Hadoop的安装方式有三种模式:单机模式(Standalong Mode)、伪分布模式(Pseudo-Distributed Mode)、完全分布式模式(Fully-Distributed Mode)。
Java进程。单机模式的特点是:没有分布式文件系统,直接在本地操作系统的文件系统读写;不需要加载任何Hadoop的守护进程。它一般用于本地MapReduce程序的调试。单机模式是Hadoop的默认模式。Java进程,模仿完全分布式的各类节点。伪分布式模式具备完全分布式的主要功能,常用于调试程序。Hadoop运行在多台机器中,各个机器按照相关配置运行相应的Hadoop守护进程。完全分布式模式是真正的分布式环境,用于实际的生产环境。Hadoop 是 一个用 Java 语言实现的开源软件框架,Hadoop的核心就是HDFS、MapReduce和YARN。HDFS为海量数据提供了存储,MapReduce为海量数据提供了计算框架,YARN把计算框架与资源管理彻底分离,统一管理计算框架的资源调度。安装Hadoop所需软件列表如下:
相关软件包地址:阿里云盘
| 软件类型 | 名称 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
虚拟机是一种虚拟化技术,它能实现在现有的操作系统上多运行一个或多个操作系统。本课程采用WMware公司的虚拟机软件WMware Workstation Pro 14版本,并安装CentOS7操作系统。
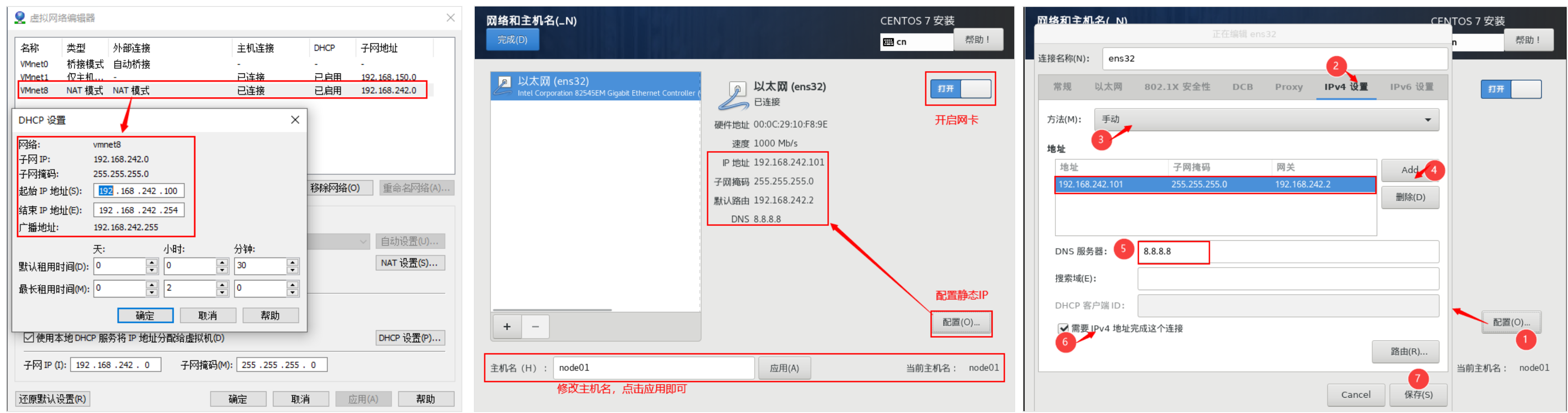
如果不关闭CentOS操作系统的防火墙(firewalld),则可能会出现以下几种情况:
Hadoop HDFS的Web管理界面Hive程序)出现假死状态systemctl status firewalld # 查看防火墙状态
systemctl stop firewalld # 关闭防火墙(临时)
systemctl start firewalld # 开启防火墙
systemctl disable firewalld # 禁用防火墙(永久)
通过VMware Workstation工具操作虚拟机十分不方便,无法复制内容到虚拟机中,也无法开启多个虚拟机窗口进行操作,并且在实际工作中,服务器通常被放置在机房中,同时受到地域和管理的限制,实际开发是通过远程连接服务器进行相关操作。接下来,我们来配置SSH 实现远程登录和免密登录。
在配置SSH之前,需要完成 主机IP地址的映射操作 vim /etc/hosts
[root@node01 ~]# rpm -qa | grep openssh # 查看当前虚拟机是否安装 Open SSH , 如果没有则执行 yum install openssh-server 命令在线安装 OpenSSH
openssh-server-7.4p1-21.el7.x86_64
openssh-7.4p1-21.el7.x86_64
openssh-clients-7.4p1-21.el7.x86_64
[root@node01 ~]# systemctl status sshd # 查看当前虚拟机是否开启 Open SSH 服务 , 如果没有则通过 systemctl sshd start 命令开启 OpenSSH 服务
● sshd.service - OpenSSH server daemonLoaded: loaded (/usr/lib/systemd/system/sshd.service; enabled; vendor preset: enabled)Active: active (running) since 三 2022-02-23 14:42:52 CST; 14min agoDocs: man:sshd(8)man:sshd_config(5)Main PID: 890 (sshd)CGroup: /system.slice/sshd.service└─890 /usr/sbin/sshd -D2月 23 14:42:51 node01 systemd[1]: Starting OpenSSH server daemon...
2月 23 14:42:52 node01 sshd[890]: Server listening on 0.0.0.0 port 22.
2月 23 14:42:52 node01 sshd[890]: Server listening on :: port 22.
2月 23 14:42:52 node01 systemd[1]: Started OpenSSH server daemon.
2月 23 14:51:17 node01 sshd[1229]: Accepted password for root from 192.168.197.1 port 9073 ssh2
2月 23 14:51:17 node01 sshd[1233]: Accepted password for root from 192.168.197.1 port 9077 ssh2
通过
MobaXterm远程连接工具,输入IP地址、用户名和密码进行连接测试
配置SSH免密钥登录功能的具体操作步骤如下:
ssh-keygen -t rsa命令生成密钥(根据提示可以不用输入任何内容,连续按4次Enter键确认即可)。node01的root目录下生成一个包含密钥文件的.ssh隐藏目录。通过执行cd /root/.ssh命令进入.ssh隐藏目录,在该目录下执行ll -a命令查看当前目录下的所有文件内容,id_rsa和id_rsa.pub文件分别是虚拟机node01的私钥文件和公钥文件。node01执行vim /etc/hosts命令编辑映射文件hosts,分别将虚拟机node01、node02和node03的IP和主机名进行匹配映射。node01上执行ssh-copy-id 主机名命令,将公钥复制到相关联的虚拟机(包括自身)。node01上执行ssh node02命令连接虚拟机node02,进行验证免密钥登录操作,此时无需输入密码便可以直接登录到虚拟机node02进行操作,如需返回node01,执行exit命令即可。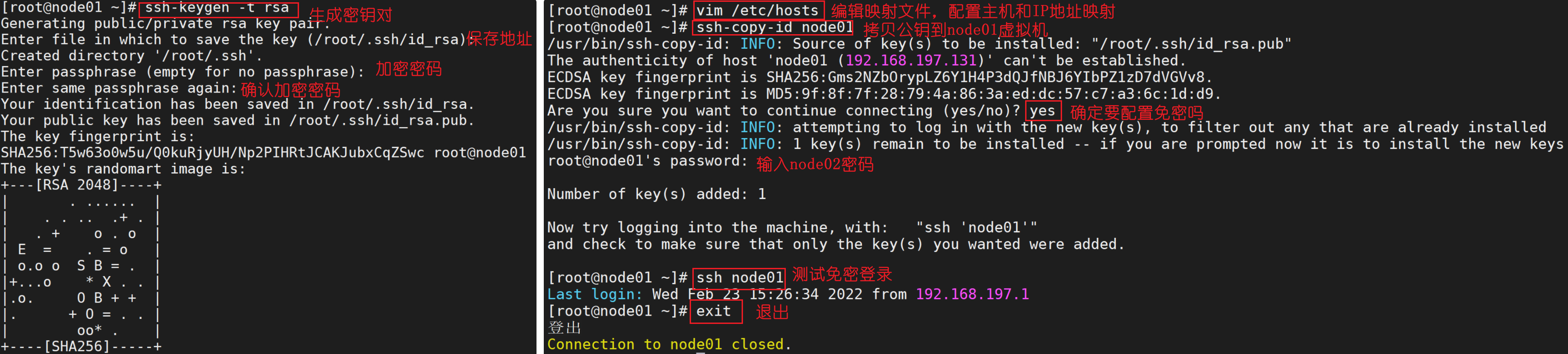
由于Hadoop是 一个用 Java 语言实现的开源软件框架,运行需要Java环境的支持,所以在部署Hadoop前需要在虚拟机中提前安装好JDK,具体操作步骤如下:
Oracle官网下载Linux x64操作系统的JDK安装包 jdk-8u161-linux-x64.tar.gzMobaXterm远程连接工具连接虚拟机node,进入Linux操作系统中存放应用安装包的目录/usr/local,勾选左侧的跟踪终端文件夹将JDK安装包上传到该目录下JDK,将JDK安装到存放应用的目录/usr/local,并重命名为jdkvim ~/.bash_profile 命令编辑系统环境变量文件.bash_profilejava -version命令查看JDK版本,验证虚拟机 node 中的JDK环境# 解压 tar 包到当前目录
[root@node local]# tar -zxvf jdk-8u111-linux-x64.tar.gz
#文件夹重命名
[root@node local]# mv jdk1.8.0_111/ jdk
# 配置 jdk 环境变量
[root@node local]# vim + ~/.bash_profile
export JAVA_HOME=/usr/local/jdk
export PATH=$PATH:$JAVA_HOME/bin
# 重新加载 环境变量文件,使配置生效
[root@node local]# source ~/.bash_profile
# 测试配置是否OK
[root@node local]# java –version
Hadoop单机模式没有HDFS,只能测试MapReduce程序。MapReduce处理的是本地Linux的文件数据。官方软件下载地址
Hadoop安装包,下载版本为Hadoop2.7.3,上传到Linux系统的/usr/local目录下,并解压到当前目录。Hadoop配置文件,修改hadoop-env.sh文件,配置JAVA_HOME真实环境路径。Hadoop,在本机运行MapReduce WordCount例子。# 解压 tar 包到当前目录
[root@node01 local]# tar -zxvf hadoop-2.7.3.tar.gz
#文件夹重命名
[root@node01 local]# mv hadoop-2.7.3 hadoop
# 配置 hadoop 环境变量
[root@node01 local]# vim + ~/.bash_profile
export HADOOP_HOME=/usr/local/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
# 重新加载 环境变量文件,使配置生效
[root@node01 local]# source ~/.bash_profile
# 准备测试MapReduce程序的数据文件
[root@node01 ~]# mkdir ~/input
[root@node01 ~]# cd ~/input
[root@node01 ~]# vim data.txt # yum install -y vim
Hello World
Hello Hadoop
# 运行MapReduce WordCount案例
[root@node01 ~]# cd ~/hadoop/share/hadoop/mapreduce
[root@node01 ~]# hadoop jar hadoop-mapreduce-examples-2.7.3.jar wordcount ~/input/data.txt ~/output
# 采用下面命令查看结果
[root@node01 ~]# cd ~/output
[root@node01 ~]# cat part-r-00000
Hadoop 1
Hello 2
World 1
官方Hadoop环境搭建教程 伪分布式其实是完全分布式的一种特例,但它只有一个节点,安装伪分布式模式所需要修改的文件、属性名称、属性值及含义如下所示:
| 文件名称 | 属性名称 | 属性值 | 含义 |
|
|
|
| 指定 |
|
|
|
| 配置 |
|
|
|
| |
|
|
|
| 副本数,默认是 |
|
|
|
| 配置集群模式为 |
|
|
| |
|
|
|
|
|
node为Linux操作系统的映射地址,通过修改/etc/hosts进行配置,也可以使用IP地址代替
hadoop-env.sh|mapred-env.sh|yarn-env.sh 设置 Hadoop 环境对应的 JDKexport JAVA_HOME=/usr/local/jdk
core-site.xml 配置文件hdfs-site.xml 配置文件slaves 配置文件# 替换 slaves 中的节点名称
[root@node local]# echo node > /usr/local/hadoop/etc/hadoop/slaves
# 格式化 HDFS ,由于已经配置过 Hadoop 的 bin 环境变量,则该命令可以在任意目录下运行
[root@node local]# hdfs namenode -format # 启动 HDFS 分布式文件系统 - 启动 namenode 元数据节点,负责管理文件切片存储
[root@node local]# hadoop-daemon.sh start namenode # 启动 datanode 副本节点,负责存储文件切片,定时发送心跳和块状态报告
[root@node local]# hadoop-daemon.sh start datanode# 启动 secondarynamenode 镜像备份节点,同步元数据和操作日志
[root@node local]# hadoop-daemon.sh start secondarynamenode # 查看所有 java 进程,验证 HDFS 的节点是否启动成功
[root@node local]# jps
12176 DataNode
12085 NameNode
12270 SecondaryNameNode
12318 Jps
HDFS 分布式文件系统启动,可以使用一个统一命令 :
[root@node local]# start-dfs.sh,格式化失败,解决办法,停止集群,删除HDFS配置的data目录与临时目录下面的所有数据,重新格式化
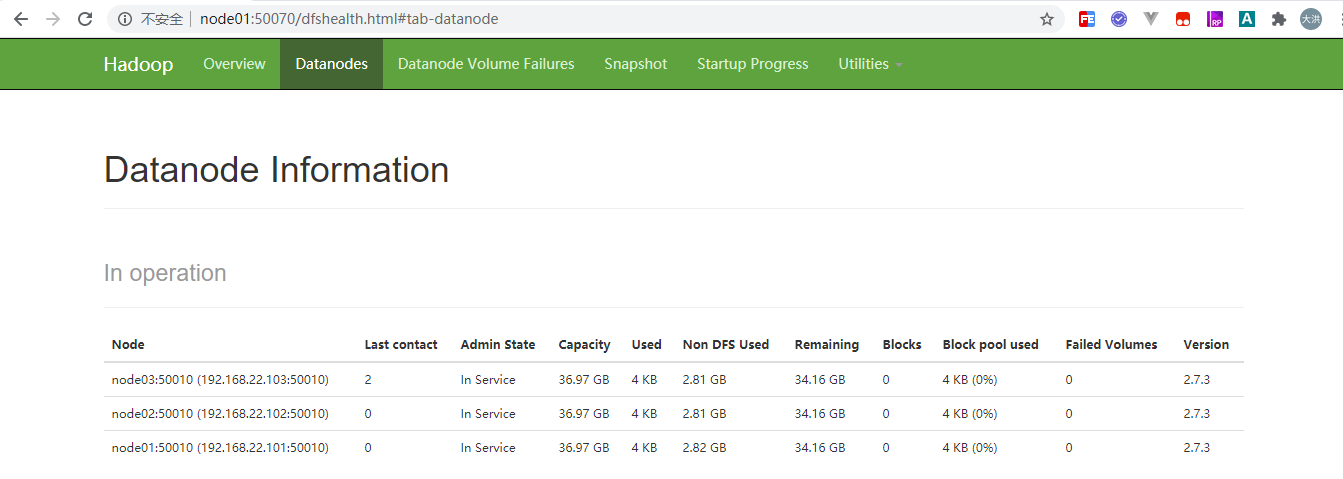
HDFS 提供了Web 管理界面,可以很方便地查看HDFS 相关信息,在浏览器地址栏中输入HDFS 的NameNode 的Web 访问地址,默认端口是 50070,YARN的Web管理界面,默认端口号为8088
可以使用 IP 地址访问 HDFS Web ,也可使用之前在 window 系统中配置的 C:\Windows\System32\drivers\etc\hosts 映射名称 node
使用 Hadoop2.7.3和 jdk1.8 搭建3个节点的完全分布式一个namenode,3个datanode,集群规划如下:
| 主机名 | IP地址 | 服务进程 |
|
|
|
|
|
|
|
|
|
|
|
|
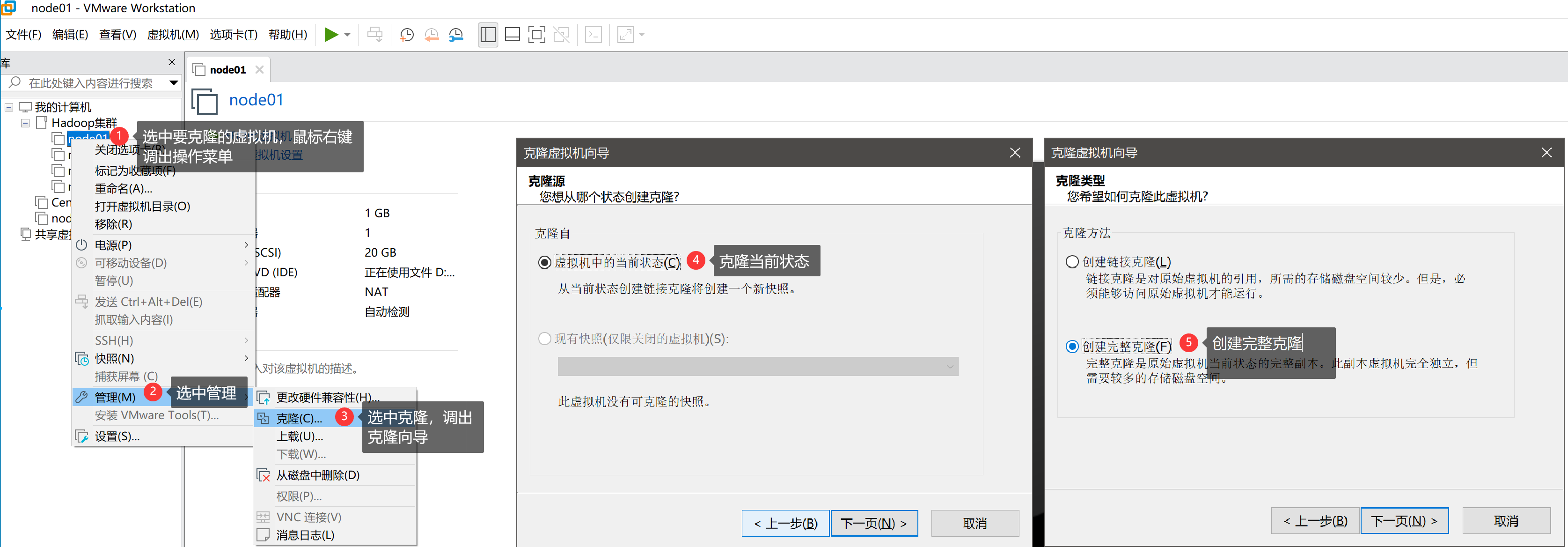
使用 VMware 工具克隆3个虚拟机,分别命名为node01、node02和node03,用于集群配置,注意:克隆需要先把节点关机
[root@node01 local]# poweroff
打开 VMware ,在关机状态,选中要克隆的节点,右键--> 管理 --> 克隆 , 或者直接找到要克隆的节点所在磁盘文件夹,直接复制三个个也可以。
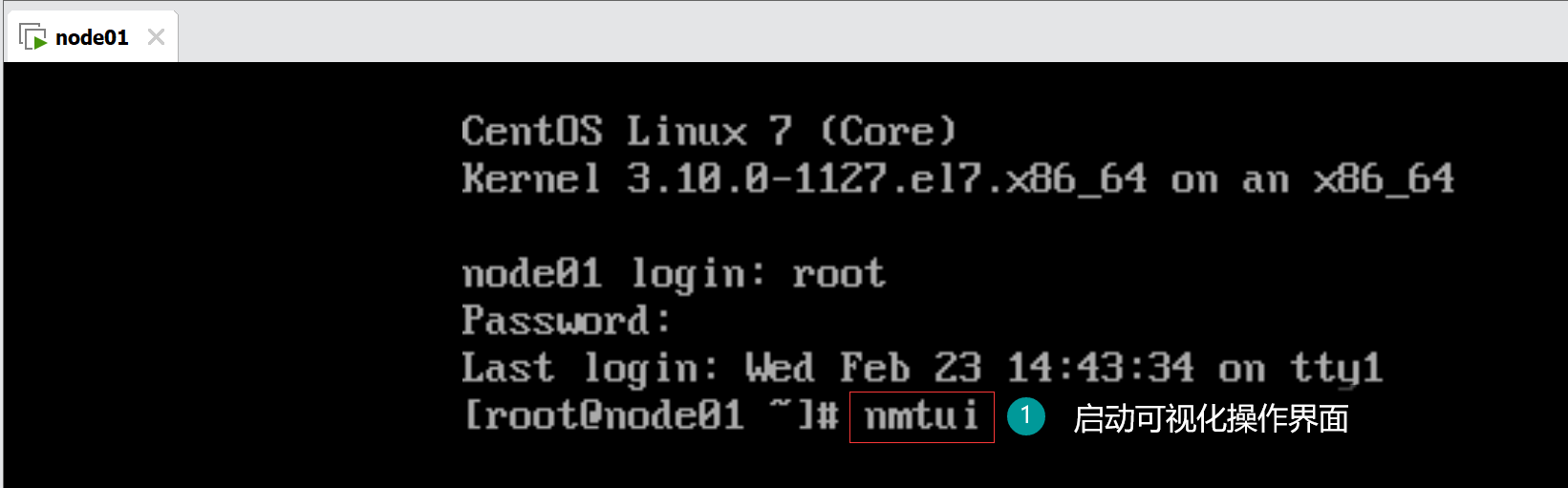
使用nmtui命令修改主机名称和网络IP地址。
使用 MobaXterm 进行连接测试配置是否 OK
在每个节点上都需要生成 SSH 免密登录的密钥对。输入命令 ssh-keygen ,然后 4 个回车即可。
可以使用 MoBaXterm的多会话功能,直接操作 3 个节点
[root@node01 ~]# ssh-keygen -t rsa
[root@node01 ~]#
Oracle官网下载Linux x64操作系统的JDK安装包 jdk-8u161-linux-x64.tar.gzMobaXterm远程连接工具连接虚拟机node01,进入Linux操作系统中存放应用安装包的目录/usr/local/src,勾选左侧的跟踪终端文件夹将JDK安装包上传到该目录下JDK,将JDK安装到存放应用的目录/usr/local,并重命名为jdkvim /etc/profile 命令编辑系统环境变量文件profilejava -version命令查看JDK版本,验证虚拟机 node01 中的JDK环境# 解压 tar 包到当前目录
[root@node01 local]# tar -zxvf jdk-8u111-linux-x64.tar.gz
#文件夹重命名
[root@node01 local]# mv jdk1.8.0_111/ jdk
# 配置 jdk 环境变量
[root@node01 local]# vim + ~/.bash_profile
export JAVA_HOME=/usr/local/jdk
export PATH=$PATH:$JAVA_HOME/bin
# 重新加载 环境变量文件,使配置生效
[root@node01 local]# source ~/.bash_profile
# 测试配置是否OK
[root@node01 local]# java –version
# JDK和环境文件分发
[root@node01 local]# scp -r jdk root@node02:/usr/local/
[root@node01 local]# scp -r jdk root@node03:/usr/local/
[root@node01 local]# scp /root/.bash_profile root@node02:/root/.bash_profile
[root@node01 local]# scp /root/.bash_profile root@node03:/root/.bash_profile
xsync.sh使用rsync远程分发工具实现本地主机和远程主机上的文件同步,检查发送方和接收方已有的文件,仅传输有变动的部分。(yum install -y rsync)
#!/bin/bash#1. 判断是否传递了路径参数
pcount=$#
if ((pcount==0)); thenecho "no args"exit 1
fi# 2. 获取文件名称
fname=`basesname $1`# 3. 获取父级目录
pdir=`cd $(dirname $fname);pwd`
read -p "开始分发,文件目录为:${pdir}/${fname},y/n:" flg
if [ $flg == 'n' ];thenecho "停止分发..."exit 0
fi# 4. 循环分发
for node in node02 node03; doecho "分发:${node}=================="rsync -av $pdir/$fname root@$node:$pdirecho "${node}分发结束================"
done
# 修改脚本执行权限
[root@node01 ~]# chmod +x xsync.sh
# 移动到 /usr/bin 目录下
[root@node01 ~]# mv xsync.sh /usr/bin
# 远程分发 jdk 到 node02 和 node03 中
[root@node01 local]# xsync.sh jdk/
MobaXterm远程连接工具连接虚拟机node01,上传Hadoop安装包hadoop-2.7.3.tar.gz到/usr/local目录下Hadoop,将Hadoop安装到存放应用的目录/usr/local,并重命名为hadoop.bash_profile,执行vim /root/.bash_profile命令编辑环境变量文件,配置Hadoop环境变量source /root/.bash_profile命令初始化系统环境变量使配置内容生效hadoop version命令查看Hadoop版本# 解压 tar 包到当前目录
[root@node01 local]# tar -zxvf hadoop-2.7.3.tar.gz
#文件夹重命名
[root@node01 local]# mv hadoop-2.7.3 hadoop
# 配置 hadoop 环境变量
[root@node01 local]# vim + ~/.bash_profile
export HADOOP_HOME=/usr/local/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
# 重新加载 环境变量文件,使配置生效
[root@node01 local]# source ~/.bash_profile
# 测试配置是否OK
[root@node01 local]# hadoop version
hadoop-env.sh、yarn-env.sh、mapred-env.sh 设置 Hadoop 环境对应的 JDK[root@node01 local]# vim /usr/local/hadoop/etc/hadoop/hadoop-env.sh
export JAVA_HOME=/usr/local/jdk[root@node01 local]# vim /usr/local/hadoop/etc/hadoop/yarn-env.sh
export JAVA_HOME=/usr/local/jdk[root@node01 local]# vim /usr/local/hadoop/etc/hadoop/mapred-env.sh
export JAVA_HOME=/usr/local/jdk
core-site.xml 配置文件[root@node01 local]# vim + /usr/local/hadoop/etc/hadoop/core-site.xml
hdfs-site.xml 配置文件[root@node01 local]# vim + /usr/local/hadoop/etc/hadoop/hdfs-site.xml
mapred-site.xml 配置文件[root@node01 local]# cp /usr/local/hadoop/etc/hadoop/mapred-site.xml.template /usr/local/hadoop/etc/hadoop/mapred-site.xml
[root@node01 local]# vim /usr/local/hadoop/etc/hadoop/mapred-site.xml
yarn-site.xml 配置文件[root@node01 local]# vim /usr/local/hadoop/etc/hadoop/yarn-site.xml
slaves 配置文件# 替换 slaves 中的节点名称
[root@node01 local]# vim /usr/local/hadoop/etc/hadoop/slaves
node01
node02
node03
Hadoop和.bash_profile配置文件分发到另外两台机器[root@node01 local]# xcall.sh hadoop/
[root@node01 ~]# xcall.sh .bash_profile
在主节点 node01 上运行 HDFS 格式化命令
[root@node01 ~]# hdfs namenode -format
20/08/23 17:13:52 INFO common.Storage: Storage directory /usr/local/hadoop-2.7.3/data/namenode has been successfully formatted.
[root@node01 hadoop]# start-all.sh
[root@node01 hadoop]# jps
3537 Jps
2931 DataNode
3284 ResourceManager
3097 SecondaryNameNode
3385 NodeManager
2827 NameNode
[root@node01 hadoop]#
这里使用的是 node01 服务名进行访问,需要在本机 C:\Windows\System32\drivers\etc\hosts 中配置地址映射。






 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有