Hadoop知识分享文稿 ( by quqi99 )
内容目录
目 录
1hadoop理论基础3
1.1hadoop是什么3
1.2hadoop项目3
1.3Map/Reduce任务的运行流程4
1.4Map/Reduce任务的数据流图5
2hadoop入门实战7
2.1测试环境7
2.2测试程序7
2.3属性配置9
2.4免密码SSH设置10
2.5配置hosts11
2.6格式化HDFS文件系统11
2.7启动守护进程11
2.8运行程序11
3hadoop高级进阶12
4hadoop应用案例12
5参考文献12
Hadoop是DougCutting开发的,他是一个相当牛的哥们,他同时是大名鼎鼎的Lucene及Nutch的作者。
我是这样理解hadoop的,它就是用来对海量数据进行存储与分析的一个开源软件。它包括两块:
1)HDFS( Hadoop Distrubuted File System ),可以对重要数据进行冗余存储,有点类似于冗余磁盘陈列。
2)对Map/Reduce编程模型的一个实现。当然,关系型数据库(RDBMS)也能做类似的事情,但为什么不用RDBMS呢?我们知道,让计算移动于数据上比让数据移动到计算更有效率。这使得Map/Reduce适合数据被一次写入和多次读取的应用,而RDBMS更适合持续更新的数据集。
如今,广义上的Hadoop已经发展成为一个分布式计算基础架构这把“大伞”下相关子项目的集合,其技术栈如下图所示:
图:
图1 hadoop的子项目
Core:一系列分布式文件系统和通用I/O的组件和接口(序列化、JavaRPC和持久化数据结构)。
Avro:用于数据的序列化,当然,JDK中也有Seriable接口,但hadoop中有它自己的序列化方式,具说更有效率。
MapReduce:分布式数据处理模式和执行环境,运行于大型商用机集群。
HDFS:分布式文件系统,运行于大型商用机集群。
Pig:HDFS上的数据检索语言,类似于RDBMS中的SQL语言。
Hbase:一个分布式的、列存储数据库。HBase使用HDFS作为底层存储,同时支持MapReduce的批量式计算和点查询(随机读取)。
ZooKeeper:一个分布式的、高可用性的协调服务。ZooKeeper提供分布式锁之类的基本服务用于构建分布式应用。
Hive:分布式数据仓库。Hive管理HDFS中存储的数据,并提供基于SQL的查询语言(由运行时引擎翻译成MapReduce作业)用以查询数据。
Chukwa:分布式数据收集和分析系统。Chukwa运行HDFS中存储数据的收集器,它使用MapReduce来生成报告。
JobClient的submitJob()方法的作业提交过程如下:
1)向Jobtraker请求一个新作业ID
2)调用JobTracker的getNewJobId()
3)JobClient进行作业划分,并将划分后的输入及作业的JAR文件、配置文件等复制到HDFS中去
4)提交作业,会把此调用放入到一个内部的队列中,交由作业调度器进行调度。值得一提的是,针对 Map任务与Reduce任务,任务调度器是优先选择Map任务的,另外,任务调度器在选择Reduce任务时并没有考虑数据的本地化。然而,针对一个Map任务,它考虑的是Tasktracker网络位置和选取一个距离其输入划分文件最近的Tasktracker,它可能是数据本地化的,也可能是机架本地化的,还可能得到不同的机架上取数据。
5)初始化包括创建一个代表该正在运行的作业的对象,它封装任务和记录信息,以便跟踪任务的状态和进度。
6)JobTracker任务调度器首先从共享文件系统中获取JobClient已计算好的输入划分信息,然后为每个划分创建一个Map任务。创建的reduce任务的数量是由JobConf的Mapred.reduce.tasks属性决定,它是用setNumReduceTask()方法来设置的。
7)TaskTracker执行一个简单的循环,定期发送心跳(Heartbeat)方法调用Jobtracker告诉是否还活着,同时,心跳还会报告任务运行的是否已经准备运行新的任务。
8)TaskTracker已经被分配了任务,下一步是运行任务。首先它需要将它所需的全部文件从HDFS中复制到本地磁盘。
9)紧接着,它要启动一个新的Java虚拟机来运行每个任务,这使得用户所定义的Map和Reduce函数的任务缺陷都不会影响TaskTracker(比如导致它崩溃或者挂起)
10)运行Map任务或者Reduce任务,值得一提的是,这些任务使用标准输入与输出流,换句话说,你可以用任务语言(如JAVA,C++,Shell等)来实现Map和Reduce,只要保证它们也使用标准输入与输出流,就可以将输出的键值对传回给JAVA进程了。
图3Map/Reduce中单一Reduce任务的数据流图
图4Map/Reduce中多个Reduce任务的数据流图
图5MapReduce中没有Reduce任务的数据流图
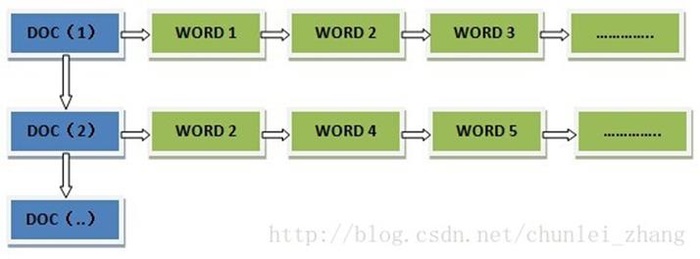
任务粒度:分片的个数,在将原始大数据切割成小数据集时,通常让小数据集小于或等于HDFS中的一个Block的大小(缺省是64M),这样能够保证一个小数据集位于一台计算机上,便于本地计算。有M 个小数据集待处理,就启动M 个Map 任务,注意这M 个Map 任务分布于N 台计算机上并行运行,Reduce任务的数量 R则可由用户指定。
Map: 输入
Reduce :输入
分区(Partition): 把Map 任务输出的中间结果按key 的范围划分成R 份(R 是预先定义的 Reduce任务的个数),划分时通常使用hash 函数如:hash(key) mod R,这样可以保证某一段范围内的key,一定是由一个Reduce 任务来处理,可以简化Reduce 的过程。
Combine: 在 partition之前,还可以对中间结果先做combine,即将中间结果中有相同key的
下面举个例子来着重说明Combine,hadoop允许用户声明一个combiner运行在Map的输出上,它的输出再作为Reduce的输入。例如,找出每一年的最调气温:
假如用户的输入的分片数是2,那么:
1)第一个Map的输出如下:
(1950,0)
(1950,20)
(1950,10)
2)第二个Map的输出如下:
(1950,25)
(1950,15)
3)Reduce的输入如下:
(1950,[0,20,10,25,15])
注意:如果有combine的话,此时Reduce的输入应该是:
max(0,20, 10, 25, 15) = max(max(0,20,10), max(25,15)) = max(20,25)
combine并不能取代reduce,例如,如果我们计算平均气温,便不能使用combine,因为:
mean(0,20,10,25,15)= 14
但是:
mean(mean(0,20,10),mean(25,15)) = mean(10,20) = 15
4)Reduce的输出如下:
(1950,25)
hadoop有三种部署模式:
单机模式:没有守护进程,一切都运行在单个JVM上,适合测试与调试。
伪集群模式:守护进程在本地运行,适合模拟集群。
集群模式:守护进程运行在集群的某台机器上。
所以,在以上任一特定模式运行hadoop时,只需要做两件事情:
1)设置适当属性
2)启动hadoop的守护进程(名称节点,二级名称节名,数据节点)
hadoop默认的是单机模式,下面,我们将着重介绍在集群模式是如何部署?
用两台机器做为测试环境,通常,集群里的一台机器被指定为NameNode,另一台不同的机器被指定为JobTracker,这些机器是masters;余下的机器即作为DataNode也作为TaskTracker,这些机器是slaves。
1)master(JobTracker & NameNode):我的工作机( zhanghua.quqi.com)
2)slave(TaskTracker & DataNode):我的开发机(tadev03.quqi.com)
3) 两机均已安装ssh与 rsync
1)/home/workspace/hadoopExample/input/file01:
HelloWorld Bye World
2)/home/workspace/hadoopExample/input/file02:
HelloHadoopGoodbye Hadoop
WordCount.java
packagecom.TripResearch.hadoop;
importjava.io.IOException;
importjava.util.Iterator;
importjava.util.StringTokenizer;
importorg.apache.hadoop.fs.Path;
importorg.apache.hadoop.io.IntWritable;
importorg.apache.hadoop.io.LongWritable;
importorg.apache.hadoop.io.Text;
importorg.apache.hadoop.mapred.FileInputFormat;
importorg.apache.hadoop.mapred.FileOutputFormat;
importorg.apache.hadoop.mapred.JobClient;
importorg.apache.hadoop.mapred.JobConf;
importorg.apache.hadoop.mapred.MapReduceBase;
importorg.apache.hadoop.mapred.Mapper;
importorg.apache.hadoop.mapred.OutputCollector;
importorg.apache.hadoop.mapred.Reducer;
importorg.apache.hadoop.mapred.Reporter;
importorg.apache.hadoop.mapred.TextInputFormat;
importorg.apache.hadoop.mapred.TextOutputFormat;
/**
*@authorhuazhang
*/
@SuppressWarnings("deprecation")
publicclassWordCount {
publicstaticclassMyMap extendsMapReduceBaseimplements
Mapper
privatefinalstaticIntWritable one= newIntWritable(1);
privateText word =newText();
publicvoidmap(LongWritable key, Text value,
OutputCollector
throwsIOException {
Stringline = value.toString();
StringTokenizertokenizer = newStringTokenizer(line);
while(tokenizer.hasMoreTokens()) {
word.set(tokenizer.nextToken());
output.collect(word,one);
}
}
}
publicstaticclassMyReduce extendsMapReduceBaseimplements
Reducer
publicvoidreduce(Text key, Iterator
OutputCollector
throwsIOException {
intsum = 0;
while(values.hasNext()) {
sum+= values.next().get();
}
output.collect(key,newIntWritable(sum));
}
}
publicstaticvoidmain(String[] args) throwsException {
JobConfcOnf= newJobConf(WordCount.class);
conf.setJobName("wordcount");
conf.setOutputKeyClass(Text.class);
conf.setOutputValueClass(IntWritable.class);
conf.setMapperClass(MyMap.class);
conf.setCombinerClass(MyReduce.class);
conf.setReducerClass(MyReduce.class);
conf.setInputFormat(TextInputFormat.class);
conf.setOutputFormat(TextOutputFormat.class);
FileInputFormat.setInputPaths(conf,newPath(args[0]));
FileOutputFormat.setOutputPath(conf,newPath(args[1]));
JobClient.runJob(conf);
}
}
按下图所示修改至少3个属性, 如下图所示:
conf/core-site.xml
注意:此处如果是伪集群模式可配置为hdfs://localhost:9000,是本地模式则为:localhost:9000。另外,其他输入输入路径,是本地模式是本地文件系统的路径,是非地模式,用hdfs文件系统的路径格式。
conf/hdfs-site.xml
conf/mapred-site.xml
masters
zhanghua.quqi.com(伪分布模式就配成localhost)
slaves
tadev03.quqi.com(伪分布模式就配成localhost)
将以上配置好的hadoop文件夹拷到所有机器的相同目录下:
scp-r /home/soft/hadoop-0.20.2root@tadev03.quqi.com:/home/soft/hadoop-0.20.2
注意:确保两台机器的JAVA_HOME的路径一致,如果不一致,就要改。
hadoop所有可配置的配置文件说明如下:
hadoop-env.sh 运行hadoop的脚本中使用的环境变量
core-site.xml hadoop的核心配置,如HDFS和MapReduce中很普遍的I/O设置
hdfs-site.xml HDFS后台程序设置的配置:名称节点,第二名称节点及数据节点
mapred-site.xml MapReduce后台程序设置的配置:jobtracker和tasktracker
masters 记录运行第二名称节点的机器(一行一个)的列表
slaves 记录运行数据节点的机器(一行一个)的列表
免密码ssh设置,保证至少从master可以不用口令登陆所有的slaves。
1)生成密钥对:ssh-keygen-t rsa -P '' -f /root/.ssh/id_rsa (这样密钥就留在了客户端)
2)将公钥拷到要连接的服务器,
scp/root/.ssh/id_rsa.pub root@tadev03.quqi.com:/tmp
ssh-l root tadev03.quqi.com
more/tmp/id_rsa.pub >> /root/.ssh/authorized_keys
sshtadev03.quqi.com 不需要输入密码即为成功。
(注意:伪分布模式也要配置sshlocalhost无密码登录,如果是mac,请将ssh打开)
(另外,在mac中请在hadoop-config.sh文件中配置exportJAVA_HOME=/System/Library/Frameworks/JavaVM.framework/Versions/1.6/Home)
三条控制线线:
SSH → 这样就可以直接从主节点远程启动从节点上的脚本,如sshtadev03.quqi.com '/var/aa.sh'
NameNode (http://localhost:50070) →DataNode
JobTracker(http://localhost:50030)→TaskTracker (http://localhost:50060)
必须配置master和slaves之间的双向hosts.修改/etc/hosts进行配置,略。
和我们常见的NTFS,FAT32文件系统一样,NDFS最开始也是需要格式化的。格式化过程用来创建存储目录以及名称节点的永久数据结构的初始版本来创建一个空的文件系统。命令如下:
hadoopnamenode -format
已知问题:在重新格式化时,可能会报:SHUTDOWN_MSG:Shutting down NameNode
解决办法:rm-rf /tmp/hadoop-root/dfs/name
1)启动HDFS守护进程:start-dfs.sh
(start-dfs.sh脚本会参照NameNode上${HADOOP_CONF_DIR}/slaves文件的内容,在所有列出的slave上启动DataNode守护进程。)
已知问题:在已设置JAVA_HOME的情况下仍会报:Error:JAVA_HOME is not set
解决办法:我是在hadoop.sh文件中加下面一句解决的:
JAVA_HOME=/System/Library/Frameworks/JavaVM.framework/Versions/1.6/Home
2)启动Map/Reduce守护进程:start-mapred.sh
(start-mapred.sh脚本会参照JobTracker上${HADOOP_CONF_DIR}/slaves文件的内容,在所有列出的slave上启动TaskTracker守护进程)
3)启动成功后,可以通过访问http://localhost:50030验证。
注意:也可直接使用start-all.sh与stop-all.sh脚本,在主节点master上面启动hadoop,主节点会启动/停止所有从节点的hadoop。会启动5个java进程,同时会在/tmp目录下创建五个pid文件记录这些进程ID号。通过这五个文件,可以得知namenode,datanode, secondary namenode, jobtracker, tasktracker 分别对应于哪一个Java进程。
已知问题:启动后,日志中报:java.io.IOException:File /tmp/hadoop-root/mapred/system/jobtracker.info could only bereplicated to 0 nodes, instead of 1
解决办法:原因是从tadev03.quqi.com机器上无法pingzhanghua.quqi.com
先将测试数据及其他输入由本地文件系统拷到HFDS文件系统中去(注意:jar除外)
hadoopfs -mkdir input
hadoopfs -ls .
hadoopfs -copyFromLocal /home/workspace/hadoopExample/input/file01input/file01
hadoopfs -copyFromLocal /home/workspace/hadoopExample/input/file02input/file02
这时候就可以执行下列命令运行程序了,注意:后面的input, output等目录都是HDFS文件系统的路径。(如果是本地模式,就用本地文件系统的绝对路径)
hadoopjar/home/workspace/hadoopExample/hadoopExample.jarcom.TripResearch.hadoop.WordCount input/output
已知问题:在集群模式下运行时任务会Pending
最后,运行下列命令查看结果:
/home/soft/hadoop-0.20.2/bin/hadoopfs -cat output/part-00000
也可访问下列地址查看状态:
NameNode– http://zhanghua.quqi.com:50070/
JobTracker- http://zhanghua.quqi.com:50030/
常用命令说明如下:
hadoopdfs –ls 查看/usr/root目录下的内容径;
hadoop dfs –rmr xxx xxx就是删除目录;
hadoop dfsadmin -report 这个命令可以全局的查看DataNode的情况;
hadoop job -list 后面增加参数是对于当前运行的Job的操作,例如list,kill等;
hadoop balancer 均衡磁盘负载的命令。
http://hadoop.apache.org/common/docs/r0.18.2/cn/
hadoop0.20.2集群配置入门http://dev.firnow.com/course/3_program/java/javajs/
Hadoop分布式文件系统(HDFS)初步实践http://huatai.me/?p=352
Hadoop分布式部署实验2_格式化分布式文件系统http://hi.baidu.com/thinke365/blog/item/15602aa8f9074cf41e17a235.html
hadoop安装出现问题(紧急),请前辈指教http://forum.hadoop.tw/viewtopic.php?f=4&t=90
用 Hadoop进行分布式并行编程http://www.ibm.com/developerworks/cn/opensource/os-cn-hadoop1/index.html
用 Hadoop进行分布式数据处理http://tech.ddvip.com/2010-06/1275983295155033.html







 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有