1
HADOOP背景
1
什么是HADOOP
1. HADOOP是apache旗下的一套开源软件平台
2. HADOOP提供的功能:利用服务器集群,根据用户的自定义业务逻辑,对海量数据进行分布式处理
3. HADOOP的核心组件有
4. HDFS(分布式文件系统)
5. YARN(运算资源调度系统)
6. MAPREDUCE(分布式运算编程框架)
7. 广义上来说,HADOOP通常是指一个更广泛的概念——HADOOP生态圈
2
HADOOP产生背景
2.2003年、2004年谷歌发表的两篇论文为该问题提供了可行的解决方案。
——分布式文件系统(GFS),可用于处理海量网页的存储
——分布式计算框架MAPREDUCE,可用于处理海量网页的索引计算问题。
3.Nutch的开发人员完成了相应的开源实现HDFS和MAPREDUCE,并从Nutch中剥离成为独立项目HADOOP,到2008年1月,HADOOP成为Apache顶级项目,迎来了它的快速发展期。
3
HADOOP生态圈简介

重点组件:
HDFS:分布式文件系统
MAPREDUCE:分布式运算程序开发框架
HIVE:基于大数据技术(文件系统+运算框架)的SQL数据仓库工具
HBASE:基于HADOOP的分布式海量数据库
ZOOKEEPER:分布式协调服务基础组件
Mahout:基于mapreduce/spark/flink等分布式运算框架的机器学习算法库
Oozie:工作流调度框架
Sqoop:数据导入导出工具
Flume:日志数据采集框架
2
HADOOP集群搭建
1
集群简介
HADOOP集群具体来说包含两个集群:HDFS集群和YARN集群,两者逻辑上分离,但物理上常在一起
HDFS集群:
负责海量数据的存储,集群中的角色主要有 NameNode / DataNode
YARN集群:
负责海量数据运算时的资源调度,集群中的角色主要有 ResourceManager /NodeManager
(那mapreduce是什么呢?它其实是一个应用程序开发包
2
集群安装
3
集群启动
初始化HDFS
bin/hadoop namenode -format
启动HDFS
sbin/start-dfs.sh
启动YARN
sbin/start-yarn.sh
4
集群初步使用
命令: hdfs dfsadmin –report
也可打开web控制台查看HDFS集群信息,在浏览器打开http://hdp-node:50070/
查看HDFS中的目录信息
命令: hadoop fs –ls /
上传文件
命令: hadoop fs -put ./ scala-2.10.6.tgz to /
从HDFS下载文件
命令:hadoop fs -get /yarn-site.xml
3
HDFS
1
前言
设计思想
分而治之:将大文件、大批量文件,分布式存放在大量服务器上,以便于采取分而治之的方式对海量数据进行运算分析;
在大数据系统中作用:
为各类分布式运算框架(如:mapreduce,spark,tez,……)提供数据存储服务
重点概念:文件切块,副本存放,元数据
2
HDFS的概念和特性
首先,它是一个文件系统,用于存储文件,通过统一的命名空间——目录树来定位文件
其次,它是分布式的,由很多服务器联合起来实现其功能,集群中的服务器有各自的角色;
重要特性如下:
HDFS中的文件在物理上是分块存储(block),块的大小可以通过配置参数( dfs.blocksize)来规定,默认大小在hadoop2.x版本中是128M,老版本中是64M
HDFS文件系统会给客户端提供一个统一的抽象目录树,客户端通过路径来访问文件,形如:hdfs://namenode:port/dir-a/dir-b/dir-c/file.data
目录结构及文件分块信息(元数据)的管理由namenode节点承担——namenode是HDFS集群主节点,负责维护整个hdfs文件系统的目录树,以及每一个路径(文件)所对应的block块信息(block的id,及所在的datanode服务器)
文件的各个block的存储管理由datanode节点承担---- datanode是HDFS集群从节点,每一个block都可以在多个datanode上存储多个副本(副本数量也可以通过参数设置dfs.replication)
HDFS是设计成适应一次写入,多次读出的场景,且不支持文件的修改
3
HDFS命令行客户端操作
HDFS提供shell命令行客户端,使用方法如下:
hadoop fs -ls /
hdfs dfs -ls /
[-appendToFile [-cat [-ignoreCrc] [-checksum [-chgrp [-R] GROUP PATH...] [-chmod [-R] [-chown [-R] [OWNER][:[GROUP]] PATH...] [-copyFromLocal [-f] [-p] [-copyToLocal [-p] [-ignoreCrc] [-crc] [-count [-q] ...] [-cp [-f] [-p] [-createSnapshot [-deleteSnapshot [-df [-h] [ ...]] [-du [-s] [-h] ...] [-expunge] [-get [-p] [-ignoreCrc] [-crc] [-getfacl [-R] ] [-getmerge [-nl] [-help [cmd ...]] [-ls [-d] [-h] [-R] [ ...]] [-mkdir [-p] ...] [-moveFromLocal [-moveToLocal [-mv [-put [-f] [-p] [-renameSnapshot [-rm [-f] [-r|-R] [-skipTrash] [-rmdir [--ignore-fail-on-non-empty] [-setfacl [-R] [{-b|-k} {-m|-x ]|[--set ]] [-setrep [-R] [-w] ...] [-stat [format] ...] [-tail [-f] [-test -[defsz] ] [-text [-ignoreCrc] [-touchz ...] [-usage [cmd ...]] |
-help 功能:输出这个命令参数手册 |
-ls 功能:显示目录信息 示例:hadoop fs -ls hdfs://hadoop-server01:9000/ 备注:这些参数中,所有的hdfs路径都可以简写 -->hadoop fs -ls / 等同于上一条命令的效果 |
-mkdir 功能:在hdfs上创建目录 示例:hadoop fs -mkdir -p /aaa/bbb/cc/dd |
-moveFromLocal 功能:从本地剪切粘贴到hdfs 示例:hadoop fs - moveFromLocal /home/hadoop/a.txt /aaa/bbb/cc/dd -moveToLocal 功能:从hdfs剪切粘贴到本地 示例:hadoop fs - moveToLocal /aaa/bbb/cc/dd /home/hadoop/a.txt |
--appendToFile 功能:追加一个文件到已经存在的文件末尾 示例:hadoop fs -appendToFile ./hello.txt hdfs://hadoop-server01:9000/hello.txt 可以简写为: Hadoop fs -appendToFile ./hello.txt /hello.txt |
-cat 功能:显示文件内容 示例:hadoop fs -cat /hello.txt -tail 功能:显示一个文件的末尾 示例:hadoop fs -tail /weblog/access_log.1 -text 功能:以字符形式打印一个文件的内容 示例:hadoop fs -text /weblog/access_log.1 |
-chgrp -chmod -chown 功能:linux文件系统中的用法一样,对文件所属权限 示例: hadoop fs -chmod 666 /hello.txt hadoop fs -chown someuser:somegrp /hello.txt |
-copyFromLocal 功能:从本地文件系统中拷贝文件到hdfs路径去 示例:hadoop fs -copyFromLocal ./jdk.tar.gz /aaa/ -copyToLocal 功能:从hdfs拷贝到本地 示例:hadoop fs -copyToLocal /aaa/jdk.tar.gz |
-cp 功能:从hdfs的一个路径拷贝hdfs的另一个路径 示例:hadoop fs -cp /aaa/jdk.tar.gz /bbb/jdk.tar.gz.2 -mv 功能:在hdfs目录中移动文件 示例:hadoop fs -mv /aaa/jdk.tar.gz / |
-get 功能:等同于copyToLocal,就是从hdfs下载文件到本地 示例:hadoop fs -get /aaa/jdk.tar.gz -getmerge 功能:合并下载多个文件 示例:比如hdfs的目录 /aaa/下有多个文件:log.1, log.2,log.3,... hadoop fs -getmerge /aaa/log.* ./log.sum |
-put 功能:等同于copyFromLocal 示例:hadoop fs -put /aaa/jdk.tar.gz /bbb/jdk.tar.gz.2 |
-rm 功能:删除文件或文件夹 示例:hadoop fs -rm -r /aaa/bbb/ -rmdir 功能:删除空目录 示例:hadoop fs -rmdir /aaa/bbb/ccc |
-df 功能:统计文件系统的可用空间信息 示例:hadoop fs -df -h / -du 功能:统计文件夹的大小信息 示例: hadoop fs -du -s -h /aaa/* |
-count 功能:统计一个指定目录下的文件节点数量 示例:hadoop fs -count /aaa/ |
-setrep 功能:设置hdfs中文件的副本数量 示例:hadoop fs -setrep 3 /aaa/jdk.tar.gz |
4
HDFS的工作机制
HDFS集群分为两大角色:NameNode、DataNode (Secondary Namenode)
NameNode负责管理整个文件系统的元数据
DataNode 负责管理用户的文件数据块
文件会按照固定的大小(blocksize)切成若干块后分布式存储在若干台datanode上
每一个文件块可以有多个副本,并存放在不同的datanode上
Datanode会定期向Namenode汇报自身所保存的文件block信息,而namenode则会负责保持文件的副本数量
HDFS的内部工作机制对客户端保持透明,客户端请求访问HDFS都是通过向namenode申请来进行
客户端要向HDFS写数据,首先要跟namenode通信以确认可以写文件并获得接收文件block的datanode,然后,客户端按顺序将文件逐个block传递给相应datanode,并由接收到block的datanode负责向其他datanode复制block的副本

1、根namenode通信请求上传文件,namenode检查目标文件是否已存在,父目录是否存在
2、namenode返回是否可以上传
3、client请求第一个 block该传输到哪些datanode服务器上
4、namenode返回3个datanode服务器ABC
5、client请求3台dn中的一台A上传数据(本质上是一个RPC调用,建立pipeline),A收到请求会继续调用B,然后B调用C,将真个pipeline建立完成,逐级返回客户端
6、client开始往A上传第一个block(先从磁盘读取数据放到一个本地内存缓存),以packet为单位,A收到一个packet就会传给B,B传给C;A每传一个packet会放入一个应答队列等待应答
7、当一个block传输完成之后,client再次请求namenode上传第二个block的服务器。
客户端将要读取的文件路径发送给namenode,namenode获取文件的元信息(主要是block的存放位置信息)返回给客户端,客户端根据返回的信息找到相应datanode逐个获取文件的block并在客户端本地进行数据追加合并从而获得整个文件

1、跟namenode通信查询元数据,找到文件块所在的datanode服务器
2、挑选一台datanode(就近原则,然后随机)服务器,请求建立socket流
3、datanode开始发送数据(从磁盘里面读取数据放入流,以packet为单位来做校验)
4、客户端以packet为单位接收,现在本地缓存,然后写入目标文件
5
NameNode工作机制
负责客户端请求的响应
元数据的管理(查询,修改)
namenode对数据的管理采用了三种存储形式:
内存元数据(NameSystem)
磁盘元数据镜像文件
数据操作日志文件(可通过日志运算出元数据)
A、内存中有一份完整的元数据(内存meta data)
B、磁盘有一个“准完整”的元数据镜像(fsimage)文件(在namenode的工作目录中)
C、用于衔接内存metadata和持久化元数据镜像fsimage之间的操作日志(edits文件)
注:当客户端对hdfs中的文件进行新增或者修改操作,操作记录首先被记入edits日志文件中,当客户端操作成功后,相应的元数据会更新到内存meta.data中
可以通过hdfs的一个工具来查看edits中的信息
bin/hdfs oev -i edits -o edits.xml
bin/hdfs oiv -i fsimage_0000000000000000087 -p XML -o fsimage.xml
每隔一段时间,会由secondary namenode将namenode上积累的所有edits和一个最新的fsimage下载到本地,并加载到内存进行merge(这个过程称为checkpoint)
Secondary NameNode
Secondary namenode的职责是合并namenode的edit logs到fsimage文件中。
每隔一段时间,会由secondary namenode将namenode上积累的所有edits和一个最新的fsimage下载到本地,并加载到内存进行merge(这个过程称为checkpoint)
namenode和secondary namenode的工作目录存储结构完全相同,所以,当namenode故障退出需要重新恢复时,可以从secondary namenode的工作目录中将fsimage拷贝到namenode的工作目录,以恢复namenode的元数据
但是只能恢复大部分数据,并不能恢复全部数据,因为有些数据可能还没做checkpoint
checkpoint操作的触发条件配置参数
dfs.namenode.checkpoint.check.period=60 #检查触发条件是否满足的频率,60秒 dfs.namenode.checkpoint.dir=file://${hadoop.tmp.dir}/dfs/namesecondary #以上两个参数做checkpoint操作时,secondary namenode的本地工作目录 dfs.namenode.checkpoint.edits.dir=${dfs.namenode.checkpoint.dir} dfs.namenode.checkpoint.max-retries=3 #最大重试次数 dfs.namenode.checkpoint.period=3600 #两次checkpoint之间的时间间隔3600秒 dfs.namenode.checkpoint.txns=1000000 #两次checkpoint之间最大的操作记录 |

1. Secondary namenode请求是否需要checkpoint
2. 得到namenode响应后,Secondary namenode请求checkpoint
3. Namenode滚动当前正在写的edit文件,该文件为待合并状态,也会生成新的edits.inprogress文件,后续的修改日志将写入该文件中
4. Secondary namenode将待合并的edits文件和fsimage文件一起下载到Secondary namenode本地。
5. Secondary namenode将fsimage文件和edits文件加载到内存进行合并。dump成新的fsimage文件fsimage.chkpoint。
6. Secondary namenode将fsimage.chkpoint上传到namenode,并重命名为fsimage。
checkpoint的附带作用
namenode和secondary namenode的工作目录存储结构完全相同,所以,当namenode故障退出需要重新恢复时,可以从secondary namenode的工作目录中将fsimage拷贝到namenode的工作目录,以恢复namenode的元数据
在第一次部署好Hadoop集群的时候,我们需要在NameNode(NN)节点上格式化磁盘:
$HADOOP_HOME/bin/hdfs namenode -format |
格式化完成之后,将会在$dfs.namenode.name.dir/current目录下如下的文件结构
current/ |-- VERSION |-- edits_* |-- fsimage_0000000000008547077 |-- fsimage_0000000000008547077.md5 `-- seen_txid |
其中的dfs.name.dir是在hdfs-site.xml文件中配置的,默认值如下:
hadoop.tmp.dir是在core-site.xml中配置的,默认值如下 |
dfs.namenode.name.dir属性可以配置多个目录,
如/data1/dfs/name,/data2/dfs/name,/data3/dfs/name,....。各个目录存储的文件结构和内容都完全一样,相当于备份,这样做的好处是当其中一个目录损坏了,也不会影响到Hadoop的元数据,特别是当其中一个目录是NFS(网络文件系统Network File System,NFS)之上,即使你这台机器损坏了,元数据也得到保存。
下面对$dfs.namenode.name.dir/current/目录下的文件进行解释。1、VERSION文件是Java属性文件,内容大致如下:
#Fri Nov 15 19:47:46 CST 2013 namespaceID=934548976 clusterID=CID-cdff7d73-93cd-4783-9399-0a22e6dce196 cTime=0 storageType=NAME_NODE blockpoolID=BP-893790215-192.168.24.72-1383809616115 layoutVersion=-47 |
其中 (1)、namespaceID是文件系统的唯一标识符,在文件系统首次格式化之后生成的; (2)、storageType说明这个文件存储的是什么进程的数据结构信息(如果是DataNode,storageType=DATA_NODE); (3)、cTime表示NameNode存储时间的创建时间,由于我的NameNode没有更新过,所以这里的记录值为0,以后对NameNode升级之后,cTime将会记录更新时间戳; (4)、layoutVersion表示HDFS永久性数据结构的版本信息, 只要数据结构变更,版本号也要递减,此时的HDFS也需要升级,否则磁盘仍旧是使用旧版本的数据结构,这会导致新版本的NameNode无法使用; (5)、clusterID是系统生成或手动指定的集群ID,在-clusterid选项中可以使用它
2、$dfs.namenode.name.dir/current/seen_txid非常重要,是存放transactionId的文件,format之后是0,它代表的是namenode里面的edits_*文件的尾数,namenode重启的时候,会按照seen_txid的数字,循序从头跑edits_0000001~到seen_txid的数字。所以当你的hdfs发生异常重启的时候,一定要比对seen_txid内的数字是不是你edits最后的尾数,不然会发生建置namenode时metaData的资料有缺少,导致误删Datanode上多余Block的资讯。
3、$dfs.namenode.name.dir/current目录下在format的同时也会生成fsimage和edits文件,及其对应的md5校验文件。
补充:seen_txid
文件中记录的是edits滚动的序号,每次重启namenode时,namenode就知道要将哪些edits进行加载edits
6
DataNode工作机制
1、Datanode工作职责:
存储管理用户的文件块数据
定期向namenode汇报自身所持有的block信息(通过心跳信息上报)
(这点很重要,因为,当集群中发生某些block副本失效时,集群如何恢复block初始副本数量的问题)
2、Datanode掉线判断时限参数
datanode进程死亡或者网络故障造成datanode无法与namenode通信,namenode不会立即把该节点判定为死亡,要经过一段时间,这段时间暂称作超时时长。HDFS默认的超时时长为10分钟+30秒。如果定义超时时间为timeout,则超时时长的计算公式为:
timeout = 2 * heartbeat.recheck.interval + 10 * dfs.heartbeat.interval。
而默认的heartbeat.recheck.interval 大小为5分钟,dfs.heartbeat.interval默认为3秒。
需要注意的是hdfs-site.xml 配置文件中的heartbeat.recheck.interval的单位为毫秒,dfs.heartbeat.interval的单位为秒。所以,举个例子,如果heartbeat.recheck.interval设置为5000(毫秒),dfs.heartbeat.interval设置为3(秒,默认),则总的超时时间为40秒。
|
7
HDFS的java操作
hdfs在生产应用中主要是客户端的开发,其核心步骤是从hdfs提供的api中构造一个HDFS的访问客户端对象,然后通过该客户端对象操作(增删改查)HDFS上的文件
|
建议在linux下进行hadoop应用的开发,不会存在兼容性问题。如在window上做客户端应用开发,需要设置以下环境:
1. 在windows的某个目录下解压一个hadoop的安装包
2. 将安装包下的lib和bin目录用对应windows版本平台编译的本地库替换
3. 在window系统中配置HADOOP_HOME指向你解压的安装包
4. 在windows系统的path变量中加入hadoop的bin目录
在java中操作hdfs,首先要获得一个客户端实例
Configuration cOnf= new Configuration() FileSystem fs = FileSystem.get(conf) |
而我们的操作目标是HDFS,所以获取到的fs对象应该是DistributedFileSystem的实例;
get方法是从何处判断具体实例化那种客户端类呢?
——从conf中的一个参数 fs.defaultFS的配置值判断;
如果我们的代码中没有指定fs.defaultFS,并且工程classpath下也没有给定相应的配置,conf中的默认值就来自于hadoop的jar包中的core-default.xml,默认值为: file:///,则获取的将不是一个DistributedFileSystem的实例,而是一个本地文件系统的客户端对象
public class HdfsClient { FileSystem fs = null; @Before public void init() throws Exception { // 构造一个配置参数对象,设置一个参数:我们要访问的hdfs的URI // 从而FileSystem.get()方法就知道应该是去构造一个访问hdfs文件系统的客户端,以及hdfs的访问地址 // new Configuration();的时候,它就会去加载jar包中的hdfs-default.xml // 然后再加载classpath下的hdfs-site.xml Configuration cOnf= new Configuration(); conf.set("fs.defaultFS", "hdfs://hdp-node01:9000"); /** * 参数优先级:1、客户端代码中设置的值 2、classpath下的用户自定义配置文件 3、然后是服务器的默认配置 */ conf.set("dfs.replication", "3"); // 获取一个hdfs的访问客户端,根据参数,这个实例应该是DistributedFileSystem的实例 // fs = FileSystem.get(conf); // 如果这样去获取,那conf里面就可以不要配"fs.defaultFS"参数,而且,这个客户端的身份标识已经是hadoop用户 fs = FileSystem.get(new URI("hdfs://hdp-node01:9000"), conf, "hadoop"); } /** * 往hdfs上传文件 * * @throws Exception */ @Test public void testAddFileToHdfs() throws Exception { // 要上传的文件所在的本地路径 Path src = new Path("g:/book.zip"); // 要上传到hdfs的目标路径 Path dst = new Path("/aaa"); fs.copyFromLocalFile(src, dst); fs.close(); } /** * 从hdfs中复制文件到本地文件系统 * * @throws IOException * @throws IllegalArgumentException */ @Test public void testDownloadFileToLocal() throws IllegalArgumentException, IOException { fs.copyToLocalFile(new Path("/book.tar.gz"), new Path("d:/")); fs.close(); } @Test public void testMkdirAndDeleteAndRename() throws IllegalArgumentException, IOException { // 创建目录 fs.mkdirs(new Path("/a1/b1/c1")); // 删除文件夹 ,如果是非空文件夹,参数2必须给值true fs.delete(new Path("/aaa"), true); // 重命名文件或文件夹 fs.rename(new Path("/a1"), new Path("/a2")); } /** * 查看目录信息,只显示文件 * * @throws IOException * @throws IllegalArgumentException * @throws FileNotFoundException */ @Test public void testListFiles() throws FileNotFoundException, IllegalArgumentException, IOException { // 思考:为什么返回迭代器,而不是List之类的容器 RemoteIterator while (listFiles.hasNext()) { LocatedFileStatus fileStatus = listFiles.next(); System.out.println(fileStatus.getPath().getName()); System.out.println(fileStatus.getBlockSize()); System.out.println(fileStatus.getPermission()); System.out.println(fileStatus.getLen()); BlockLocation[] blockLocatiOns= fileStatus.getBlockLocations(); for (BlockLocation bl : blockLocations) { System.out.println("block-length:" + bl.getLength() + "--" + "block-offset:" + bl.getOffset()); String[] hosts = bl.getHosts(); for (String host : hosts) { System.out.println(host); } } System.out.println("--------------为angelababy打印的分割线--------------"); } } /** * 查看文件及文件夹信息 * * @throws IOException * @throws IllegalArgumentException * @throws FileNotFoundException */ @Test public void testListAll() throws FileNotFoundException, IllegalArgumentException, IOException { FileStatus[] listStatus = fs.listStatus(new Path("/")); String flag = "d-- "; for (FileStatus fstatus : listStatus) { if (fstatus.isFile()) flag = "f-- "; System.out.println(flag + fstatus.getPath().getName()); } } } |
8
HDFS HA机制
HA即为High Availability(高可用),用于解决NameNode单点故障的问题。该特性通过以热备的方式为NameNode提供一个备用者,一旦主NameNode出现故障,可以很快切换到备用的NameNode,从而实现对外提供服务。
HA是为了解决单点问题,通过JN集群共享状态,通过ZKFC 选举active,监控状态,自动备援。
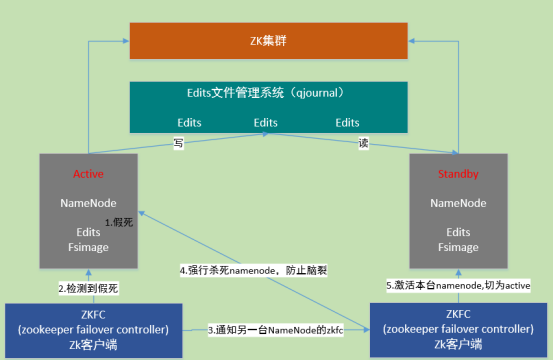
Active Namenode将数据写入共享文件管理系统,而StandbyNamenode监听该系统,一旦发现有新数据写入,则读取这些数据,并加载到自己内存中,以保证自己内存状态与Active NameNode保持基本一致。如此,在紧急情况下standby便可快速切为active namenode。
自动故障转移机制:
1. active Namenode宕机(假死)。
2. active Namenode zkfc检测到假死
3. 通知另一台namenode的zkfc
4. 另一台机机器强行杀死之前的active namenode
5. 激活standby namenode,切为active状态
4
MapReduce
1
MapReduce原理
Mapreduce是一个分布式运算程序的编程框架,是用户开发“基于hadoop的数据分析应用”的核心框架;
Mapreduce核心功能是将用户编写的业务逻辑代码和自带默认组件整合成一个完整的分布式运算程序,并发运行在一个hadoop集群上;
(1)海量数据在单机上处理因为硬件资源限制,无法胜任
(2)而一旦将单机版程序扩展到集群来分布式运行,将极大增加程序的复杂度和开发难度
(3)引入mapreduce框架后,开发人员可以将绝大部分工作集中在业务逻辑的开发上,而将分布式计算中的复杂性交由框架来处理
结构
一个完整的mapreduce程序在分布式运行时有三类实例进程:
1、MRAppMaster:负责整个程序的过程调度及状态协调
2、mapTask:负责map阶段的整个数据处理流程
3、ReduceTask:负责reduce阶段的整个数据处理流程
整体流程图

其中,maptask的数量是不能设置的,reducetask可以自己设置job.setNumReduceTasks(5);
流程解析
1.一个mr程序启动的时候,最先启动的是MRAppMaster,MRAppMaster启动后根据本次job的描述信息,计算出需要的maptask实例数量,然后向集群申请机器启动相应数量的maptask进程
2.maptask进程启动之后,根据给定的数据切片范围进行数据处理,主体流程为:
利用客户指定的inputformat来获取RecordReader读取数据,形成输入KV对
将输入KV对传递给客户定义的map()方法,做逻辑运算,并将map()方法输出的KV对收集到缓存
将缓存中的KV对按照K分区排序后不断溢写到磁盘文件
3.MRAppMaster监控到所有maptask进程任务完成之后,会根据客户指定的参数启动相应数量的reducetask进程,并告知reducetask进程要处理的数据范围(数据分区)
4.Reducetask进程启动之后,根据MRAppMaster告知的待处理数据所在位置,从若干台maptask运行所在机器上获取到若干个maptask输出结果文件,并在本地进行重新归并排序,然后按照相同key的KV为一个组,调用客户定义的reduce()方法进行逻辑运算,并收集运算输出的结果KV,然后调用客户指定的outputformat将结果数据输出到外部存储
maptask的并行度决定map阶段的任务处理并发度,进而影响到整个job的处理速度
那么,mapTask并行实例是否越多越好呢?其并行度又是如何决定呢?
一个job的map阶段并行度由客户端在提交job时决定
而客户端对map阶段并行度的规划的基本逻辑为:
将待处理数据执行逻辑切片(即按照一个特定切片大小,将待处理数据划分成逻辑上的多个split),然后每一个split分配一个mapTask并行实例处理
这段逻辑及形成的切片规划描述文件,由FileInputFormat实现类的getSplits()方法
1、切片定义在InputFormat类中的getSplit()方法
2、FileInputFormat中默认的切片机制:
· 简单地按照文件的内容长度进行切片
· 切片大小,默认等于block大小
· 切片时不考虑数据集整体,而是逐个针对每一个文件单独切片
比如待处理数据有两个文件:
file1.txt 320M file2.txt 10M |
经过FileInputFormat的切片机制运算后,形成的切片信息如下:
|
3、FileInputFormat中切片的大小的参数配置
通过分析源码,在FileInputFormat中,计算切片大小的逻辑:Math.max(minSize, Math.min(maxSize, blockSize)); 切片主要由这几个值来运算决定
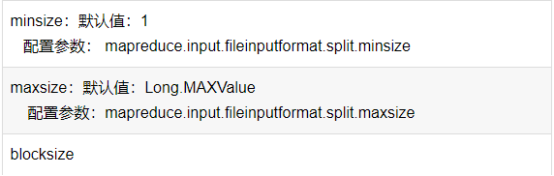
因此,默认情况下,切片大小=blocksize
maxsize(切片最大值):
参数如果调得比blocksize小,则会让切片变小,而且就等于配置的这个参数的值
minsize (切片最小值):
参数调的比blockSize大,则可以让切片变得比blocksize还大
选择并发数的影响因素: 1. 运算节点的硬件配置 2. 运算任务的类型:CPU密集型还是IO密集型 3. 运算任务的数据量 |
reducetask的并行度同样影响整个job的执行并发度和执行效率,但与maptask的并发数由切片数决定不同,Reducetask数量的决定是可以直接手动设置:
//默认值是1,手动设置为4
job.setNumReduceTasks(4);
如果数据分布不均匀,就有可能在reduce阶段产生数据倾斜
注意: reducetask数量并不是任意设置,还要考虑业务逻辑需求,有些情况下,需要计算全局汇总结果,就只能有1个reducetask
尽量不要运行太多的reduce task。对大多数job来说,最好rduce的个数最多和集群中的reduce持平,或者比集群的 reduce slots小。这个对于小集群而言,尤其重要。
Hadoop的发布包中内置了一个hadoop-mapreduce-example-2.4.1.jar,这个jar包中有各种MR示例程序,可以通过以下步骤运行:
启动hdfs,yarn
然后在集群中的任意一台服务器上启动执行程序(比如运行wordcount):
hadoop jar hadoop-mapreduce-example-2.4.1.jar wordcount /wordcount/data /wordcount/out
2
MapReduce实践篇
1. 用户编写的程序分成三个部分:Mapper,Reducer,Driver(提交运行mr程序的客户端)
2. Mapper的输入数据是KV对的形式(KV的类型可自定义)
3. Mapper的输出数据是KV对的形式(KV的类型可自定义)
4. Mapper中的业务逻辑写在map()方法中
5. map()方法(maptask进程)对每一个
6. Reducer的输入数据类型对应Mapper的输出数据类型,也是KV
7. Reducer的业务逻辑写在reduce()方法中
8. Reducetask进程对每一组相同k的
9. 用户自定义的Mapper和Reducer都要继承各自的父类
10. 整个程序需要一个Drvier来进行提交,提交的是一个描述了各种必要信息的job对象
需求:在一堆给定的文本文件中统计输出每一个单词出现的总次数
(1) 定义一个mapper类
//首先要定义四个泛型的类型 //keyin: LongWritable valuein: Text //keyout: Text valueout:IntWritable public class WordCountMapper extends Mapper //map方法的生命周期: 框架每传一行数据就被调用一次 //key : 这一行的起始点在文件中的偏移量 //value: 这一行的内容 @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { //拿到一行数据转换为string String line = value.toString(); //将这一行切分出各个单词 String[] words = line.split(" "); //遍历数组,输出<单词,1> for(String word:words){ context.write(new Text(word), new IntWritable(1)); } } } |
将单词作为key,次数1为value。以便于后续的数据分发,根据单词分发/相同的单词分到相同的reduce task
(2) 定义一个reducer类
//生命周期:框架每传递进来一个kv 组,reduce方法被调用一次 @Override protected void reduce(Text key, Iterable //定义一个计数器 int count = 0; //遍历这一组kv的所有v,累加到count中 for(IntWritable value:values){ count += value.get(); } context.write(key, new IntWritable(count)); } } |
(3) 定义一个主类,用来描述job并提交job
package cn.test.bigdata.mr.wcdemo; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.CombineTextInputFormat; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class WordcountDriver { public static void main(String[] args) throws Exception { Configuration cOnf= new Configuration(); //设置的没有用! ?????? //conf.set("HADOOP_USER_NAME", "hadoop"); //conf.set("dfs.permissions.enabled", "false"); //不提交在yarn上面,只在本地跑 conf.set("mapreduce.framework.name", "local"); //本地模式运行mr程序时,输入输出的数据可以在本地,也可以在hdfs上 //到底在哪里,酒宴以下两行配置,用的是哪行,默认是本地的 conf.set("fs.defaultFS", "file:///"); /*conf.set("fs.defaultFS", "hdfs://192.168.175.128:9000/"); conf.set("mapreduce.framework.name", "yarn"); conf.set("yarn.resoucemanager.hostname", "192.168.178.128");*/ Job job = Job.getInstance(conf); /*job.setJar("/home/hadoop/wc.jar");*/ //指定本程序的jar包所在的本地路径 job.setJarByClass(WordcountDriver.class); //指定本业务job要使用的mapper/Reducer业务类 job.setMapperClass(WordcountMapper.class); job.setReducerClass(WordcountReduce.class); //指定需要使用combiner,以及用哪个类作为combiner的逻辑 /*job.setCombinerClass(WordcountCombiner.class);*/ job.setCombinerClass(WordcountReduce.class); //如果不设置InputFormat,它默认用的是TextInputformat.class /*job.setInputFormatClass(CombineTextInputFormat.class); CombineTextInputFormat.setMaxInputSplitSize(job, 4194304); CombineTextInputFormat.setMinInputSplitSize(job, 2097152);*/ //指定mapper输出数据的kv类型 job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(IntWritable.class); //指定最终输出的数据的kv类型 job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); //指定job的输入原始文件所在目录 FileInputFormat.setInputPaths(job, new Path("D:\\wordstest\\input")); //指定job的输出结果所在目录 FileOutputFormat.setOutputPath(job, new Path("D:\\wordstest\\output")); //将job中配置的相关参数,以及job所用的java类所在的jar包,提交给yarn去运行 /*job.submit();*/ boolean res = job.waitForCompletion(true); System.exit(res?0:1); } } |
1. combiner是MR程序中Mapper和Reducer之外的一种组件
2. combiner组件的父类就是Reducer
3. combiner和reducer的区别在于运行的位置:
Combiner是在每一个maptask所在的节点运行
Reducer是接收全局所有Mapper的输出结果;
(4) combiner的意义就是对每一个maptask的输出进行局部汇总,以减小网络传输量
具体实现步骤:
1. 自定义一个combiner继承Reducer,重写reduce方法
2. 在job中设置:job.setCombinerClass(CustomCombiner.class)
(5) combiner能够应用的前提是不能影响最终的业务逻辑
而且,combiner的输出kv应该跟reducer的输入kv类型要对应起来
3
MapReduce原理篇
mapreduce中,map阶段处理的数据如何传递给reduce阶段,是mapreduce框架中最关键的一个流程,这个流程就叫shuffle;
shuffle: 洗牌、发牌——(核心机制:数据分区,排序,缓存);
具体来说:就是将maptask输出的处理结果数据,分发给reducetask,并在分发的过程中,对数据按key进行了分区和排序;

shuffle是MR处理流程中的一个过程,它的每一个处理步骤是分散在各个map task和reduce task节点上完成的,整体来看,分为3个操作:
1. 分区partition
2. Sort根据key排序
3. Combiner进行局部value的合并

1. maptask收集我们的map()方法输出的kv对,先进入分区方法,把数据标记好分区,然后把数据发送到内存缓冲区(默认100M)中
2. 当环形缓冲区达到80%时,进行溢写,从内存缓冲区不断溢出本地磁盘文件,可能会溢出多个文件 (溢写前对数据进行快速排序,排序按照key的索引进行字典顺序排序)
3. 多个溢出文件会被合并成大的溢出文件(归并排序算法),对溢写的文件也可以进行combiner操作,前提是汇总操作,求平均值不行。
4. 在溢出过程中,及合并的过程中,都要调用partitoner进行分组和针对key进行排序
5. reducetask根据自己的分区号,去各个maptask机器上取相应的结果分区数据,拉取的数据先存储在内存中,内存不够了,再存储到磁盘。
6. reducetask会取到同一个分区的来自不同maptask的结果文件,reducetask会将这些文件再进行合并(归并排序)
7. 合并成大文件后,shuffle的过程也就结束了,后面进入reducetask的逻辑运算过程(从文件中取出一个一个的键值对group,调用用户自定义的reduce()方法)
Shuffle中的缓冲区大小会影响到mapreduce程序的执行效率,原则上说,缓冲区越大,磁盘io的次数越少,执行速度就越快
缓冲区的大小可以通过参数调整, 参数:io.sort.mb 默认100M
4.3.2 mapreduce中的序列化
概述
Java的序列化是一个重量级序列化框架(Serializable),一个对象被序列化后,会附带很多额外的信息(各种校验信息,header,继承体系。。。。),不便于在网络中高效传输;
所以,hadoop自己开发了一套序列化机制(Writable),精简,高效
5
YARN
Yarn是一个资源调度平台,负责为运算程序提供服务器运算资源,相当于一个分布式的操作系统平台,而mapreduce等运算程序则相当于运行于操作系统之上的应用程序
1
YARN的重要概念
yarn并不清楚用户提交的程序的运行机制
yarn只提供运算资源的调度(用户程序向yarn申请资源,yarn就负责分配资源)
yarn中的主管角色叫ResourceManager
yarn中具体提供运算资源的角色叫NodeManager
这样一来,yarn其实就与运行的用户程序完全解耦,就意味着yarn上可以运行各种类型的分布式运算程序(mapreduce只是其中的一种),比如mapreduce、storm程序,spark程序,tez ……
所以,spark、storm等运算框架都可以整合在yarn上运行,只要他们各自的框架中有符合yarn规范的资源请求机制即可
Yarn就成为一个通用的资源调度平台,从此,企业中以前存在的各种运算集群都可以整合在一个物理集群上,提高资源利用率,方便数据共享
2
YARN命令
yarn application -kill application_id
yarn logs -applicationId application_id
3
YARN的资源调度流程
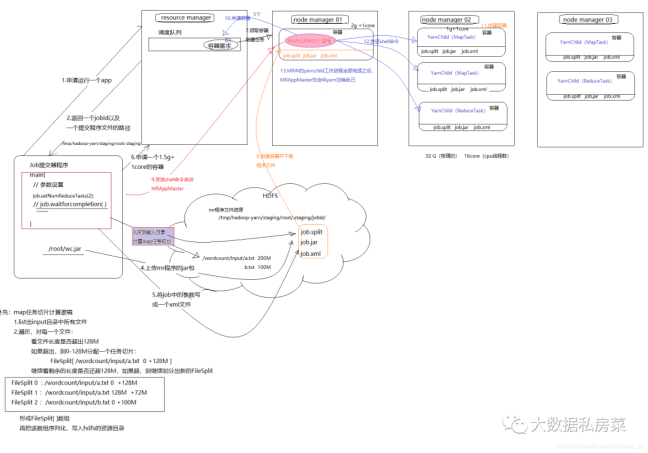
1. 用户向YARN 中提交应用程序, 其中包括ApplicationMaster 程序、启动ApplicationMaster 的命令、用户程序等。
2. ResourceManager 为该应用程序分配第一个Container, 并与对应的NodeManager 通信,要求它在这个Container 中启动应用程序的ApplicationMaster。
3. ApplicationMaster 首先向ResourceManager 注册, 这样用户可以直接通过ResourceManage 查看应用程序的运行状态,然后它将为各个任务申请资源,并监控它的运行状态,直到运行结束,即重复步骤4~7。
4. ApplicationMaster 采用轮询的方式通过RPC 协议向ResourceManager 申请和领取资源。
5. 一旦ApplicationMaster 申请到资源后,便与对应的NodeManager 通信,要求它启动任务。
6. NodeManager 为任务设置好运行环境(包括环境变量、JAR 包、二进制程序等)后,将任务启动命令写到一个脚本中,并通过运行该脚本启动任务。
7. 各个任务通过某个RPC 协议向ApplicationMaster 汇报自己的状态和进度,以让ApplicationMaster 随时掌握各个任务的运行状态,从而可以在任务失败时重新启动任务。在应用程序运行过程中,用户可随时通过RPC 向ApplicationMaster 查询应用程序的当前运行状态。
8. 应用程序运行完成后,ApplicationMaster 向ResourceManager 注销并关闭自己。
6
HADOOP面试题精选
进群方式:请加微信(微信号:dataclub_bigdata),回复:数据,通过审核会拉你进群。
(备注:行业-职位-城市)

福利时刻
01. 后台回复「数据」,即可领取大数据经典资料。
02. 后台回复「转型」,即可传统数据仓库转型大数据必学资料。
03. 后台回复「加群」,或添加一哥微信ID:dataclub_bigdata 拉您入群(大数据|数仓|分析)或领取资料。

!关注不迷路~ 各种福利、资源定期分享!
你点的每个在看,我都认真当成了喜欢










 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有 
