作者:罂粟花的美童鞋 | 来源:互联网 | 2023-08-29 19:04
Hive是一个基于Hadoop的数据仓库平台。通过hive,我们可以方便地进行ETL的工作。hive定义了一个类似于SQL的查询语言:HQL,能够将用户编写的QL转化为相应的Map
Hive是一个基于Hadoop的数据仓库平台。通过hive,我们可以方便地进行ETL的工作。hive定义了一个类似于SQL的查询语言:HQL,能 够将用户编写的QL转化为相应的Mapreduce程序基于Hadoop执行。
Hive是Facebook 2008年8月刚开源的一个数据仓库框架,其系统目标与 Pig 有相似之处,但它有一些Pig目前还不支持的机制,比如:更丰富的类型系统、更类似SQL的查询语言、Table/Partition元数据的持久化等。
Hive
可以看成是从SQL到Map-Reduce的
映射器
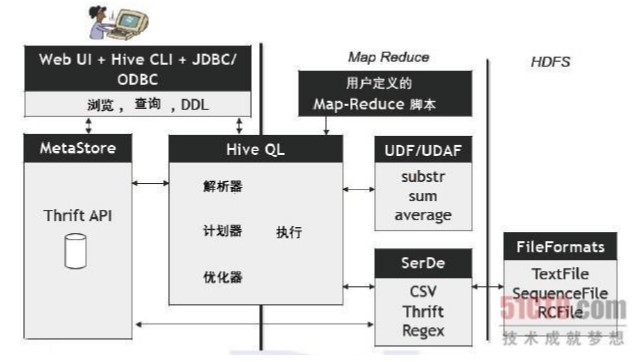
hive的组件和体系架构:
 hive web接口启动:./hive --service hwi
hive web接口启动:./hive --service hwi
浏览器访问:http://localhost:9999/hwi/
默认情况下,Hive元数据保存在内嵌的 Derby 数据库中,只能允许一个会话连接,只适合简单的测试。为了支持多用户多会话,则需要一个独立的元数据库,我们使用 MySQL 作为元数据库,Hive 内部对 MySQL 提供了很好的支持。
Hive安装
内嵌模式:元数据保持在内嵌的Derby模式,只允许一个会话连接
本地独立模式:在本地安装Mysql,把元数据放到Mysql内
远程模式:元数据放置在远程的Mysql数据库。
Hive的数据放在哪儿?
数据在HDFS的warehouse目录下,一个表对应一个子目录。
本地的/tmp目录存放日志和执行计划
hive的表分为两种,内表和外表。
Hive 创建内部表时,会将数据移动到数据仓库指向的路径;若创建外部表,仅记录数据所在的路径,不对数据的位置做任何改变。
在删除表的时候,内部表的元数据和数据会被一起删除, 而外部表只删除元数据,不删除数据。这样外部表相对来说更加安全些,数据组织也更加灵活,方便共享源数据。
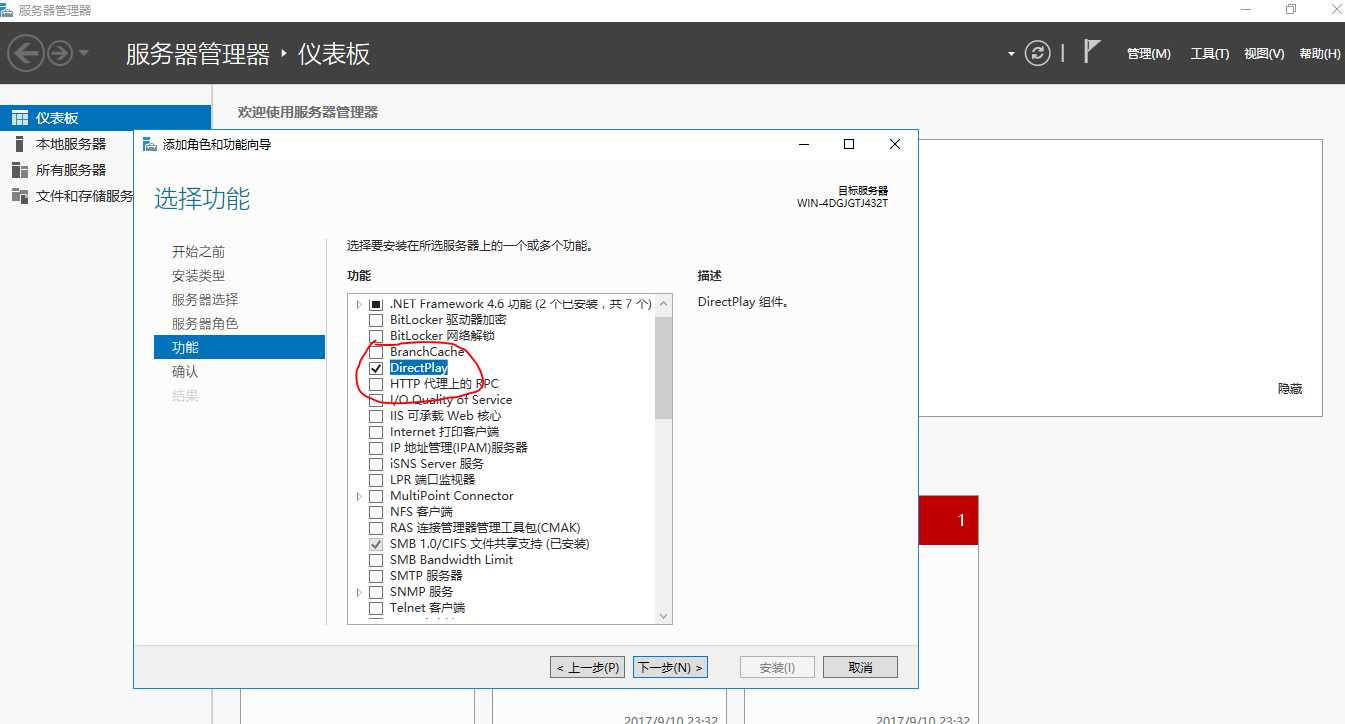
使用Mysql作为Hive metaStore的存储数据库
其中主要涉及到的表如下:
| 表名 |
说明 |
关联键 |
| TBLS |
所有hive表的基本信息(表名,创建时间,所属者等)
|
TBL_ID,SD_ID |
| TABLE_PARAM |
表级属性,(如是否外部表,表注释,最后修改时间等) |
TBL_ID |
| COLUMNS |
Hive表字段信息(字段注释,字段名,字段类型,字段序号) |
SD_ID |
| SDS |
所有hive表、表分区所对应的hdfs数据目录和数据格式 |
SD_ID,SERDE_ID |
| SERDE_PARAM |
序列化反序列化信息,如行分隔符、列分隔符、NULL的表示字符等 |
SERDE_ID |
| PARTITIONS |
Hive表分区信息(所属表,分区值) |
PART_ID,SD_ID,TBL_ID |
| PARTITION_KEYS |
Hive分区表分区键(即分区字段) |
TBL_ID |
| PARTITION_KEY_VALS |
Hive表分区名(键值) |
PART_ID |
HIVE与mysql的关系


![Spark中使用map或flatMap将DataSet[A]转换为DataSet[B]时Schema变为Binary的问题及解决方案](https://img6.php1.cn/3cdc5/9b0d/243/f27d40b3b7e4b51b.png)


 京公网安备 11010802041100号
京公网安备 11010802041100号