作者:城隍山人因 | 来源:互联网 | 2023-08-27 19:50
篇首语:本文由编程笔记#小编为大家整理,主要介绍了Hadoop入门之hdfs相关的知识,希望对你有一定的参考价值。
大数据技术开篇之Hadoop入门【hdfs】
学习都是从了解到熟悉的过程,而学习一项新的技术的时候都是从这个技术是什么?可以干什么?怎么用?如何优化?这几点开始。今天这篇文章分为两个部分。一、hadoop概述 二、hadoop核心技术之一的hdfs的讲解。
【hadoop概述】
一、hadoop是什么?
Hadoop是一个由Apache基金会所开发的分布式系统基础架构。用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行高速运算和存储。Hadoop实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS。HDFS有高容错性的特点,并且设计用来部署在低廉的(low-cost)硬件上;而且它提供高吞吐量(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。HDFS放宽了(relax)POSIX的要求,可以以流的形式访问(streaming access)文件系统中的数据。Hadoop的框架最核心的设计就是:HDFS和MapReduce。HDFS为海量的数据提供了存储,而MapReduce则为海量的数据提供了计算。
简单概况就是hadoop是一个分布式系统的基础架构,通过分布式来进行高速运算和存储。
二、用来干什么?
主要用来解决海量数据存储和海量数据运算的问题
三、当前版本
Apach 版本:主要用于自己学习研究方面,免费开源版本
Cloudera:收费版本,企业版本。目前公司商用化最多的版本。
Hortonworks:商业版本,这个版本的优势在于参考文档相对详尽,学习起来比较方便
四、hadoop组成
commons:辅助工具
hdfs:一个分布式高吞吐量,高可靠的分布式文件系统
mapreduce 一个分布式离线计算框架
yarn:作业调度和资源管理的框架。
五、集群模式
单节点模式,伪集群,完整集群。三个模式
HDFS 学习
一、hdfs是什么?
hdfs一个分布式高吞吐量,高可靠的分布式文件系统。
二、hdfs优缺点:
优点:
【1】高容错性,数据自动保存多个副本,一个副本丢失后可以自动恢复
【2】适合大数据的处理
数据可以达到gb,Tb,pb级别,文件处理可以达到百万以上的规模
【3】可以构建在廉价的机器上面,通过多副本来实现可靠性
缺点:
【1】不适合低延时数据访问,比如毫秒级别做不到
【2】无法高效对大量小文件进行存储
【3】不支持文件的随机修改,仅支持文件的追加
三、hdfs的组成:
Client:客户端
【1】文件切分。文件上传时将文件切成一个个block块
【2】与NameNode交互,获取文件的位置信息
【3】与DataNode交互,读取或写入数据
【4】client提供一些命令来管理Hdfs,比如启动或者关闭
【5】client可以通过命令来访问Hdfs
NameNode就是Master,它是一个主管、管理者
【1】管理数据块的原信息
【2】配置副本策略
【3】处理客户端请求
DateNode
【1】存储实际的数据块
【2】执行数据块的读写操作
econdaryNameNode:并非NameNode的热备。当NameNode挂掉的时候,它并不能马上替换NameNode并提供服务
【1】辅助NameNode,分担其工作量
【2】定期合并Fsimage和Edits,并推送给NameNode;
【3】在紧急情况下,可辅助恢复NameNode。
四、hdfs文件写入流程
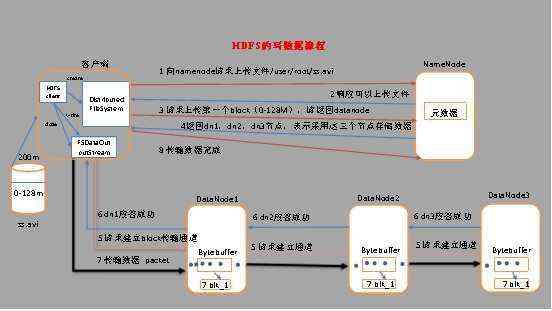
(1) 客户端通过Distributed FileSystem模块向NameNode请求上传文件,NameNode检查目标文件是否已存在,父目录是否存在。
(2) NameNode返回是否可以上传。
(3) 客户端请求第一个 block上传到哪几个datanode服务器上。
(4) NameNode返回3个datanode节点,分别为dn1、dn2、dn3。
(5) 客户端通过FSDataOutputStream模块请求dn1上传数据,dn1收到请求会继续调用dn2,然后dn2调用dn3,将这个通信管道建立完成。
(6) dn1、dn2、dn3逐级应答客户端。
(7) 客户端开始往dn1上传第一个block(先从磁盘读取数据放到一个本地内存缓存),以packet为单位,dn1收到一个packet就会传给dn2,dn2传给dn3;
(8) 当一个block传输完成之后,客户端再次请求NameNode上传第二个block的服务器。(重复执行3-7步)。
五、hdfs 读文件流程
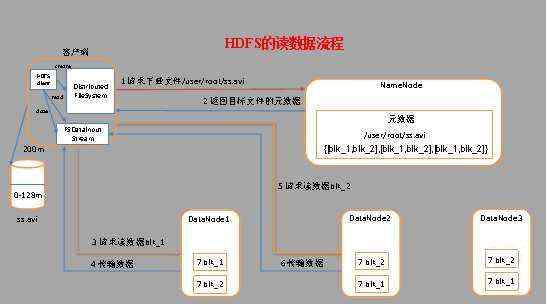
(1) 客户端通过Distributed FileSystem向NameNode请求下载文件,NameNode通过查询元数据,找到文件块所在的DataNode地址。
(2) 挑选一台DataNode(就近原则,然后随机)服务器,请求读取数据。
(3) DataNode开始传输数据给客户端(从磁盘里面读取数据输入流,以packet为单位来做校验)。
(4) 客户端以packet为单位接收,先在本地缓存,然后写入目标文件。
六、NN与2NN的工作机制
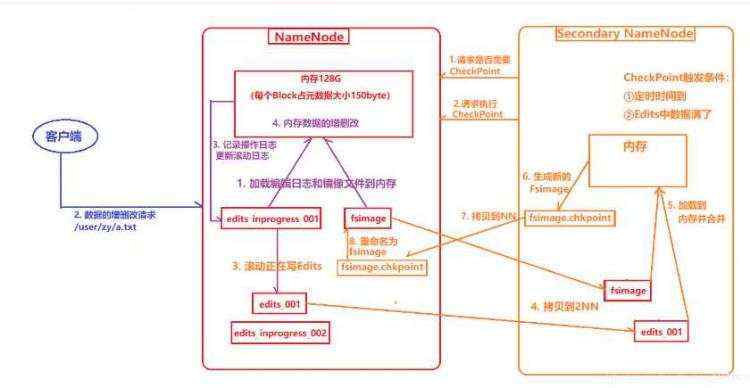
(1) 第一阶段:NameNode启动
a) 第一次启动NameNode格式化后,创建fsimage和edits文件。如果不是第一次启动,直接加载编辑日志和镜像文件到内存。
b) 客户端对元数据进行增删改的请求。
c) NameNode记录操作日志,更新滚动日志。
d) NameNode在内存中对数据进行增删改查。
(2) 第二阶段:Secondary NameNode工作
a) Secondary NameNode询问NameNode是否需要checkpoint。直接带回NameNode是否检查结果。
b) Secondary NameNode请求执行checkpoint。
c) NameNode滚动正在写的edits日志。
d) 将滚动前的编辑日志和镜像文件拷贝到Secondary NameNode。
e) Secondary NameNode加载编辑日志和镜像文件到内存,并合并。
f) 生成新的镜像文件fsimage.chkpoint。
g) 拷贝fsimage.chkpoint到NameNode。
h) NameNode将fsimage.chkpoint重新命名成fsimage。
NN和2NN工作机制详解:
fsimage:namenode内存中元数据序列化后形成的文件。
edits:记录客户端更新元数据信息的每一步操作(可通过Edits运算出元数据)。
namenode启动时,先滚动edits并生成一个空的edits.inprogress,然后加载edits(归档后的)和fsimage(最新的)到内存中,此时namenode内存就持有最新的元数据信息。client开始对namenode发送元数据的增删改查的请求,这些请求的操作首先会被记录在edits.inprogress中(查询元数据的操作不会被记录在edits中,因为查询操作不会更改元数据信息),如果此时namenode挂掉,重启后会从edits中读取元数据的信息。然后,namenode会在内存中执行元数据的增删改查的操作。
由于edits中记录的操作会越来越多,edits文件会越来越大,导致namenode在启动加载edits时会很慢,所以需要对edits和fsimage进行合并(所谓合并,就是将edits和fsimage加载到内存中,照着edits中的操作一步步执行,最终形成新的fsimage)。Secondarynamenode:帮助namenode进行edits和fsimage的合并工作。
secondarynamenode首先会询问namenode是否需要checkpoint(触发checkpoint需要满足两个条件中的任意一个,定时时间到和edits中数据写满了)。直接带回namenode是否检查结果。secondarynamenode执行checkpoint操作,首先会让namenode滚动edits并生成一个空的edits.inprogress,滚动edits的目的是给edits打个标记,以后所有新的操作都写入edits.inprogress,其他未合并的edits和fsimage会拷贝到secondarynamenode的本地,然后将拷贝的edits和fsimage加载到内存中进行合并,生成fsimage.chkpoint,然后将fsimage.chkpoint拷贝给namenode,重命名为fsimage后替换掉原来的fsimage。namenode在启动时就只需要加载之前未合并的edits和fsimage即可,因为合并过的edits中的元数据信息已经被记录在fsimage中。
六、DataName工作机制
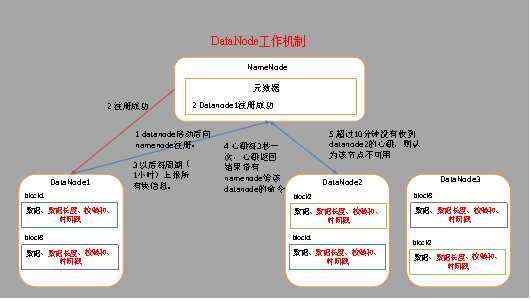
(1) 一个数据块在DataNode上以文件形式存储在磁盘上,包括两个文件,一个是数据本身,一个是元数据包括数据块的长度,块数据的校验和,以及时间戳。
(2) DataNode启动后向NameNode注册,通过后,周期性(1小时)的向NameNode上报所有的块信息。
(3) 心跳是每3秒一次,心跳返回结果带有NameNode给该DataNode的命令如复制块数据到另一台机器,或删除某个数据块。如果超过10分钟没有收到某个DataNode的心跳,则认为该节点不可用。
今天的hdfs的分享就到这里了,下次会分享MapReduce和Yarn的知识。每天进步一点点,大家一起加油。















 京公网安备 11010802041100号
京公网安备 11010802041100号