目录:
Namenode RPC性能优化实践
Namenode状态切换延迟问题
HDFS安全机制之白名单实现
HDFS文件保护机制
Namenode GC方面的优化实践
HDFS集群存储过高导致客户端写入异常;
HDFS Balancer优化方案;
Datanode磁盘IO高问题;
Datanode磁盘不均衡问题;
前言:
此篇文章是本人在负责维护公司hadoop2.7.2集群过程中总结的一部分实践优化经验以及遇到的一些问题的解决方法,如有异议的地方欢迎一起讨论。我们知道,随着HDFS集群规模增长会带来很多急需的问题来保证集群稳定运行,主要问题有:
元数据持续增长,内存过大
并发请求持续增长,集群性能问题
业务繁杂,数据安全性问题
单集群规模过大,集群规模问题
下面来讲一下针对这些问题进行的相关优化实践。
一. HDFS Federation架构
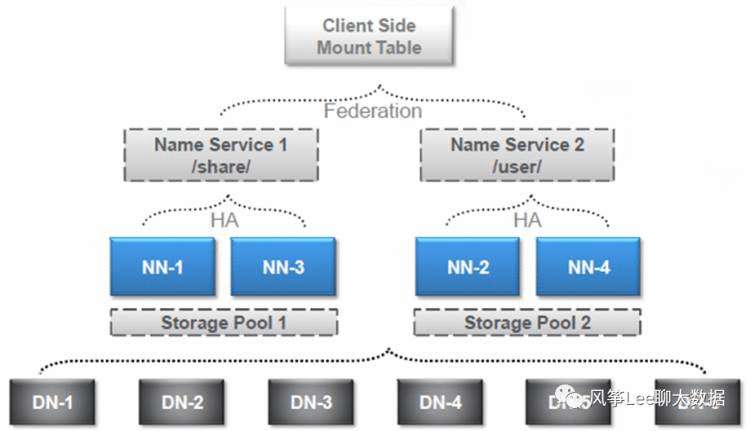
前期调研hdfs federation架构,hadoop2.7.2版本的federation架构是基于配置客户端viewfs实现,也就是viewfs在客户端做地址解析转发,每次调整需要在客户端上进行,维护复杂,这样给集群升级(客户端)带来很大麻烦。Hadoop社区在HDFS-10467中实现了基于路由的federation功能(RBF),此功能比原有方式有了很大的改进,真正做到了基于后端的路由映射,由服务端进行统一配置管理,考虑迁移并应用RBF功能;
二. namenode rpc性能优化实践
背景:由于扩容了大量的datanode节点,导致相应的IBR数量线性增大,对namenode节点产生了大量的rpc请求,由于来自多个IPC处理程序线程的过多写锁争用,大量DN节点的IBR请求将降低NN性能,影响客户端请求。
优化方案(hadoop社区):
A. Namenode端新增线程异步去处理所有IBR请求,通过将多个IBR合并到一个写锁事务中(IBR请求处理速度很快),可以减少锁争用。因此对于其他操作,处理程序也可以更快地释放出来。
HDFS-9198 异步聚合处理IBR降排队负载,减少抢锁次数
https://issues.apache.org/jira/browse/HDFS-9198
https://issues.apache.org/jira/secure/attachment/12785139/HDFS-9198-branch-2.7.patch
具体实现:
增量块报告被后台线程转储到一个队列中进行异步处理。这个线程获取写锁并处理IBR请求,直到队列耗尽或满足最大锁持有时间。最大持有时间是4ms,这可能看起来有点高,但如果NN有那么多的积压,最好是抓住这个机会,以避免客户端问题。
B. 调整datanode端IBR汇报机制,改为批量ibr, 由于现有机制,一旦有block修改操作就会产生一次ibr,namenode 端处理ibr rpc请求会随着datanode的数量线性增长,增加写锁的抢占,同时影响到客户端的读写请求;(具体实现:增加批量ipr机制,通过配置时间间隔来批量发送ibr请求)
https://issues.apache.org/jira/browse/HDFS-9917
https://issues.apache.org/jira/secure/attachment/12796709/HDFS-9917-branch-2.7-002.patch
https://issues.apache.org/jira/browse/HDFS-9726
https://issues.apache.org/jira/secure/attachment/12868855/HDFS-9726-branch-2.7.01.patch
https://issues.apache.org/jira/browse/HDFS-9710
https://issues.apache.org/jira/secure/attachment/12869711/HDFS-9710-branch-2.7.01.patch
其他优化点(包括考虑中的):
Balancer不需要保证数据⼀致性,getDatanodeStorageReport+getBlocks请求到stadnby namenode 节点
https://issues.apache.org/jira/browse/HDFS-1318
一般情况下集群的读操作比写操作读很多,使用非公平读写锁会提高吞吐量,需要调整配置:dfs.namenode.fslock.fair 为false,重启namenode;
https://issues.apache.org/jira/browse/HADOOP-10300
https://issues.apache.org/jira/browse/HDFS-7964
https://issues.apache.org/jira/browse/HDFS-12603
为FSNamesystemLock添加监控来查看每个操作持有锁的时间,以便于通过监控指标分析和进行namenode锁优化
https://issues.apache.org/jira/browse/HDFS-10872
通过jstack和火焰图排查发现大量的写log操作占用一些性能且大量刷盘操作占用磁盘io,可以去掉大量无用log或者降低log level;
三. namenode 状态切换延迟问题
问题现象:namenode切换为active状态时出现延迟和超时现象;

Step1: 通过当时打印的namenode 进程的火焰图和jstack log分析
查看当时备份的m3节点的namenode进程火焰图:

可见namenode端处理transitionToActive请求的调用过程和主要耗时情况,几乎全部耗时都花费在了FsImage.updateCountForQuotaRecursively方法上;
查看当时打印的jstack log也发现当时线程一直是runnable状态:

梳理具体的代码逻辑: namenode端处理zkfc transitionToActive切换状态请求,需要保证所有的editlog已加载完成,并调用递归方法updateCountForQuotaRecursively更新整个fsimage下的配额和使用量信息,因为现在逻辑是单线程递归更新,在fsimage 比较大情况下处理会比较慢。
问题原因:
namenode切换为active状态时更新整个fsimage配额和使用量方法耗时过高,导致整个rpc切换方法执行时间过长。
问题解决:
参考hadoop jira,hadoop2.8.0版本上更新配额和使用量逻辑已更改为fork-join并发处理模式,相关patch上的测试对比结果:

相关patch: https://issues.apache.org/jira/browse/HDFS-8865
四. HDFS安全机制之访问白名单机制
背景
HDFS现有的用户认证机制基于kerberos实现,但是存在一些问题,比如kerberos服务存在KDS服务单点问题、配置维护复杂、且依赖hdfs的服务响应也要配置kerberos增加运维复杂度。HADOOP本身存在IP白名单机制,但是没有实现基于用户的,且会限制hdfs服务本身的一些进程服务访问。
访问白名单机制
基于安全性、简易性我们单独设计了基于IP用户的白名单访问机制;整体设计如下图:

白名单列表在大数据管理平台进行维护,由平台管理人员批量导入和实时更新。为了避免白名单验证逻辑直接访问mysql数据库,后台周期性任务load数据到hdfs集群的具体文件里,namenode守护线程异步load白名单列表到namenode进程内存中,整个流程中为了安全设计了很多容错处理;
动态检测开关配置,切换开关不用重启进程,设计两个配置项如下:
hdfs-site.xml
<property>
<name>dfs.whitelist.enabledname>
<value>falsevalue>
property>
<property>
<name>dfs.whitelist.pathname>
<value>/home/bigmananger/hdfs/namenode/whitelist.propertiesvalue>
property>
五. HDFS文件安全策略
我们知道HDFS本身有很多数据安全机制,例如hdfs trash功能、snapshot。但是这些机制并不能完全保证一些高危操作的安全性,一旦业务有误删操作就会导致一系列的任务失败,对业务产生很大影响,所以我们设计了一些hdfs文件安全策略机制。
我们设计了hdfs数据目录的保护机制,可以对一些重点目录进行保护,比如一些业务的数据根目录、任务运行依赖的目录(flink checkpoint目录等)。
功能设计比较简单,配置指定的hdfs文件来维护所有需要保护的重点目录,后台守护线程进行异步刷新,namenode端执行delete、mv操作时会进行效验,效验失败则抛出异常。

由于skiptrash选项是在hadoop客户端代码中,所以调整代码后必须替换所有客户端。
某日数据平台管理端开发人员误操作清空业务数据根目录,由于后台调用原有的hdfs delete方法清理数据目录,而delete api是直接删除hdfs文件,没有调用hdfs trash机制,导致目录下数据无法恢复。所以设计了deleteByTrash方法语义,服务端执行deleteByTrash逻辑时会调用hdfs trash,如果发现有误删除操作,可以保证在trash周期内进行数据恢复。
六. Namenode GC方面的优化实践
随着集群规模增大,Namenode进程配置的内存也逐渐增大,已达200G+,如果提高namenode进程gc效率保证集群的吞吐量和稳定性是每个大集群维护人员面临的调整。
我们的集群Namenode GC方面的优化实践分为三个周期:
早期应用CMS GC运行一段时间,期间不断调优gc配置,但是也发现了一些问题,比如偶尔会触发System.gc()导致full gc(具体原因当时没有完全确定),然后通过XX:+DisableExplicitGC参数直接禁用这类GC。(其实也可以通过-XX:+ExplicitGCInvokesConcurrent参数减缓这类GC)

在测试集群应用G1和CMS两种方式进行对比,发现很多方面G1的性能和稳定性(GC时间可控性)都要好一些,所以线上集群调整为G1方式,运行期间不断进行调优配置后比较稳定。但是随着常驻内存越来越大,出现长时间GC的情况,排查GC log确定是Scan RSet时间过高,长时间的GC几乎所有的时间消耗都在Scan Rset上,添加-XX:G1SummarizeRSetStatsPeriod参数打印log发现Did coarsenings中X的值很高,说明RSet粗化程度比较高。参考java官网G1相关文档(https://docs.oracle.com/javase/9/gctuning/garbage-first-garbage-collector-tuning.htm#JSGCT-GUID-E26056D1-02A5-4367-94EF-72C66D314AF7),提高-XX:G1RSetRegionEntries 值来降低粗化的程度,查看G1源码确认G1RSetRegionEntries缺省的情况下通过默认公式计算为1536,线上环境经过不断调高G1RSetRegionEntries解决了Scan Rset时间过长问题,但是引入了一个新问题,导致进程堆外内存过高,比默认多占用了至少50G+内存,不过暂时通过增加服务器物理内存解决。
由于CMS、G1方式的一些问题,所以考虑调研实践JDK一些新思想实现的GC方式。首先我们调研实践了Shenandoah GC,在hdfs、hbase组件都测试了Shenandoah,发现性能和G1对比有很大的提高, 但是在线上HDFS集群上应用时发现经常有RPC延迟情况、吞吐量下降的问题,排查发现新创建对象时(相比G1)都会有一些延迟,测试环境验证了这个问题,所以暂停使用Shenandoah GC这种方式。
六.HDFS集群存储过高导致客户端写入异常
某日,线上hdfs集群客户端写操作大量报错

问题分析:
step1:通过namenode log进行分析:
通过hdfs客户端配置和后台代码分析可知,namenode端使用的是默认的副本放置策略(BlockPlacementPolicyDefault),利用hadoop支持动态配置log4j级别的特性,动态设置BlockPlacementPolicyDefault类的log级别为debug(注意debug log量特别大,会影响服务性能,生产环境谨慎使用或者短暂调整下使用):


可见,namenode分配datanode节点时,出现了大量的错误,主要有两种:
1. datanodeIP:50010 is not chosen since the node does not have enough DISK space;
2. datanodeIP:50010 is not chosen since the node is too busy;
通过hdfs命令和web页面查看datanode节点存储使用率情况,发现大量节点使用率已超过98%;
step2:分析副本放置策略逻辑代码
看下具体校验节点是否可用逻辑(isGoodTarget):
1. 存储目录不能是read-only
2. 存储目录必须是健康的
3. 存储目录所在节点不能是正在下线中的节点
4. 此节点必须存在空间大于放置副本的存储目录
5. 节点的IO线程数不能超过集群内平均IO线程数量的2倍
6. 该节点需要同时满足机架内最大副本数限制
结合打印的log ,可知namenode已经选择了所有数据节点,未发现可用节点, 结合具体的报错信息分析可知:
1. datanodeIP:50010 is not chosen since the node does not have enough DISK space : 当时大量的节点存储已无可用空间,为不可选节点,所有这些节点上负载几乎为0;
2. datanodeIP:50010 is not chosen since the node is too busy : 验证逻辑的第五条,如果dn节点的active xceiver 数量超过了集群平均值的两倍就认为是不可选节点, 当时acitve xceiver线程数为76,远远没有达到配置值1024,且这些节点磁盘和网络io未发现过高问题,所以认为是逻辑问题导致的误报不可用节点;
问题原因:
整个集群存储使用率过高,大量节点已无可用空间,且这些节点拉低了整个集群的平均负载值,影响到了namenode 判断可用节点逻辑中的第五条(判断负载),导致不可用节点的误报,最终选不出可用的dn节点;
问题解决:
新增代码逻辑,增加动态配置:判断过高负载逻辑中的集群平均负载的倍数,根据集群情况手动配置;
七. Hdfs Balancer优化
集群维护过程中发现hdfs balancer存在很多问题,比如效率很低,对active namenode产生高负载请求(getBlocks)、move线程被慢节点卡住问题等等;整理社区上一些功能优化和bug修复相关的patch:
功能优化:
Increase default balance bandwidth and concurrent moves:
https://issues.apache.org/jira/browse/HDFS-10297
Allow Balancer to run faster:
https://issues.apache.org/jira/browse/HDFS-8818
修复逻辑bug:
Enhance Dispatcher logic on deciding when to give up a source DataNode
https://issues.apache.org/jira/browse/HDFS-10966
说明:在HDFS-10966之前,原有逻辑存在严重的 bug,由于datanode用于balancer copy并发的限制,会导致每批次只balancer了少量的数据, HDFS-10966加入了时间判断逻辑,能够保证把本批计划的数据copy完成。
我们知道可以通过hadoop命令动态调整集群用于balancer的宽带限制,但是原有逻辑存在bug(动态调大整个集群的balancer宽带限制后,重启或者新扩容datanode节点会加载配置文件里默认的配置,导致每批执行任务都会卡在这些节点上),所以我们设计了保存具体的宽带信息放到namenode内存中,重启和新扩容的DN节点可以通过心跳从namenode获取,设计流程如下图。

八. Datanode磁盘IO高问题
为了计算DN的capacity使用量,DN会针对其配置的每块盘路径进行du操作,然后将数据汇报到NN中,为了保证数据使用量统计的近实时性,默认du间隔为10min,所以对于DN来说,默认的Du会产生大量的du-sk的操作,会造成集群严重的IO Wait增加,从而导致读写会变得缓慢。

社区优化方案:
a. 使用 df 命令替换 du(可配置,使用df前提条件磁盘目录下存储只有hdfs单块池占用)。增加检查间隔时间随机抖动机制;(将一个节点上同时产生的多个du操作,加个随机数,随机到集群的不同时间段)
https://issues.apache.org/jira/browse/HADOOP-9884
https://issues.apache.org/jira/browse/HADOOP-12973
https://issues.apache.org/jira/browse/HADOOP-12974
https://issues.apache.org/jira/browse/HADOOP-12975
b. DataNode Layout升级
默认DN数据目录层级为256x256,DU操作为递归机制在层级和数目多的情况性能很差,造成IO阻塞。所以社区对DN数据目录层级进行了优化,DN目录层级从256x256变为32x32,是需要DN Layout升级改动的, 具体升级过程可参考具体patch。
https://issues.apache.org/jira/browse/HDFS-8791
说明:应用df 替换du会有一定的数据差异;
执行机制不同:Linux df和du执行原理机制的不同,du的数据是基于文件获取的,并非针对某个分区,执行时间受限于文件和目录个数;df直接使用 statfs系统调用,直接读取分区的超级块信息获取分区使用情况,针对整个分区,直接读取超级块,运行速度不受文件目录个数影响,执行很快。
du和df不一致情况:常见的df和du不一致情况就是文件删除的问题。当一个文件被删除后,在文件系统目录中已经不可见了,所以du就不会再统计它了。然而如果此时还有运行的进程持有这个已经被删除了的文件的句柄,那么这个文件就不会真正在磁盘中被删除,分区超级块中的信息也就不会更改。这样df仍旧会统计这个被删除了的文件。
九. Datanode磁盘不均衡问题
背景:
运维hadoop集群过程中,发现datanode节点经常会出现磁盘不均衡的现象,产生的原因主要有数据盘损坏后进行换新盘操作、删除大量数据的操作等。hadoop2.7.2版本中没有单个datanode节点内的磁盘数据balance功能(目前hadoop3版本中已经实现了diskbalancer功能,可以考虑进行功能移植)。
解决方式:
我们的做法是调整datanode数据副本存放磁盘的选择策略为可用空间选择策略(AvailableSpaceVolumeChoosingPolicy),让datanode写数据时尽量选择可用空间比较大的磁盘,尽量缓解磁盘不均衡的问题;












 京公网安备 11010802041100号
京公网安备 11010802041100号