作者:rannman | 来源:互联网 | 2024-10-14 18:07
文章目录一.实验目的二.实验内容三.实验步骤及结果分析 1.基于ubuntukylin14.04(7)版本,安装hadoop-eclipse-kepler-plugi
文章目录
- 一. 实验目的
- 二. 实验内容
- 三. 实验步骤及结果分析
- 1. 基于ubuntukylin14.04(7)版本,安装hadoop-eclipse-kepler-plugin-2.6.0.jar
- 1.1 安装hadoop-eclipse-plugin
- 1.2 配置hadoop-eclipse-plugin
- 2. 基于ubuntukylin14.04(8)版本,通过eclipse完成MapReduce编程实践
- 2.1 通过eclipse操作HDFS文件
- 2.2 通过eclipse创建MapReduce项目
- 2.3 通过eclipse运行MapReduce
一. 实验目的
掌握MapReduce编程实践技术。
二. 实验内容
1) 基于ubuntukylin14.04(7)版本,安装hadoop-eclipse-kepler-plugin-2.6.0.jar,形成ubuntukylin14.04(8)版本。
2) 基于ubuntukylin14.04(8)版本,通过eclipse完成MapReduce编程实践。
参考:http://dblab.xmu.edu.cn/blog/hadoop-build-project-using-eclipse/
三. 实验步骤及结果分析
1. 基于ubuntukylin14.04(7)版本,安装hadoop-eclipse-kepler-plugin-2.6.0.jar
版本说明:ubuntukylin14.04(7)=hadoop集群(hadoop2.6.0版本)+hbase伪分布式(hbase1.1.2版本)
注:hadoop-eclipse-plugin下载地址为: https://github.com/winghc/hadoop2x-eclipse-plugin
1.1 安装hadoop-eclipse-plugin
首先下载插件,然后输入unzip -qo ~/下载/hadoop2x-eclipse-plugin-master.zip -d ~/下载命令将其解压到下载目录,然后输入sudo cp ~/下载/hadoop2x-eclipse-plugin-master/release/hadoop-eclipse-plugin-2.6.0.jar /opt/eclipse/plugins/命令将hadoop-eclipse-kepler-plugin-2.6.0.jar复制到ecljpse安装目录的plugins文件夹中。然后输入/opt/eclipse/eclipse -clean命令启动eclipse使插件生效。




1.2 配置hadoop-eclipse-plugin
首先输入start-dfs.sh、start-yarn.sh、mr-jobhistory-daemon.sh start historyserver三个命令启动Hadoop集群,然后启动eclipse。
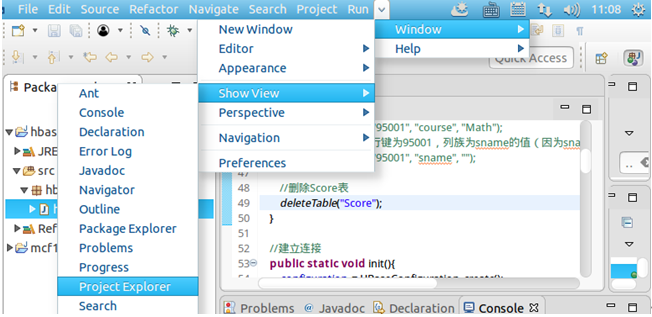
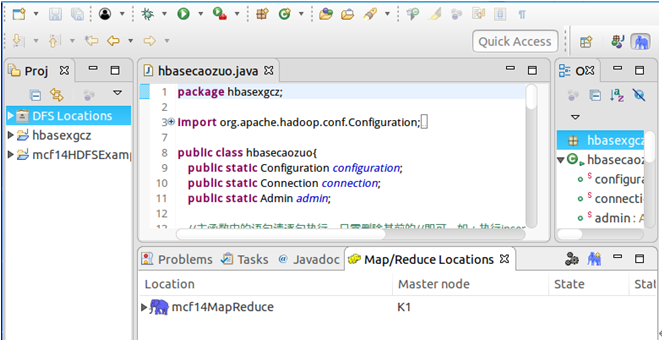
点击导航栏Windows→Show View→Project Explorer,在左侧就会显示出DFS Locations。
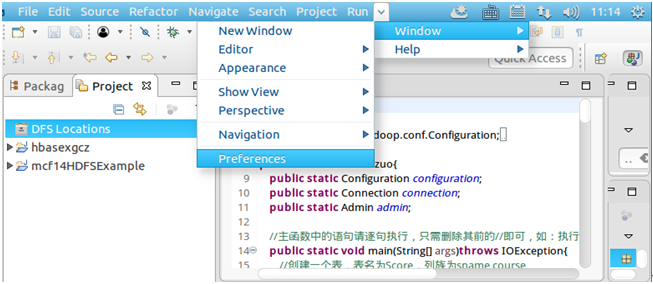
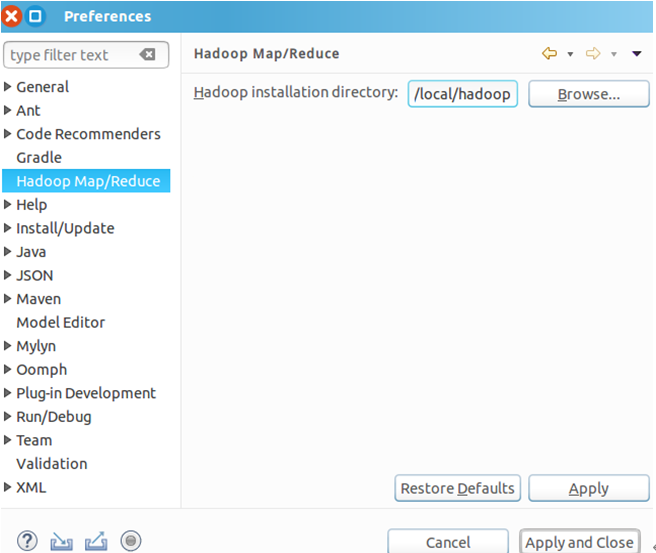
然后点击导航栏Windows→Preferences→左侧Hadoop Map/Reduce→在Hadoop installation directory中填写Hadoop的安装地址/usr/local/hadoop→Apply and Close。
然后点击导航栏Windows→Perspective→Open Perspective→Other→Map/Reduce→Open,就会在控制台下方显示Map/Reduce Locations面板。
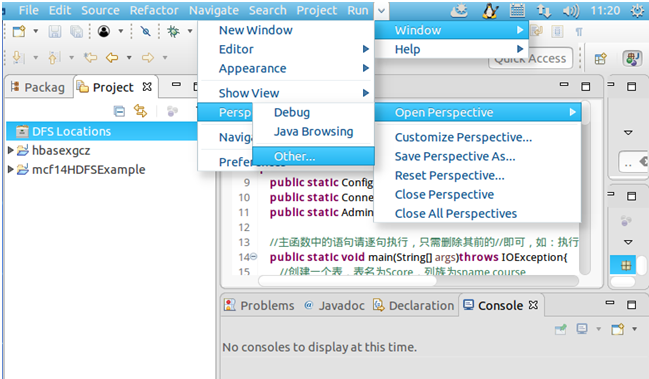
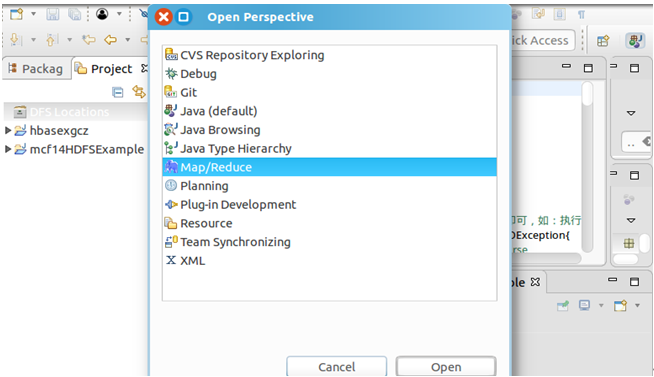
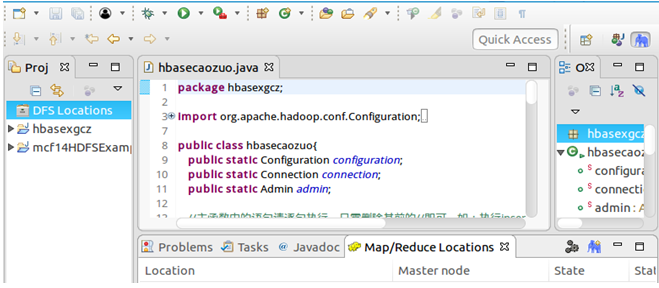
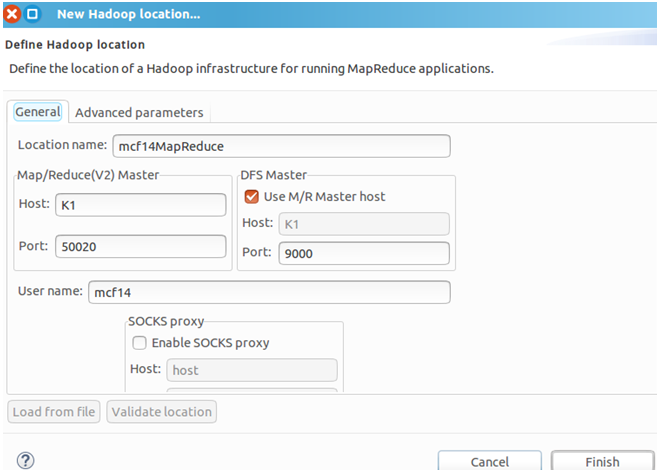
在Map/Reduce Locations面板中右击→New Hadoop location…→Location name自定义→Map/Reduce(V2)Master的Host为K1、Port默认→DFS Master的Port为9000→User name默认→Finish。其中,因为我的Hadoop是集群式,设置的fs.defaultFS为hdfs://K1:9000,所以DFS Maser要与其对应。

2. 基于ubuntukylin14.04(8)版本,通过eclipse完成MapReduce编程实践
版本说明:ubuntukylin14.04(8) =hadoop集群(hadoop2.6.0版本)+hbase伪分布式(hbase1.1.2版本)+安装好hadoop-eclipse-kepler-plugin-2.6.0.jar
2.1 通过eclipse操作HDFS文件
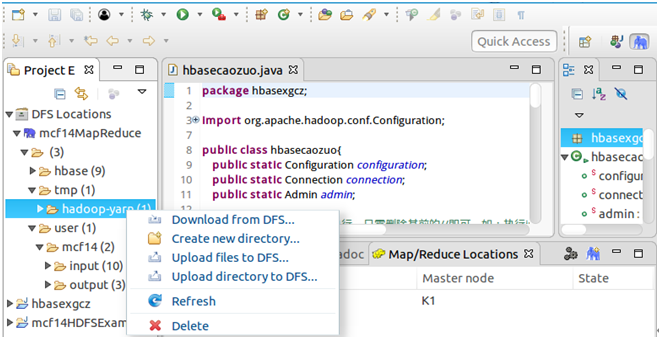
确保已经启动了Hadoop集群,然后打开eclipse,此时展开左侧DFS Locations就可以查看HDFS中的文件,然后可以通过右键进行上传、下载、删除等操作,不用再通过繁琐的hdfs dfs -ls等命令进行操作。
2.2 通过eclipse创建MapReduce项目
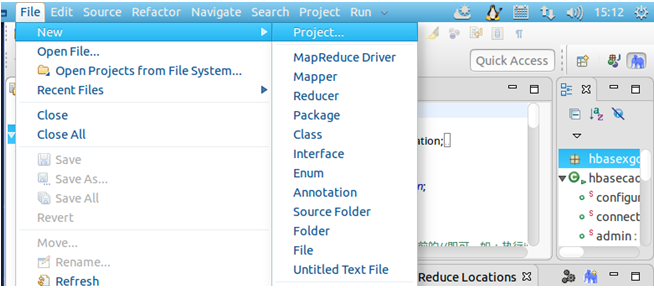
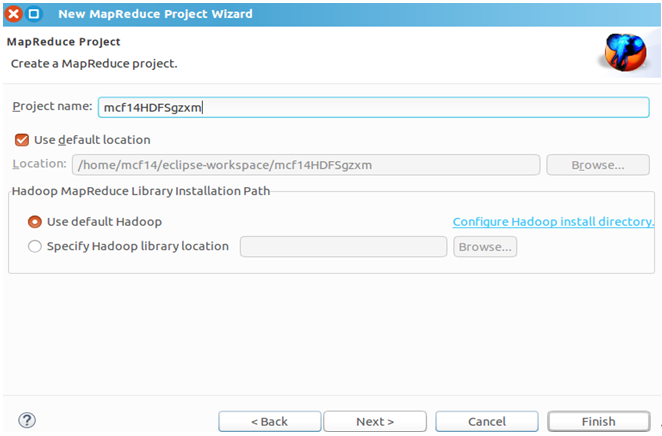
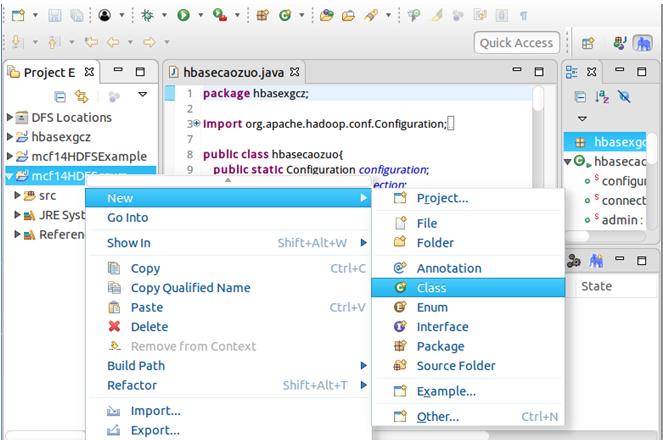
点击导航栏File→New→Project…→选中Map/Reduce Project→Next→Project name为mcf14HDFSgzxm→Finish,然后在左侧就能看到创建的项目了。

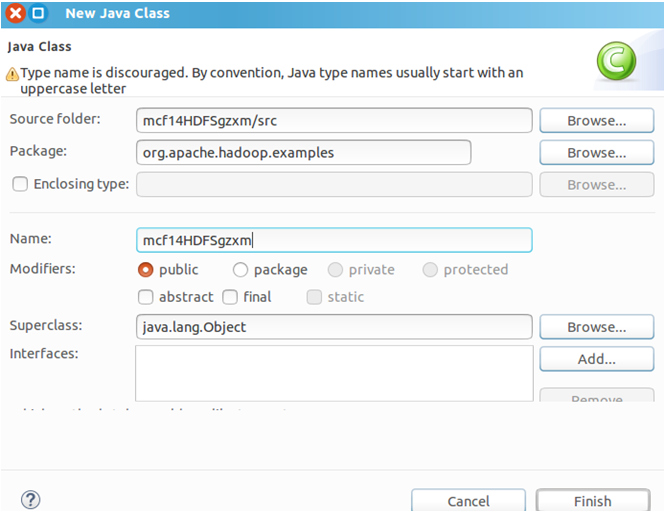
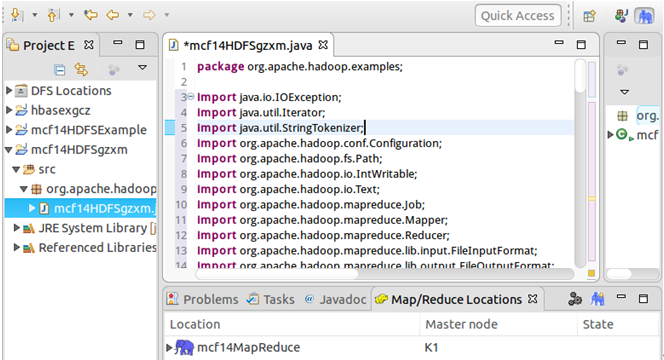
右击mcf14HDFSgzxm项目→New→Class→Package改为org.apache.hadoop.examples→Name为mcf14HDFSgzxm→Finish,就会自动创建mcf14HDFSgzxm.java文件(代码见文末),在其中写入代码。
2.3 通过eclipse运行MapReduce
复制配置文件解决参数设置问题。在终端输入cp /usr/local/hadoop/etc/hadoop/{core-site.xml,hdfs-site.xml,log4j.properties} ~/eclipse-workspace/mcf14HDFSgzxm/src命令将/usr/local/hadoop/etc/hadoop中修改过的三个配置文件core-site.xml、hdfs-site.xml和log4j.properties复制到mcf14HDFSgzxm项目下的src文件夹即~/eclipse-workspace/mcf14HDFSgzxm/src中,然后可输入ls ~/eclipse-workspace/mcf14HDFSgzxm/src命令进行查看。

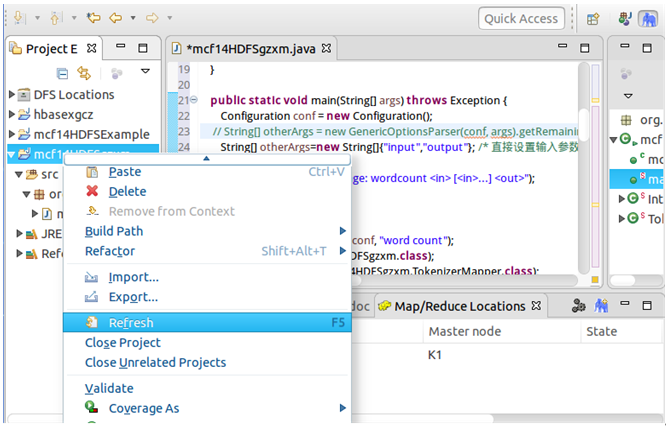
右击mcf14HDFSgzxm项目,点击Refresh进行刷新,会看到复制进去的文件。然后运行代码就会在控制台输出运行结果,在DFS Locations的output中也能查看结果。
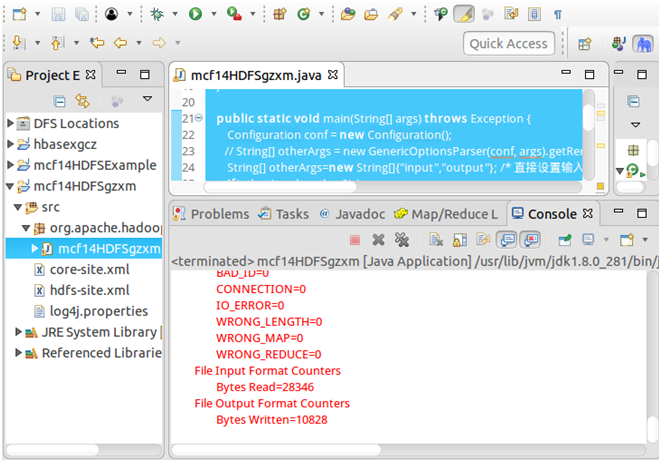
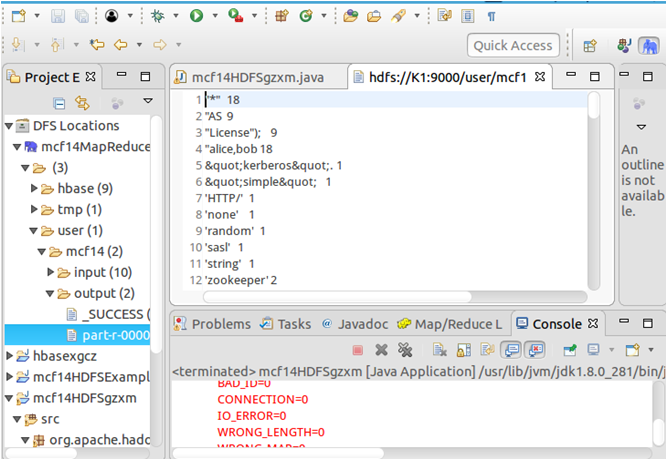
mcf14HDFSgzxm.java代码:
import java.io.IOException;
import java.util.Iterator;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;public class mcf14HDFSgzxm {public mcf14HDFSgzxm() {}public static void main(String[] args) throws Exception {Configuration conf &#61; new Configuration();String[] otherArgs&#61;new String[]{"input","output"}; if(otherArgs.length < 2) {System.err.println("Usage: wordcount [...] ");System.exit(2);}Job job &#61; Job.getInstance(conf, "word count");job.setJarByClass(mcf14HDFSgzxm.class);job.setMapperClass(mcf14HDFSgzxm.TokenizerMapper.class);job.setCombinerClass(mcf14HDFSgzxm.IntSumReducer.class);job.setReducerClass(mcf14HDFSgzxm.IntSumReducer.class);job.setOutputKeyClass(Text.class);job.setOutputValueClass(IntWritable.class);for(int i &#61; 0; i < otherArgs.length - 1; &#43;&#43;i) {FileInputFormat.addInputPath(job, new Path(otherArgs[i]));}FileOutputFormat.setOutputPath(job, new Path(otherArgs[otherArgs.length - 1]));System.exit(job.waitForCompletion(true)?0:1);}public static class IntSumReducer extends Reducer<Text, IntWritable, Text, IntWritable> {private IntWritable result &#61; new IntWritable();public IntSumReducer() {}public void reduce(Text key, Iterable<IntWritable> values, Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException {int sum &#61; 0;IntWritable val;for(Iterator i$ &#61; values.iterator(); i$.hasNext(); sum &#43;&#61; val.get()) {val &#61; (IntWritable)i$.next();}this.result.set(sum);context.write(key, this.result);}}public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable> {private static final IntWritable one &#61; new IntWritable(1);private Text word &#61; new Text();public TokenizerMapper() {}public void map(Object key, Text value, Mapper<Object, Text, Text, IntWritable>.Context context) throws IOException, InterruptedException {StringTokenizer itr &#61; new StringTokenizer(value.toString());while(itr.hasMoreTokens()) {this.word.set(itr.nextToken());context.write(this.word, one);}}}
}











 京公网安备 11010802041100号
京公网安备 11010802041100号