背景第一个就是工期短,基本上所有的项目都会遇到,天天都在赶工程。

我们也是从2016年过年前一周,然后忽然被拉个群就是让做一个系统,说有个项目要做一做就拉进去了,然后当时让一周上线,但是当时就对这个一个业务也不熟,不知道聚合支付到底做什么事情,它的支付流程是什么样的?虽然说之前做过支付相关业务,但是每个公司支付业务是完全不一样的。
当时做一个微信支付宝,微信,APP ID是什么东西还不知道,所以说就在这种情况下开始搞,还有就是一个当时的交易量,当时的交易量是只有前端的一两个产品马上用,每天的交易笔数也很小,就几千笔。
第三个就是人员的缺乏,因为当时就做系统研发,只有我和另外一个同事。另外同事来公司没多久,我们俩怎么说,时间短,业务也不熟,然后就开始搞。就在这种背景下,我们就搭建了第一套系统架构,就在那个圈中的虚线圈住的,我就负责一个交易前置,另一个同事呢他就负责一个交易网关,当时就直接操作DB没有做任何的其他的优化。
架构图
首先交易前置就是负责一个核心的链路进行处理,它主要是负责一个商户流水有记录,还有一个对接的各个支撑系统。比如说风控,风控就是我们公司单笔单日的一个额度限制,还有商户的一个黑名单,就有没有涉及到,因为被用户大量投诉这种的。还有一个欺诈行为识别,就是做一个风险控制。
还有对接一个路由系统,路由系统它会去通过设定一个固定的规则和一个限额等条件去找一个合适的渠道。因为这样的话,第一个是提交成功率,因为我们那个渠道可能会切来切去一些去我们就会通过这个路由系统来进行控制,控制就是某个时间段某一天走哪个渠道,从而降低成本。最后就是一个家庭网关,家庭网关就是负责一个支付渠道霸王的转换。
还有一个协议,还有一个数据加密签名验证,进行一个状态映射,当时就做一个简单的架构,两个人就是这样,因为在这种架构下,第一个开发比较快,直接拿那个需求直接改代码,直接上线测试直接测,用完了就两个包装上去就OK了。所以这时候也解决了,当时是2016年3月份4月份就上线了,也很快。后来就是在经过了三四个月交易量比较猛增的情况下,就发现这个系统感觉各种瓶颈就出来了。
问题暴露

第一个就是渠道的隔离,因为当时对接了几个渠道,特别是我有渠道不稳定的话,它就是比如说资源不可用,还有就是一个网络相关的问题,导致超时,这样话它就会把我们所有的渠道交易全部影响到,就造成一个相当于节点反应,导致整个服务交易链动就不可用。这是一个渠道个例。
特别这个是比较重要的,因为当初的是,每个周末别人都可以在家好好休息,但是我们支付研发不行,就每天到家都是随时看手机,因为说不定哪个渠道就出问题了,立马要处理。而且系统哪边挂了之后立马要赶紧联系。所以说这个渠道隔离放在第一位首要的。
第二个就是一个接口膨胀,特别涉及到某些相似的业务,就比如说那个消费接口,消费了,撤销了,通胀了,就每个业务类型都有这几个接口,当时业务就膨胀,接口比较多,也不好维护,开发每次来个需求都要去考虑,到底是改哪个接口,要不要都改?所以说当时这个也比较厉害。
还有就是一个动态的扩容。因为特别设了我们这个聚合支付很多交易都是易付的,就用户他下完单,然后我们会立即返回就下单成功,或者下单失败,但是这个交易有没有消费成功,消费失败,我们是需要设置定时的任务去查询,把查过来。
但是当时是基于一个就是很多系统都会用到开源的一个定时调度框架,但是它对那个分布式环境下支持的话,虽然支持,但是就不是我们想要的,而且比较臃肿。所以我们这个扩容的话也是势在必行的,特别是等到交易量大的时候,因为定时调度,它是需要去定时,定点,定量的去拉取一批订单去同步的,如果拉取的交流太多,你内存直接爆了,拉取太少,有很多交易都到执行。所以这个是比较重要的,也是迫在眉睫的。
还有就是一个业务的耦合,当时是交易前置,里面所有查询和任务作业和支付等核心业务全部是在一个节点上。
但是这样的话就相当于我每次改一个就是边缘的业务都去动到核心的,就每次就会影响到特别上线的时候。这样的话就相当于对用户的体验又不好,本来人家就到付款环节提示人家付款失败,人家肯定就是不高兴,慢慢人就不用了。
还有一个就是一个配置分散,这就是最传统就是每次那个节点配用电都是放在我们一个节点上面,在一个根路径下。这样的话就像每次去改动都需要给运维让他们手动改。
第一个是增加风险,第二个就是相当于不好维护。我们每次如果改动的话,每个建筑都要改,就很麻烦,有重复性的工作。所以说这几个是主要的一个不好的地方,有遇到一个问题就需要尽快要改造。
2.0版本
所以说在这个前提下,我们就去设计了一个2.0。当初设计2.0有几个大的方向。
第一个就是稳定。因为优化,反正已经有那个1.0版本的经验了,2.0怎么说,第一首要的就是怎么稳定?
第二个就是一个快速,就是用户下完单怎么能够快速的把状态给查回来。
第三个就是一个低耦合,就是以后再改任何的业务的代码时候,就千万不能去动核心的,或者尽量少动核心的,对核心链路是千万不要触碰。
还有就是这块,就是我们在这个过程中也是试了很多种方案,要么是第一个就是大了不好维护,你写完的话可能只有自己懂,不好维护,要么是你的性能跟不上去。所以我们也尝试了各种方案,然后就是达到一个这种系统架构。
系统架构图

首先就是我们把那个就是三条线,上面绿色的,和中间那个红色的和最下面一条橙色的。绿色的就是我们把交易核心、交易网关就单独拉条线。任务作业和那个查询网关单独拉条线。这两条线通过MQ进行解耦,然后我们再单独列出来一个查询的服务,这样的话,对前面那仅仅是提供一个流水查询功能而已。
就所有支付核心的全部在第一条线,就相当于这个,就业务方案如果它发起一笔消费,首先是在支付核心,然后做流水,初始化流水,进入流水。然后这边会调用风控,调用路由,选择通道,风险识别,然后再解锁支付网关通道。
这块如果是,如果该笔交易的话,如果是那种需要查询的,没有状态明确的,我们就会发MQ给这个,发消息给MQ集群。他们有任何作业它会去监听,它拿到这个消息之后,它就会放缓存,然后在后面翻取任务,再去查询,同步状态。
主要在前端,因为前端你这边是义务告诉他,你是受理成功,这边的业务方案在开始查询,他觉得这我们仅仅是查询,缓存,然后再传送带。如果是好像没有的话,再穿插到异步进行查询。
进行这样一个优化,就是我们在那个这个版本也进行了一个全面对接的一个配置中心。这配置中心就相当于我们可以把所有的一个配置文件,从外部接电话来进行统一的管理,统一的维护。
还有就是这时候也介入,全面介入一个监控中心和报警中心,就相当于取到一个成功率,还有取到一个超时,各种异常情况下都可以得到很好的监控,就可以发短信,立马可以收到,立马就可以知道当前的渠道什么问题。
交易前置优化

还有前置优化,我们首先从水平方向上进一个,第一个一层就是一个结构层,第二层的话就是将共一个共性的接口交易业务接口全部统一。比如说下单,所有的业务,不管你微信支付,还有其他的全部归为下单。然后呢你们具体的业务,然后通过一个serviceid就接受一个参数进行识别,然后进入到一个服务层,我们全部把贡献的逻辑,就比如一个消费接口,消费接口首先进来,第一个步肯定是教育参数了,第二步就是去一个初始化流水。第三步就是去风险识别风控系统。第四步就是渠道选择了路由系统。下一步就是调用支付网关进行消费,后面就是一个交易状态,一个变更。
相当于这种共性逻辑,也就是核心的这种逻辑全部抽离出来,然后进行一个统一的一个下沉,作为底层服务,上层业务全部通过serviceid就配计划实现,这样的话尽量去少改动核心业务逻辑。
好像这部分我们加入一个缓存,特别是随着交易量的增长,因为之前特别是在第一代的时候,里面很多业务查询都是直接操作DB了,对DB有很大的性能影响。所以我们就是在DB之上将所有消费交易信息全部缓存,后续所有的操作查询和更新全部操作缓存层主要为了提升了服务的性能。
交易前置业务拆分

还进行随时垂直拆分,主要是进行了一个,第一个就是交通核心交易已经独立开来,因为合约交易的话,他就负责一个支付的一个核心电路,这个电路是用户感知最明显的。只要你支付下单消费失败,用户立马能知道,立马就会投诉或者打电话给客服,还有个退款的各种业务。
下一步就是一个任务的作业,做作业就是将那种处理中的交易,全部放在这个系统。这两个系统进行,它之间将进行解耦,然后调用查询文化进行状态同步,查询服务这个简单的,仅仅是对我们公司内部提供一个交易状态的一个查询,下罚单来查,内部我跟通道这些,系统通道之间的一个状态,我们全部通过任务作业他自己他来处理。
现在可以分为三段,三段是完全没有什么结果的,有什么关联,这样的话有我我想升级,我想比如说某个业务需要在查询服务做一些什么特殊的操作,我今天改过这个服务,对其他没有任何的影响。
任务作业双队列

下面讲一下任何作业系统一个查询策略,目前第一个就是内存队列。内存队列我们是基于DelayQueue做一个它的延迟对立码,就他有一个关机时间,过去时间转到它有自动通过这个方法,就弹出来,然后我们就可以做一些后续的操作。还有一个就是你每次往这个队列放的时候,就通过我们通过制定算法策略,就是比如说延迟十秒,间隔五秒,这样我来放,或者是有很多银行都是那种二的N次方进行查询,然后这定是队列根据当前设定的一个策略算法自动进行快速的单笔查询。
还有一个就是缓存队列,缓存队列它也是基于我们公司一个缓存平台,结合那个Elastie-job叫这是一个开源的一个分布式框架,然后进行状态同步。这个主要是解决了批量的用户,付款又比较慢的。因为这个的话,内存队列它是用户支付比较快的。比如说我在两分钟之内就有付款,这样的话,我可以通过内存队列快速把他过来,像这样的话,用户和商户之间就可以实时立马看到交易结果。
但是如果用户付款比较慢,或者说通道稍微有点状态延迟,这样的话,我可以通过我这个缓存队列也把它同步回来,其实有点延迟。他指定的就是批量。还有一个DB,DB的话主要也是结合Elastie-job进行执行的,当然它主要是用于人工干预的,特别是在通道延迟比较厉害的情况下,因为这两个对列,它是做了执行最近几分钟的,然后缓存队列它只是执行可能是最近一个小时的,因为它不会存放太长时间。
还有这个DB,就是如果这个渠道它状态延迟的话,就比如说两个小时,三个小时,然后我就提供进入了一个入口,通过助理来把状态全部都改回来,这个主要是把当天的交易当天处理掉,就防止场馆用户大量投诉。
缓存队列设计

好,下面就是缓存队列的差距,这个也是我们基于用那个对接公司平台,然后选择那个他们数据结构,第一个就是zset的集合,还有一个string。
它的这个订单,就人工作业它收到一个消息,首先把这个订单,我先讲一下大致思想,第一个就是通过zset的集合存放一个订单,订单号,进行订单号,string存放一个订单的详情,然后以它的效果,它主要是执行一个分片任务。这个分片任务就是使用的开源的第三方的,它的默认,我用那个默认分配策略就是平均算法,比如算法的话相当于从零到九分配十个片,现在每个机器都会得到当前应该指定哪一片,就分片项。
这样的话相当于比如说我现在有三个机器的话,就相当于每台机器都可以平均一下,等一下从零到九,十个数字平均下,每个机器得到比如说零到三,四到六的那种了,这样的话现在每台机器它拿到当前的分辨像去就那个有序集合里面,比如说我当A机器拿到一个分辨像是零,这样的话拿到一个,到那个找到K0这个队列,然后通过一个时间范围,我们用的是那个时间戳,这么通过时间戳,然后一个范围,然后取到一批订单号,然后这边循环,然后通过get,再去取那个详情,把订单的详情数据取出来,然后再去调一个渠道,进行一个状态的同步。
交易网关优化

下来就是一个交易网关,交易网关就是刚才那个在1.0版本也说了一个问题,就是渠道隔离,渠道隔离我们在这一层就是重点做了优化,我们就采用了一个Hystrix。
因为特别是在高并发的情况下,所依赖通道,比如说它这个网络。网络不可用,或者系统资源不可用,或者他正在升级,这时候它的一个响应时间是达到延迟的,可能有耗时60秒或者更多。
如果我这边如果不通过经营渠道隔离,不促进浓缩处理的话,相当于不立即想把我一个工作进程全部占满。这样的话现在我资源也是不可用的。所以我这边这次我们这次重点经营渠道隔离的优化。下来就是一个将查询网络独立开来,因为查询网关特别涉及到这种义务的交易。
因为聚合支付很多都是那种只是下单,下单之后后面的结果都是靠那个用户付款有快慢的,这时候我们都需要可能如果用户付款都比较慢,就可能在这段时间之内积累了大量的订单需要进行查询。这样的查询它特别是很高的,目前的话我们现在是峰值的话应该是700多。不到800应该。所以单独把那个查询网点独立开来,提升一个系统的稳定性,将那个和新的交易还是也独立开来。
下个就是通道商户缓存,因为商务通道上晚上的话基本都属于静态信息的,就是每次增加一个商户的话,往渠道那边进行一个开通,它通常会分配一个通道一个密钥,这个密钥的是跟商户绑定的,这话就相当于密钥就都是不会改,所以说我们把这个信息全部缓存起来,但是这个缓存呢一定要设定有效期,因为商户的话有可能他今天用后面一直不用。
交易网关渠道容错

这个是那个渠道的容错。有句话叫说千里之堤毁于蚁穴,说的就是这个,它不是一个渠道,比如说我们有二楼通道,到三楼通道的话,因为每个通道稳定性都是不一样的,所以说你在依赖服务不可用的情况下,你如何提供一种通过一种技术手段提供一种保证业务柔性可用,提供一种向上提供这个有损服务的话,也是有必要的,很有必要的。
所以说我们在这个时候,我们就会采用刚才所说的Hystrix进一个隔离,Hystrix它是通过一个命令模式,将每个这种支付业务全部定义一个线程池,把这个线程池放到一个里面,然后每次每个业务来时的时候使用对应一个自己的一个线程池。有的人会说线程池是很耗资源的,但是其实这个默认的话,就每次设定每个渠道业务的话,现在只是很小,相当于默认不计的。
还有就是一个合理的超时时间设置,就是尽量既然这里面每一个渠道这边都设置一个合理的超时时间,就是默认的话,就是如果是比如说你默认60秒有可能,但正常情况下,可能就是耗时只有10秒钟,但如果排设60秒,正好万一他哪天或者有一段时间他能出现问题的话就耗时很慢的话,你这个整个链路其实都是很慢,就把那个线程打满,你正常的已经进不来了。所以说这个的话尽量要尽量是去设立一个合理的操作时间。
通过这种的话。目前我们通过这种线程隔离的话,以前的话是没有隔离模式,周末是不敢出门的,但是自从这边是隔离之后,我们现在是基本上可以回家睡大头觉,就不用管,每次告警的话,每次哪个通道告警,我们直接就是通知一下那个渠道,说你们哪个交易类型出问题了,就可以精确地定位。

就是一个刚才所说的Hystrix一个交易的一个线程使用情况,线程监控。比如这个这个交易类型,一个资源的一个使用情况,比如它有一个那个耗时一个分布,比如说90%多少超一个耗时多长时间,然后99%都可以立马可以看出来哪个渠道。
它一个性能比较好,还有就是可以通过这个图形就特别这个圆圈。当这个渠道进行一个熔断的时候,会自动这边会变成红色,可以立马知道这个渠道这个交易类型出问题,就可以达到针对性的一个提示。
刚才说这个的话题相当于如果这个因为之前的话是如果我们自己为什么我们用一个Hystrix,如果我们自己用线程池的话,首先第一点就是如果这个线程有问题,渠道耗时比较慢的话,首先我们是只能等,只能等同渠道那边耗,然后我们线程资源得到释放,后面的交易层进来,我们自己用的自己写的话。
如果我们用Hystrix的话,它会有一种那种有策略。就是如果渠道比如在十秒钟,你有50%的交易都是不可用的,都是超时的。这样它会进入一个半开的状态,半开状态就是如果你这时候下面会把50%交易全部打掉,只剩下50%进行渠道进行上送。如果你的渠道继续不可用,它会进一步把这个阀值,后面只有少量交易去渠道进行尝试。这样相当于如果去到那边交易陆续恢复,我们这边成功率慢慢提高,提高之后这个阀值就慢慢降低,后面就陆续全部恢复,就相当于做一个自动的一个恢复功能。不用说我们自己写一个,然后一直在那等待。

这块下一个就是一个业务监控吧在我们2.0之后我们是全面对接一个我们公司的一个监控平台,监控平台我们可以实时的监控,比如说哪个区就是我们哪个节点耗时比较慢,通过百分比的形式,比如说你50%耗用多长时间,第一个是做一个监控,第二个是可以做一个优化。
就我们可以每天早上来就去做一下巡检,看昨天哪个系统哪个节点它有个耗时比较慢。还有一个就是我们可以做一个成功率的监控。就如果比如说第一条,就是我们这个总的比数下面条就是一个成功数,像这个失败数,立马可以通过一个成功率,就可以立马报警出来,哪个渠道有问题,哪个成功率下降,尽管它是它的资源是可以用的,但是它的成功率是下降的,这也是资源是有问题的。
还有就是错误码监控,错误码监控的话就相当于可以通过一个排行榜,就哪个渠道它的错误码出现的次数比较多,这块也是一种异常告警。
说现在是通过一种多种维度进行了监控。好,就是我们可以通过我们第二天发一个邮件发一个巡检报告,包括邮件哪一个通道渠道,它一个支付比数比较低,或者它一个支付的一个成功率,比如正常情况下,它是一个失败笔数只有几十笔100笔,但忽然某一天它的失败比数很高,这样我们可以第二天也可以相当于事后再去看一看系统是不是哪地方有瓶颈。
还是它的一个错误码数,就是比如说我们可以监控它一个,比如说把一个非法状态就非法,我们可以立马知道哪个商铺相当于做一个,比如说如果他是那种被提到风控的话,我们可以立马第二天把它拿出来做一个相应的处理,做一个适合处理,相对作用多渠道的一个监控。
其实上面这地方就是系统架构图,这个的话就相当于在通过这三条线接受之后,以及加入各种监控措施,目前的话在2017年的话是从一线上线到现在是没有出现任何故障,任何技术故障和业务故障的,就能保证系统的一个平稳运行。而且如果是抛开那种渠道,它的异常的话,它一个是代失败率的话,基本上现在是成功率基本上可以达到百分之百,没有任何异常。
而且它如果基本上现在这个系统很长时间没有上线,都没更新,都没有管它,除非渠道异常的话,我们就给渠道发个邮件发个消息提醒他们系统异常,其他我们是不做任何处理。
所以我们下一步主要是最后一步。下一步我们到底该做什么?
下一步该做什么?
所以说上面有做了那么多,但是我觉得还少了一点,就是我们一个全链路的监控。我们现在链路监控只是从前端到后端有一个请求的跟踪号,但是这个都分散在我们业务日志里面的。所以说我们下一步就准备做一个全链路的监控,就相当于把每一个每笔交易,它具体在哪个时间点在哪个机器上,然后在哪个渠道?做了什么事情,然后它状态做的什么变更,然后全部给它做一个记录,通过一个外部界面化的提供出来。
第一个是提供开发,开发可以做,第二天可以去将某种异常的交易进行一个去查询跟踪。
第二个是提供我们那个清算组,因为他们可能会每天处理一些还款之类的,他们也可以通过这种去判断一下这个渠道给我们是到底什么状态,然后它那边对账单里面显示是什么状态,然后清算组可以立马知道到底是我们的问题还是清算组的问题。
还有一个就是客服,客户就说有商户打电话说我的交易不了,把商号给他,是不是客户就可以通过商务号露出最近一笔交易,看跟踪一下在哪个地方进行有问题。这块就可以把我们所有的一一个闭环全部给打通,这样的话可以释放的一个通过。就必须让开发人员去登录哪个节点上去看日志这种问题。
还有就是一个智能路由,因为现在我们的商铺就是在各个渠道,特别是需要多20多个30多个渠道的话,可能会受到一个渠道的一个切换,就比如说今天在A渠道,明天在B,这样的话我们现在是依赖于人工的,特别是那种系统,那个渠道进行一个系统更新,有的渠道更新两个小时三个小时,这时候我们是必须把这个渠道,把这个商铺全部切走的。但是目前也是基于人去点,或者出脚本,来把它切走,所以下一步我们就想,能不能看研究一下怎么把它做得更加智能一点。
还有一点就是分片,因为特别是在这一点,这点现在我们是做了一个任务分片,任务分片是基于它的效果来做分片的,还有就是一个数据分片,数据分片目前的做法是和是基于任务分片来做的,就是以它的效果,它任务分多少片或者数据也分多少片,因为这样跟它保持一致,那么它这样它的执行的时候,才会能找到对应的一个数据分片一个片项。
但是我们因为现在都是基于它来做它自动分配的,下一步我们就要想方法去研究一下,看怎么能可以随着我们的机器的资源一个动态的一个扩容,然后我们可以手动来进行干预,手动来触发一下。
原文发布时间为:2018-05-21
本文作者:刘恒
本文来自云栖社区合作伙伴“中生代技术”,了解相关信息可以关注“中生代技术”。







 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有