作者:王小瑶p_35ps | 来源:互联网 | 2023-07-12 12:34
如果有天堂,天堂应该是图书馆的模样。 –博尔赫斯
主要内容:Hadoop、hive、HBASE、zookeeper、MySQL、sqoop、kafka(有时间补)、日志
一、什么是hadoop Apache Hadoop是处理大数据的一种新方法
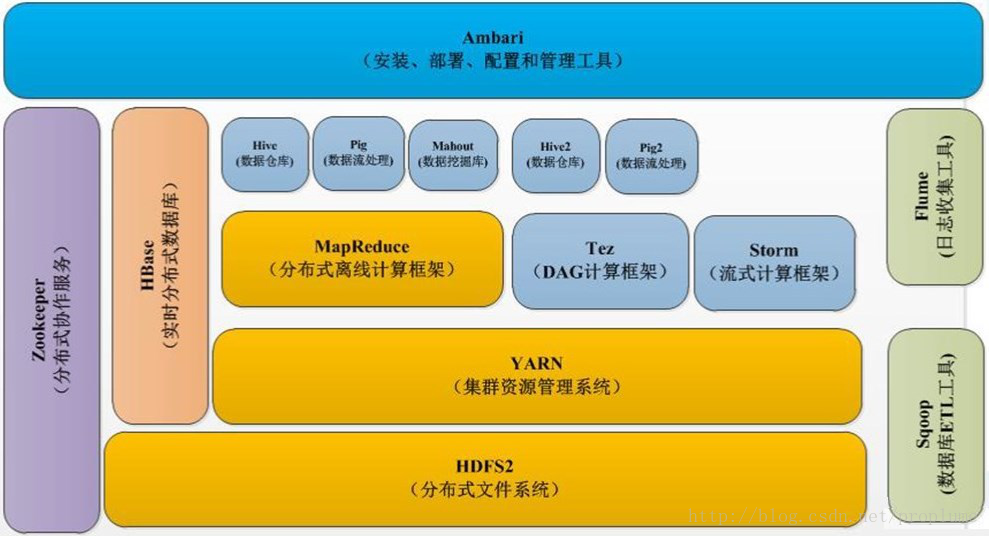
二、Hadoop框架
三、sqoop 1、ETL是啥??
Extraction-Transformation-Loading的缩写,中文名为数据抽取、转换和加载
2、那Sqoop(数据库ETL工具)用来干嘛的?
先了解现代数据存储系统如何运作(本少侠还不清楚),一些数据可能不适于存储在关系数据库中,因为大部分数据需要按照原始形式存储。向数据库中添加数据的前提是先把数据转变成一个可以加载到数据库的预定的模式,这一步骤被称为提取、转换和加载(ETL),会消耗时间和成本(是真的…贼长…)。最重要的是,关于数据如何使用的决定必须在ETL步骤中间作出。此外,一些数据经常在ETL步骤中被丢弃,因为它不能放入数据模式或被认为不需要。
例子:
a.使用Sqoop将数据从Hive导入MySQL
前提: 启动Hadoop集群、MySQL服务
命令:
字段解释:
./bin/sqoop export ##表示数据从 hive 复制到 mysql 中
b.使用Sqoop将数据从MySQL导入HBase
前提: 启动Hadoop集群、MySQL服务、HBase服务
命令:
3、更多:
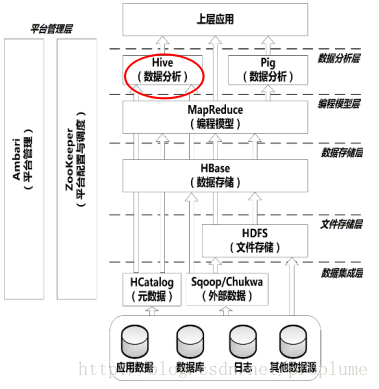
四、数据仓库hive 1、Hive位置
2、数据仓库和数据库有啥区别(一直好奇)
数据库是面向事务的设计,数据仓库是面向主题设计的。
3、数据仓库用来干嘛呢
个人理解最简单的回答,对历史数据的分析和整理就是数据仓库。
4、数据仓库hive
Hive数据存储格式的两个维度:
Apache Hive是建立在hadoop之上的数据仓库,使用称为HiveQL,类似SQL语言,提供大数据集的数据汇总、即时查询和分析
官网介绍:
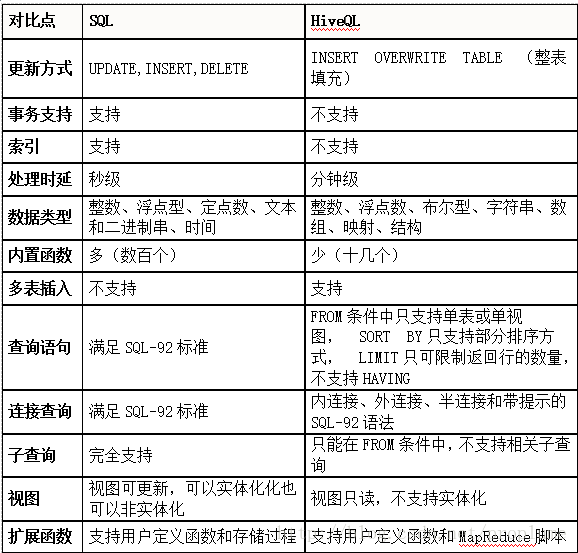
5、SQL和HiveQL这么像,比较一番
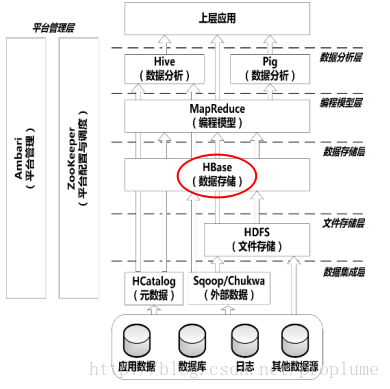
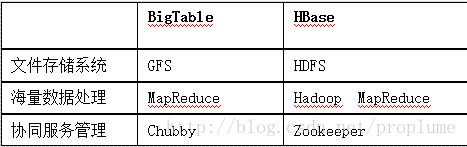
五、HBase实时分布式数据库 1、HBase是什么?
同样先看下所处位置:
HBase是一个高性能的分布式数据库,主要适用于海量明细数据(十亿、百亿)的随机实时查询,如日志明细、交易清单、轨迹行为等;
2、HBase模型概述
HBase类似数据库中的表,具有行和列。不同于关系数据库基于行模式存储。HBase是基于列存储的,列被分组为列族,每个列族都由几个文件保存,不同列族的文件是分离的,所有列族都一起存储在物理文件系统中。
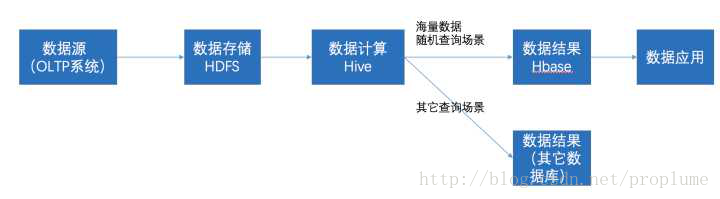
3、HBase与hive关系
在大数据架构中,Hive和HBase是协作关系,数据流一般如下图:
(1)通过ETL工具将数据源抽取到HDFS存储;
六、关于日志 安装过程中各种错,来一波日志:
2、出了问题,首先查看系统日志,根据提示排查问题
3、如果系统日志看起来没问题,接着检查hadoop服务和应用程序日志。跟着错误的性质,查看对应的hadoop服务日志的方向,例如,如有一个hdfs有问题,那么就查看在NameNode和数据节点上的日志,而非yarn资源管理器或者节点管理器日志。
4、日志不一定在标准日志位置(/var/log)。日志文件的位置在服务的XML配置文件中设置
5、默认,hadoop系统日志文件是累积的,所以确保查看的是日志末尾。日志由log4j包管理
6、两种模式日志存储
日志聚合(好像还不清楚是啥)时可在yarn资源管理器用户界面(http://192.168.237.147:8088 或50070)中显示或yarn logs命令查看
未使用日志聚合,日志存放于本地,位置:yarn-site.xml文件中的yarn.nodemanager.log-dirs属性中。
七、参考 《写给大忙人的Hadoop2》 作者:Douglas Eadline(美)著 卢涛 李颖 译







 京公网安备 11010802041100号
京公网安备 11010802041100号