在Hbase中split是一个很重要的功能,Hbase是通过把数据分配到一定数量的region来达到负载均衡的。一个table会被分配到一个或多个region中,这些region会被分配到一个或者多个regionServer中。在自动split策略中,当一个region达到一定的大小就会自动split成两个region。table在region中是按照row key来排序的,并且一个row key所对应的行只会存储在一个region中,这一点保证了Hbase的强一致性 。
在一个region中有一个或多个stroe,每个stroe对应一个column families(列族)。一个store中包含一个memstore 和 0 或 多个store files。每个column family 是分开存放和分开访问的。
概念:
1、Split决定数据放到哪一个region(区)的一种策略,默认为当前文件大于10G时进行分割。
http://hbase.apache.org/book.html#hbase_default_configurations
2、region是hbase的一个存储区域,如果设置为本地存储,一般为一个目录。如以下表有四个regions:
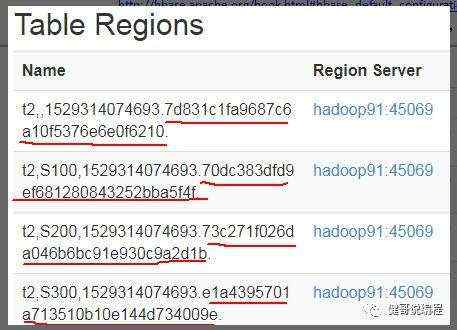
则查看本地目录:
drwxrwxr-x. 5 wangjian wangjian 72 6月 18 18:23 70dc383dfd9ef681280843252bba5f4f
drwxrwxr-x. 4 wangjian wangjian 60 6月 18 17:27 73c271f026da046b6bc91e930c9a2d1b
drwxrwxr-x. 5 wangjian wangjian 72 6月 18 18:23 7d831c1fa9687c6a10f5376e6e0f6210
drwxrwxr-x. 4 wangjian wangjian 60 6月 18 17:27 e1a4395701a713510b10e144d734009e
正好对应有四个目录。
3、Store就是一个Column Family, 即一个Store就是一个列族。
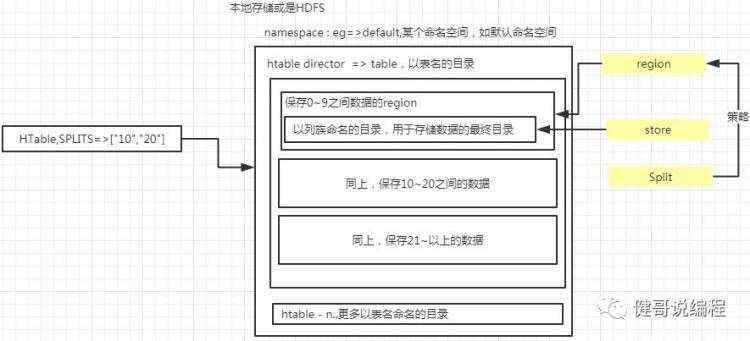
经过上面的分析,Spit,Region,Store的关系为:
2、关于保存到hbase中的中文转成ascii码的形式将中文保存到HBase数据库中。会出如:\xhh这样的形式。为什么呢?
首先需要说明的是hbase中保存的都是字节码,在保存过的过程中,会将字节码转成ascii码的形式加以保存。
以下保存一个”张”字到hbase数据库中:
hbase(main):004:0> put "t2",'S003',"info:name","张"
0 row(s) in 0.0670 seconds
然后查询:
hbase(main):006:0> get "t2","S003"
COLUMN CELL
info:name timestamp=1529327955211, value=\xE5\xBC\xA0
1 row(s) in 0.0690 seconds
查到的数据可见为:\xE5\xBC\xA0。
关于Ascii见下表的说明:
转义字符 | 意义 | ASCII码值(十进制) |
\a | 响铃(BEL) | 007 |
\b | 退格(BS) ,将当前位置移到前一列 | 008 |
\f | 换页(FF),将当前位置移到下页开头 | 012 |
\n | 换行(LF) ,将当前位置移到下一行开头 | 010 |
\r | 回车(CR) ,将当前位置移到本行开头 | 013 |
\t | 水平制表(HT) (跳到下一个TAB位置) | 009 |
\v | 垂直制表(VT) | 011 |
\\ | 代表一个反斜线字符''\' | 092 |
\' | 代表一个单引号(撇号)字符 | 039 |
\" | 代表一个双引号字符 | 034 |
\? | 代表一个问号 | 063 |
\0 | 空字符(NULL) | 000 |
\ooo | 1到3位八进制数所代表的任意字符 | 三位八进制 |
\xhh | 1到2位十六进制所代表的任意字符 | 二位十六进制 |
注意,最后一个\xhh,就是表示任意字符的ascii码。现在我们写一下段Java代码,将”张”字的字节码转成十六进制:
String name = "张";
byte[] bs = name.getBytes();
for(byte b:bs) {
System.out.println(Integer.toHexString(b));
}
获取到的结果为:
ffffffe5
ffffffbc
ffffffa0
现在我们将前面的6个进行与运算。然后再转成大写:
String name = "张";
String str = "";
byte[] bs = name.getBytes();
for (byte b : bs) {
String tem = Integer.toHexString(b & 0xff);
str+="\\x"+tem.toUpperCase();
}
System.out.println(str);
输出的结果为:
\xE5\xBC\xA0
现在再比较一下保存到Hbase中的数据,是不是相同的结果:
hbase(main):006:0> get "t2","S003"
COLUMN CELL
info:name timestamp=1529327955211, value=\xE5\xBC\xA0
在Java代码中,连接Hbase读取到的值可以直接转回成中文形式:
用于连接Hbase的公共代码:
package cn.wangjian.hbase.utils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.client.Admin;
import org.apache.hadoop.hbase.client.Connection;
import org.apache.hadoop.hbase.client.ConnectionFactory;
import org.apache.hadoop.hbase.client.HBaseAdmin;
public class HBaseConnection {
protected HBaseAdmin hbaseadmin;
protected Connection connection;
public HBaseConnection() throws Exception {
Configuration conf = HBaseConfiguration.create();
conf.set("hbase.zookeeper.quorum", "hadoop91:2181");
connection = ConnectionFactory.createConnection(conf);
Admin admin = connection.getAdmin();
if (admin instanceof HBaseAdmin) {
this.hbaseadmin = (HBaseAdmin) admin;
}
}
public void close() throws Exception{
hbaseadmin.close();
connection.close();
}
}
用于查询的测试代码:
package cn.wangjian.hbase;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.Get;
import org.apache.hadoop.hbase.client.Result;
import org.apache.hadoop.hbase.client.Table;
import org.apache.hadoop.hbase.util.Bytes;
import cn.wangjian.hbase.utils.HBaseConnection;
/**
* 使用Get对象查询,查询一个中文的值
*/
public class Demo08_ReadChinese extends HBaseConnection {
public Demo08_ReadChinese() throws Exception {
Table table = connection.getTable(TableName.valueOf("t2"));
Get get = new Get("S003".getBytes());//参数为行键
Result result = table.get(get);
byte[] bs = result.getValue("info".getBytes(), "name".getBytes());
String str = Bytes.toString(bs);
System.out.println(str);//张,可以直接返回中文
table.close();
close();
}
public static void main(String[] args) throws Exception {
new Demo08_ReadChinese();
}
}





 京公网安备 11010802041100号
京公网安备 11010802041100号