作者:CJFONe | 来源:互联网 | 2023-08-31 19:22
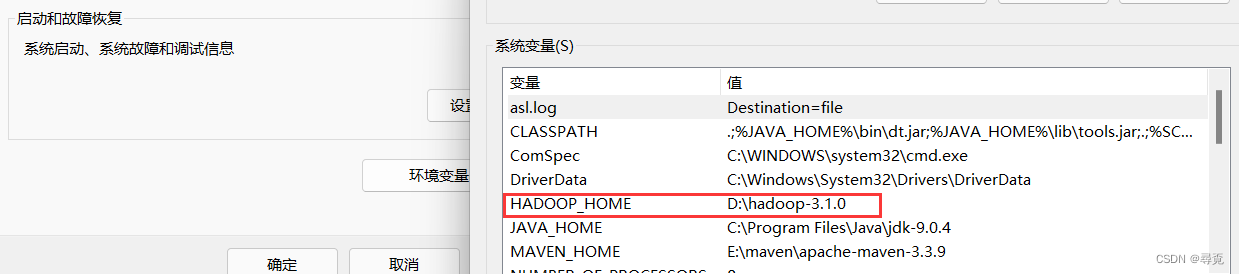
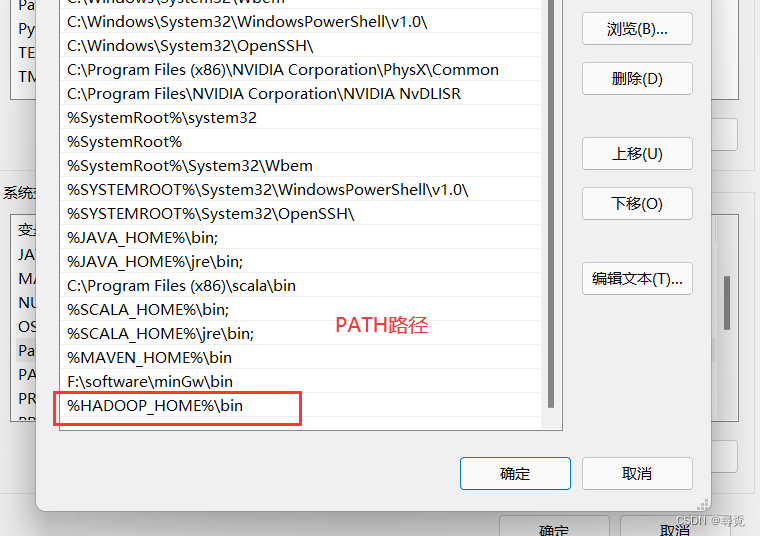
1、配置Windows环境变量
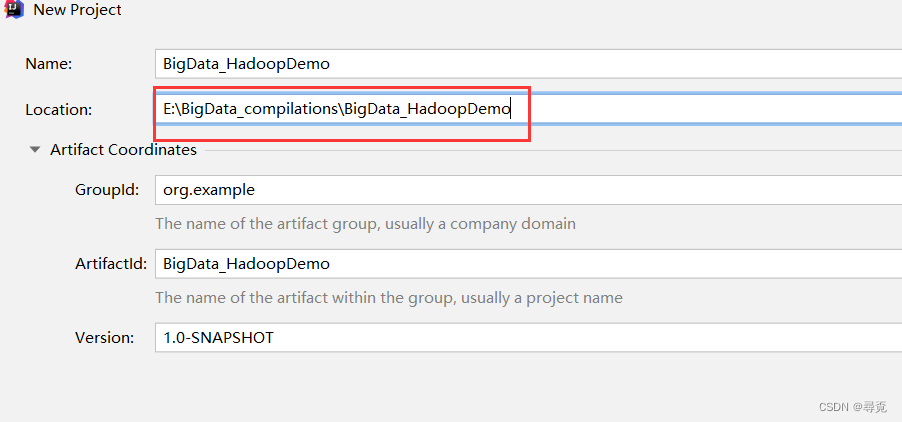
2、创建maven工程
3、导入相应的依赖坐标+日志添加
org.apache.hadoophadoop-client3.1.4junitjunit4.12org.slf4jslf4j-log4j121.7.30
重新载入
4、在项目的src/main/resources目录下,新建一个文件,命名为“log4j.properties”,在文件中填入
log4j.rootLogger=INFO, stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n
log4j.appender.logfile=org.apache.log4j.FileAppender
log4j.appender.logfile.File=target/spring.log
log4j.appender.logfile.layout=org.apache.log4j.PatternLayout
log4j.appender.logfile.layout.ConversionPattern=%d %p [%c] - %m%n
5、创建三个类
package com.haoedu.wordcount;import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;import java.io.IOException;/*** KEYIN, map阶段输入的key的类型:LongWritable* VALUEIN,map阶段输入value类型:Text* KEYOUT,map阶段输出的Key类型:Text* VALUEOUT,map阶段输出的value类型:IntWritable*/
public class WordCountMapper extends Mapper {private Text outkey= new Text();private IntWritable outvalue = new IntWritable(1);@Overrideprotected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {//获取一行String line = value.toString();String[] words = line.split(",");for (String word : words) {outkey.set(word);context.write(outkey, outvalue);}}
}
package com.haoedu.wordcount;import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;import java.io.IOException;/*** KEYIN, reduce阶段输入的key的类型:Text* VALUEIN,reduce阶段输入value类型:IntWritable* KEYOUT,reduce阶段输出的Key类型:Text* VALUEOUT,reduce阶段输出的value类型:IntWritable*/
public class WordCountReducer extends Reducer {private IntWritable outvalue = new IntWritable();@Overrideprotected void reduce(Text key, Iterable values, Context context) throws IOException, InterruptedException {int sum = 0;for (IntWritable value : values) {sum += value.get();}outvalue.set(sum);context.write(key,outvalue);}
}
package com.haoedu.wordcount;import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;import java.io.IOException;public class WordCountDriver {public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {// 1 获取jobConfiguration conf = new Configuration();Job job = Job.getInstance(conf);// 2 设置jar包路径job.setJarByClass(WordCountDriver.class);// 3 关联mapper和reducerjob.setMapperClass(WordCountMapper.class);job.setReducerClass(WordCountReducer.class);// 4 设置map输出的kv类型job.setMapOutputKeyClass(Text.class);job.setMapOutputValueClass(IntWritable.class);// 5 设置最终输出的kV类型job.setOutputKeyClass(Text.class);job.setOutputValueClass(IntWritable.class);// 6 设置输入路径和输出路径FileInputFormat.setInputPaths(job, new Path("D:\\大数据全集资料\\Hadoop3.x\\11_input\\inputword"));FileOutputFormat.setOutputPath(job, new Path("D:\\大数据全集资料\\Hadoop3.x\\output888"));// 7 提交jobboolean result = job.waitForCompletion(true);System.exit(result ? 0 : 1);}
}
结果如下
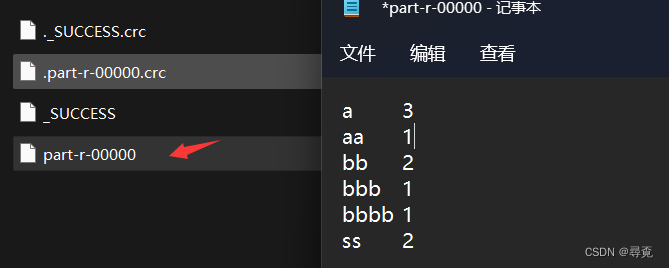
6、运行在Linux系统之上
注入依赖
maven-compiler-plugin3.6.11.81.8maven-assembly-pluginjar-with-dependenciesmake-assemblypackagesingle
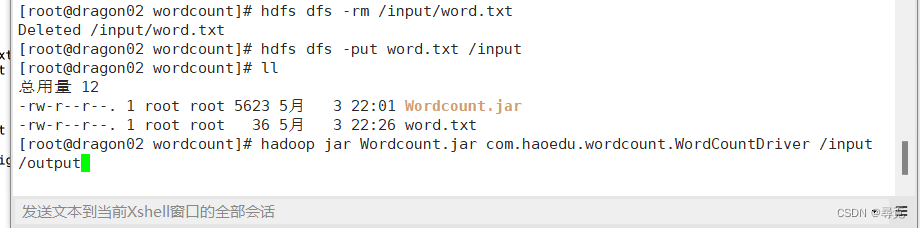
在集群上运行的时候需要动态输入,输入输出改成
args[0],args[1]
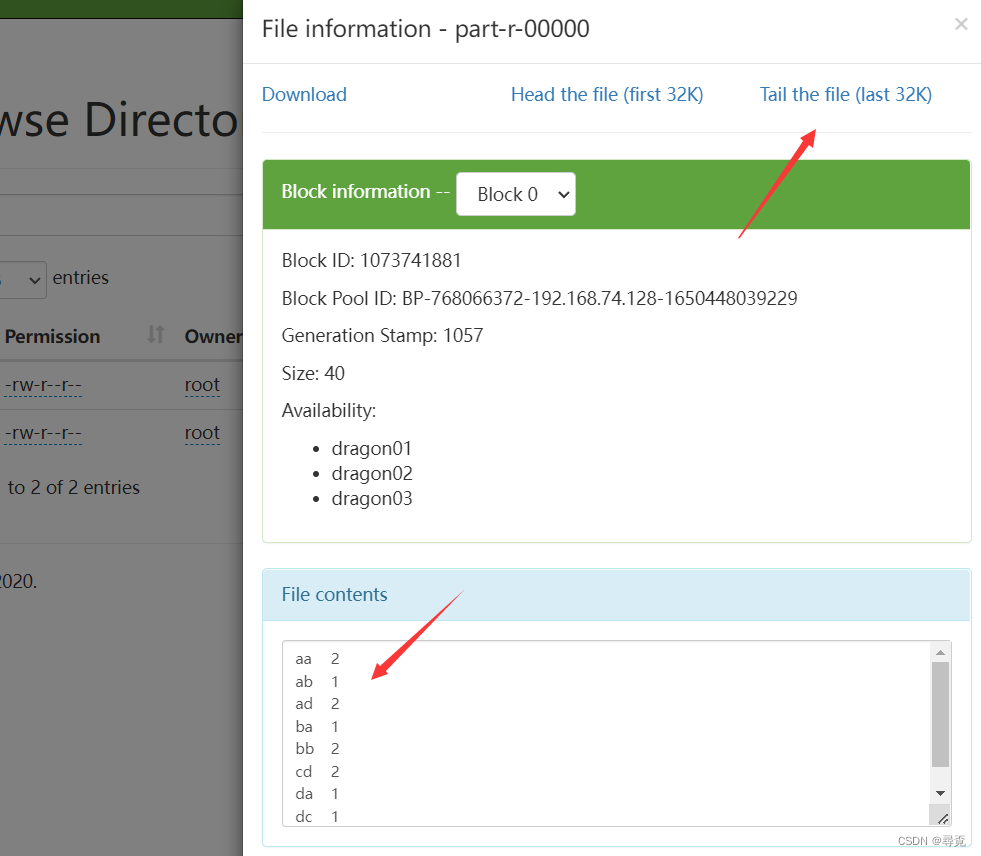






 京公网安备 11010802041100号
京公网安备 11010802041100号