作者:爱得诱惑a_920 | 来源:互联网 | 2023-07-08 16:21
Hadoop权威指南读书笔记–入门前言在大学里曾经使用过Nutch,实现了一个简单的搜索引擎。工作之后,公司里有同事使用Lucene来做站内搜索。这些年伴随着大数据的兴起,Hado
Hadoop 权威指南读书笔记 – 入门
前言
在大学里曾经使用过Nutch,实现了一个简单的搜索引擎。工作之后,公司里有同事使用Lucene来做站内搜索。这些年伴随着大数据的兴起,Hadoop已经成为了静态数据处理的标准,号称性能更优且可以处理
流式数据的Spark也发展得如火如荼。记得那时候搜索引擎还是一个高端的技术,是一种非常神秘的存在,能够从纷繁复杂的数据海洋中精确地找到用户想要的信息,这确实能够直观地体现技术的价值。这些年
过去之后,发现搜索这个词不见了,更为的是智能推送。从你希望系统告诉你什么,变成了系统知道你需要什么,这是一步很大的跨越,相信将来没有大数据处理的概念,因为大数据处理是基本的技术。
Hadoop的历史
Hadoop 并不是从石头里面蹦出来的,而是从其他项目演化过来的。其中有两个项目不得不提-Lucene和Nutch。
Lucene其实是一个提供全文文本搜索的函数库,它不是一个应用软件。它提供很多API函数,是一个开放源代码的全文检索引擎工具包,让你可以运用到各种实际应用程序中。它提供了完整的查询引擎和索引引擎
以及部分的文本分析功能。Lucene的目的是为软件开发人员提供一个简单易用的工具包,以方便的在目标系统中实现全文检索的功能,或者是以此为基础建立起完整的全文检索引擎。
Nutch是一个建立在Lucene核心之上的Web搜索的实现,它是一个真正的应用程序。也就是说,你可以直接下载下来拿过来用。它在Lucene的基础上加了网络爬虫和一些和Web相关的内容。其目的就是想从一个
简单的站内索引和搜索推广到全球网络的搜索上,就像Google和Yahoo一样。
Hadoop 是一个分布式计算的基础架构,用户在不需要了解底层细节的情况下,开发分布式的应用。Hadoop 最重要的是实现了一个分布式的文件系统,这样的文件系统可以架构在价格低廉的集群之上。
另外一个重要内容就是MapReduce,一种分布式任务处理的架构。这两个部分构成了Hadoop的基石,Hadoop在创新在于从以前的以应用为中心,转变为以数据为中心。以前是应用获取数据进行处理,现在是将
计算任务发送给数据,然后进行处理。
它主要有以下几个优点:
1. 高可靠性。Hadoop按位存储和处理数据的能力值得人们信赖。
2. 高扩展性。Hadoop是在可用的计算机集簇间分配数据并完成计算任务的,这些集簇可以方便地扩展到数以千计的节点中。
3. 高效性。Hadoop能够在节点之间动态地移动数据,并保证各个节点的动态平衡,因此处理速度非常快。
4. 高容错性。Hadoop能够自动保存数据的多个副本,并且能够自动将失败的任务重新分配。
5. 低成本。与一体机、商用数据仓库以及QlikView、Yonghong Z-Suite等数据集市相比,hadoop是开源的,项目的软件成本因此会大大降低。
Hadoop 也是由诸多的子项目构成的,下面是组成Hadoop的核心项目:
1. HDFS: Hadoop分布式文件系统(Distributed File System) - HDFS (Hadoop Distributed File System)
2. MapReduce:并行计算框架,0.20前使用 org.apache.hadoop.mapred 旧接口,0.20版本开始引入org.apache.hadoop.mapreduce的新API
3. HBase: 类似Google BigTable的分布式NoSQL列数据库。(HBase和Avro已经于2010年5月成为顶级 Apache 项目)
4. Hive:数据仓库工具,由Facebook贡献。
5. Zookeeper:分布式锁设施,提供类似Google Chubby的功能,由Facebook贡献。
6. Avro:新的数据序列化格式与传输工具,将逐步取代Hadoop原有的IPC机制。
7. Pig: 大数据分析平台,为用户提供多种接口。
8. Ambari:Hadoop管理工具,可以快捷的监控、部署、管理集群。
9. Sqoop:于在HADOOP与传统的数据库间进行数据的传递。
HDFS
HDFS 绝对是Hadoop的创举,因为要对大批量的数据进行处理,如果采取集中的方式,那么一定会受限于计算资源的限制,必须采取分布式的架构,利用分而治之的思想才能将负载分发到整个集群中去,分布式
文件系统就应运而生了。分布式的存储使得文件存放在众多的节点上,而只需要一个节点去记录这些文件的元数据信息(主要是文件的位置),在访问文件的时候,先访问这个元数据节点,获取文件所在的位置,
然后再获取文件。用户不必关心文件存储在哪个节点上,而且由于分布式存储已经解决了高可用的问题,所以用户不必担心数据存储的可用性。
HDFS的设计思想来源于谷歌的GFS(Google File System),Google发布的MapReduce论文中提出了基本的框架,在HDFS中得到了充分的体现。HDFS中的文件默认保存三份,所以一份丢失不会造成数据丢失,可以
根据另外两份恢复回来。HDFS存储数据的基本单元是块(Block),大小为64M。

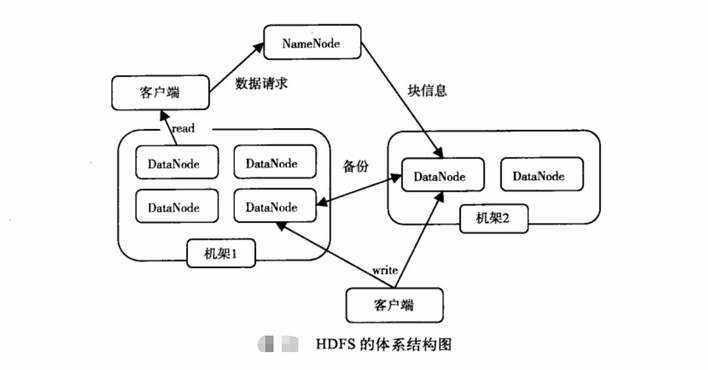
HDFS 有两种Node,一种是NameNode,负责记录具体数据的元数据信息,另一种是DataNode,真正的数据节点。这里的NameNode有两个,另一个主要作用是分担主NameNode的一部分工作负载。每一个文件的副本
存储在不同的节点上,可以通过配置,让HDFS感知机架,这样副本会存储在不通的机架上,即使整个机架坏掉,数据也是可以恢复的。不同副本之间的数据复制由HDFS负责。在NameNode和DataNode之间维持着心跳
NameNode能够感知DataNode的状态,DataNode变得不可用,会启用副本复制。
MapReduce
从请求处理的流程来看,数据写入时,数据会在不同机架上的节点上进行写入。数据读取的时候,NameNode会查找这个数据的块信息,根据这些信息去相应节点上获取数据,返回给客户端。创建文件时,先在NameNode
上创建文件,然后写入数据到DataNode,数据在DataNode之间进行复制,写入成功后,返回信息给NameNode,确认文件创建成功后,记录文件的相关信息(存储位置等等)。
MapReduce 是一种分而治之的思想,谷歌在论文中提出的这种思想成为了后来分布式任务处理的标准。Map是映射,Reduce则是归约,对于输入的数据来说,先需要分片,然后通过Map对数据进行处理,处理的结果是k/v
这个k/v是针对每个map接收到的分片进行的操作,每一个map操作输出至少一个key/value对,根据map的key对map的输出先进行合并,每一个key对应一个reduce,各个reduce做各自的处理。
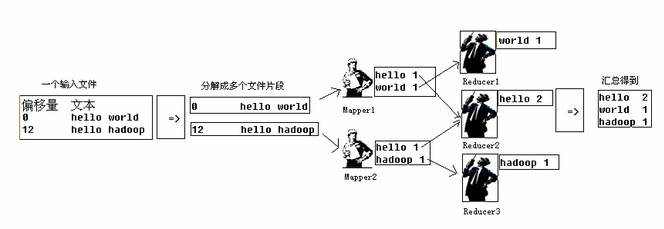
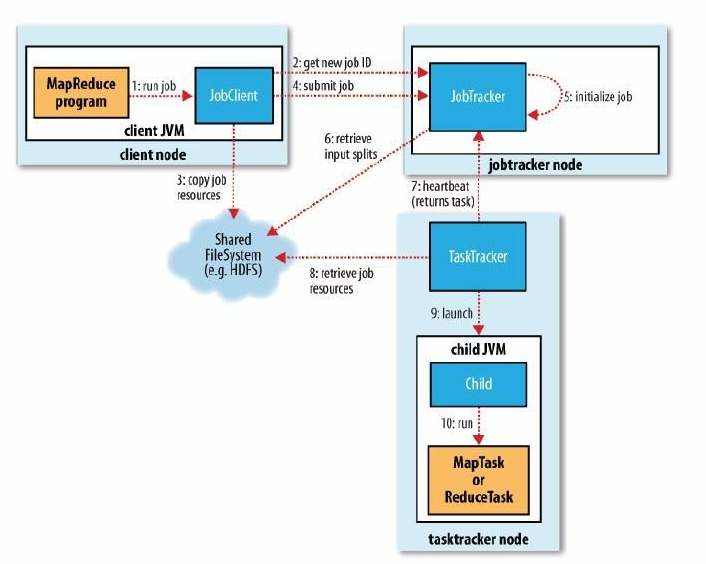
MapReduce由JobTracker接收用户提交的Job,然后下发任务到各个节点上,由节点上的Task Tracker负责具体执行。当然这只是一个大概的流程,实际情况下会有更多具体的细节。这个例子中,我们可以看出Map和
Reduce的原理。Map对每一个接收到的内容做相同的处理,即记录每个单词的次数,然后列一个清单进行输出,在进入到Reduce之前有一个合并key的过程,即将各个Map输出的相同的Key进行合并(shuffle),这个过程
汇总所有Map输出的Key和Value,汇总之后的key就是最终reduce的输入的key,那么value则很可能是多个值的集合,因为map合并的时候,相同的key作为一个key,但是value会存入一个数组作为这个key的value。
每个Reduce从Map的输出中获取数据,然后汇总每个key对应的值,最终多个Reduce的结果再做一次汇总就输出为最终的内容。在整个过程中,只有map操作和reduce操作是用户需要关系的,其他的部分全部交给Hadoop。
通俗易懂的例子
在讲到MapReduce时,总是会讲到wordcount的例子,之后再想想,貌似脑海里又不清晰了。网上有个人分享了一个扑克牌分类的例子,非常贴切。
需要在一堆扑克牌(张数未知)中统计四种花色的牌有多少张,只需要找几个人,每人给一堆,数出来四种花色的张数,然后汇总给另外一个人就可以了。比如两个人每人一堆扑克牌,查出红桃、黑桃、梅花、方片之
后四个人,每个人只负责统计一种花色,最终将结果汇报给一个人,这是典型的map-reduce模型。
细节探讨
在Map之前,数据会被分片(split),分片的结果决定了map的个数,那么分片的机制如何呢?
Hadoop 2.x默认的block大小是128MB,Hadoop 1.x默认的block大小是64MB,可以在hdfs-site.xml中设置dfs.block.size,注意单位是byte。
分片大小范围可以在mapred-site.xml中设置,mapred.min.split.size mapred.max.split.size,minSplitSize大小默认为1B,maxSplitSize大小默认为Long.MAX_VALUE = 9223372036854775807
在我们没有设置分片的范围的时候,分片大小是由block块大小决定的,和它的大小一样。比如把一个258MB的文件上传到HDFS上,假设block块大小是128MB,那么它就会被分成三个block块,与之对应产生三个split,所以最终会产生三个map task。我又发现了另一个问题,第三个block块里存的文件大小只有2MB,而它的block块大小是128MB,那它实际占用Linux file system的多大空间?答案是实际的文件大小,而非一个块的大小。
这篇文章讲解比较详细:MapReduce Input Split(输入分/切片)详解
hadoop的核心思想是MapReduce,但shuffle又是MapReduce的核心。shuffle的主要工作是从Map结束到Reduce开始之间的过程。首先看下这张图,就能了解shuffle所处的位置。图中的partitions、copy phase、sort phase所代表的就是shuffle的不同阶段。
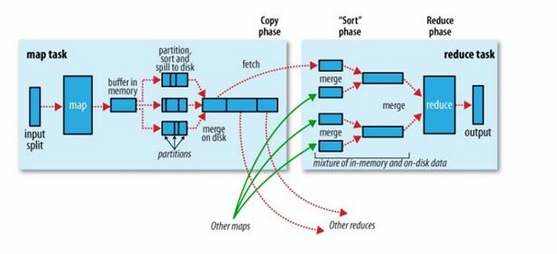
shuffle阶段又可以分为Map端的shuffle和Reduce端的shuffle。
1.Map端的shuffle
Map端会处理输入数据并产生中间结果,这个中间结果会写到本地磁盘,而不是HDFS。每个Map的输出会先写到内存缓冲区中,当写入的数据达到设定的阈值时,系统将会启动一个线程将缓冲区的数据写到磁盘,这个过程叫做spill。
在spill写入之前,会先进行二次排序,首先根据数据所属的partition进行排序,然后每个partition中的数据再按key来排序。partition的目是将记录划分到不同的Reducer上去,以期望能够达到负载均衡,以后的Reducer就会根据partition来读取自己对应的数据。接着运行combiner(如果设置了的话),combiner的本质也是一个Reducer,其目的是对将要写入到磁盘上的文件先进行一次处理,这样,写入到磁盘的数据量就会减少。最后将数据写到本地磁盘产生spill文件(spill文件保存在{mapred.local.dir}指定的目录中,Map任务结束后就会被删除)。
最后,每个Map任务可能产生多个spill文件,在每个Map任务完成前,会通过多路归并算法将这些spill文件归并成一个文件。至此,Map的shuffle过程就结束了。
2.Reduce端的shuffle
Reduce端的shuffle主要包括三个阶段,copy、sort(merge)和reduce。
首先要将Map端产生的输出文件拷贝到Reduce端,但每个Reducer如何知道自己应该处理哪些数据呢?因为Map端进行partition的时候,实际上就相当于指定了每个Reducer要处理的数据(partition就对应了Reducer),所以Reducer在拷贝数据的时候只需拷贝与自己对应的partition中的数据即可。每个Reducer会处理一个或者多个partition,但需要先将自己对应的partition中的数据从每个Map的输出结果中拷贝过来。
接下来就是sort阶段,也称为merge阶段,因为这个阶段的主要工作是执行了归并排序。从Map端拷贝到Reduce端的数据都是有序的,所以很适合归并排序。最终在Reduce端生成一个较大的文件作为Reduce的输入。
最后就是Reduce过程了,在这个过程中产生了最终的输出结果,并将其写到HDFS上。
总结
Hadoop 的数据处理过程的细节在实际项目中进行运用时,才会真正体会到深刻的原理,希望能遇到更多的有价值的实例。本篇借鉴了很多有价值的博客内容,在此表示感谢。
部分内容引用自:
1.Nutch和Lucene的区别
Nutch和Lucene的区别
2.hadoop运行原理之shuffle
hadoop运行原理之shuffle
来自:feng1456
本文由 feng1456 发布于Hadoop 核心概念解析






 京公网安备 11010802041100号
京公网安备 11010802041100号