本文从HBase的内存布局说起,先充分了解HBase的内存区的使用与分配,随后给出了不同业务场景下的读写内存分配规划,并指导如何分析业务的内存使用情况,以及在使用当中写内存Memstore及读内存扩展bucketcache的一些注意事项,最后为了保障群集的稳定性减少和降低GC对于集群稳定性的影响,研究及分享了一些关于HBase JVM配置的一些关键参数机器作用和范例,希望这些不断充实的经验能确保HBase集群的稳定性能更上一个台阶,大家有任何的想法和建议也欢迎一起讨论。
一台region server的内存使用(如下图所示)主要分成两部分:
1.JVM内存即我们通常俗称的堆内内存,这块内存区域的大小分配在HBase的环境脚本中设置,在堆内内存中主要有三块内存区域,
2.java direct memory即堆外内存,

在详细说明具体的容量规划前,首先要明确on heap模式下的内存分布图,如下图所示:

如图,整个RegionServer内存就是JVM所管理的内存,BlockCache用于读缓存;MemStore用于写流程,缓存用户写入KeyValue数据;还有部分用于RegionServer正常RPC请求运行所必须的内存;
| 步骤 | 原理 | 计算 | 值 |
|---|---|---|---|
| jvm_heap | 系统总内存的 2/3 | 128G/3*2 | 80G |
| blockcache | 读缓存 | 80G*30% | 24G |
| memstore | 写缓存 | 80G*45% | 36G |
hbase-site.xmll
与 on heap模式相比,读多写少型需要更多的读缓存,在对读请求响应时间没有太严苛的情况下,会开启off heap即启用堆外内存的中的bucket cache作为读缓存的补充,如下图所示
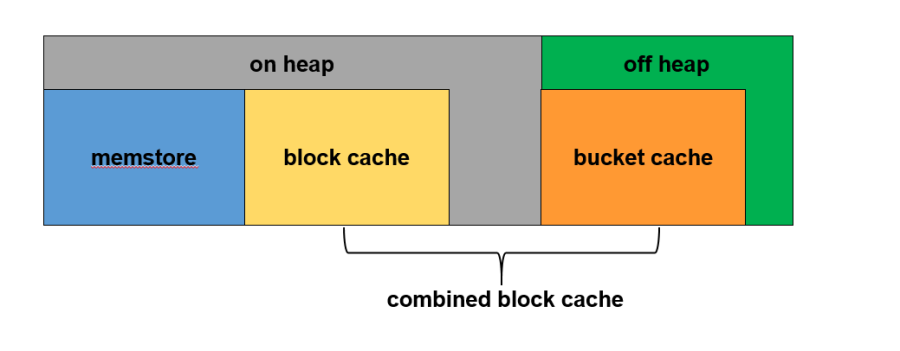
整个RegionServer内存分为两部分:JVM内存和堆外内存。其中JVM内存中BlockCache和堆外内存BucketCache一起构成了读缓存CombinedBlockCache,用于缓存读到的Block数据,其中BlockCache用于缓存Index Block和Bloom Block,BucketCache用于缓存实际用户数据Data Block
| 步骤 | 原理 | 计算 | 值 |
|---|---|---|---|
| RS总内存 | 系统总内存的 2/3 | 128G/3*2 | 80G |
| combinedBlockCache | 读缓存设置为整个RS内存的70% | 80G*70% | 56G |
| blockcache | 主要缓存数据块元数据,数据量相对较小。设置为整个读缓存的10% | 56G*10% | 6G |
| bucketcache | 主要缓存用户数据块,数据量相对较大。设置为整个读缓存的90% | 56G*90% | 50G |
| memstore | 写缓存设置为jvm_heap的60% | 30G*60% | 18G |
| jvm_heap | rs总内存-堆外内存 | 80G-50G | 30G |
参数详解
| Property | Default | Description |
|---|---|---|
| hbase.bucketcache.combinedcache.enabled | true | When BucketCache is enabled, use it as a L2 cache for LruBlockCache. If set to true, indexes and Bloom filters are kept in the LruBlockCache and the data blocks are kept in the BucketCache. |
| hbase.bucketcache.ioengine | none | Where to store the contents of the BucketCache. Its value can be offheap、heap、file |
| hfile.block.cache.size | 0.4 | A float between 0.0 and 1.0. This factor multiplied by the Java heap size is the size of the L1 cache. In other words, the percentage of the Java heap to use for the L1 cache. |
| hbase.bucketcache.size | not set | When using BucketCache, this is a float that represents one of two different values, depending on whether it is a floating-point decimal less than 1.0 or an integer greater than 1.0. |
| -XX:MaxDirectMemorySize | MaxDirectMemorySize = BucketCache + 1 | A JVM option to configure the maximum amount of direct memory available for the JVM. It is automatically calculated and configured based on the following formula: MaxDirectMemorySize = BucketCache size + 1 GB for other features using direct memory, such as DFSClient. For example, if the BucketCache size is 8 GB, it will be -XX:MaxDirectMemorySize=9G. |
hbase-site.xml
hbase-env.sh
export HBASE_REGIONSERVER_OPTS="-XX:+UseG1GC
-Xms30g –Xmx30g -XX:MaxDirectMemorySize=50g
知己知彼方能百战不殆,在HBase群集的运行过程中,我们需要了解HBase实际情况下的读写内存使用,才能最大化的对配置做出最加的调整,接下来说下如何查询HBase运行中读写内存使用情况
Jmx查询
http://xxxxxxxx.hadoop.db.com:11111/jmx?qry=Hadoop:service=HBase,name=RegionServer,sub=Server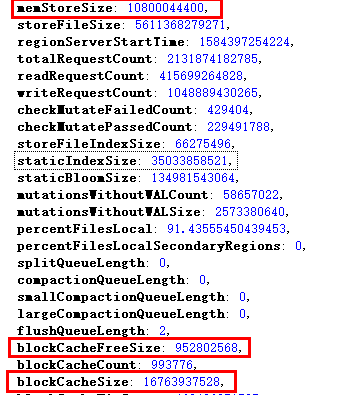
memStoreSize代表RegionServer中所有HRegion中的memstore大小的总和,单位是Byte。该值的变化,可以反应出一个RegionServer上写请求的负载状况,可以观察memstoreSize的变化率,如果在单位时间内变化比较抖动,可以近似认为写操作频繁。
blockCacheFree代表block cache中空闲的内存大小。计算方法为:getMaxSize() – getCurrentSize(),单位是Byte,该值反映出当前BlockCache中还有多少空间可以被利用。
blockCacheSize代表当前使用的blockCache的大小。BlockCache. getCurrentSize(),单位是Byte,该值反映出BlockCache的使用状况。
以单台region server配置为例
| 配置项 | 配置值 | 内存分配值 | 实际使用量 |
|---|---|---|---|
| HBASE_REGIONSERVER_OPTS | -Xms75g –Xmx75g | 75g | 75g |
| hbase.regionserver.global.memstore.size | 0.22 | 80g*0.22 = 17.6g | 10800044400/1024/1024/1024 ≈ 10G |
| hfile.block.cache.size | 0.22 | 80g*0.22 = 17.6g | 16763937528 /1024/1024/1024 ≈ 15.6G 952802568 /1024/1024/1024 ≈ 0.9G |
结合单台regionserver 的配置来看,读写缓存都有一定空闲空间,这种情况下可以降低heap size来减少gc的次数和时长,然后我们还需要以群集所有region server的数据来判断该集群的配置是否合理,如果存在读写不均衡和热点情况都会影响不同region间的缓存大小。
一张数据表由一个或者多个region 组成,在单个region中每个columnfamily组成一个store,在每个store中由一个memstore和多个storefile组成,如下图所示
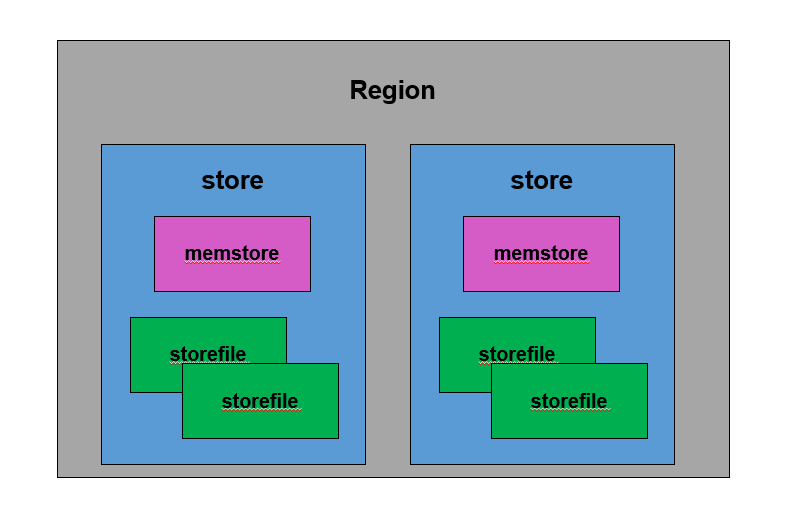
HBase是基于LSM-Tree数据结构的,为了提升写入性能,所有数据写入操作都会先写入memstore中(同时会顺序写入WAL),达到指定大小后会对memstore中的数据做次排序后在批量flush磁盘中,此外新写入的数据有较大概率被读取到,因此HBase在读取数据时首先检查memstore中是否有数据缓存,未命中的情况下再去找读缓存,可见memstore无论对于HBase的写入和读取性能都至关重要,而其中memstore flush操作又是memstore最核心的操作。
| 操作级别 | 触发条件 | 影响度 |
|---|---|---|
| memstore级别 | 当region中任意一个memstore的大小达到了上限 即>hbase.hregion.memstore.flush.size = 256mb | 小,短暂阻塞写 |
| region级别 | 当region中所有的memstore的大小达到了上限 即>hbase.hregion.memstore.block.multiplier * hbase.hregion.memstore.flush.size = 8 * 256mb | 小,短暂阻塞写 |
| regionserver级别 | 当一个regionserver中所有memstore的大小达到了上限 即> hbase.regionserver.global.memstore.size * heap_size = 0.22*75g | 大,阻塞regionserver上的所有写请求且时间较长 |
| regionserver中WAL Log数量达到上限 | > hbase.regionserver.maxlogs = 256 系统会选取最早的一个 WAL Log对应的一个或多个region进行flush | 小,短暂阻塞写 |
| 定期刷新 | > hbase.regionserver.optiOnalcacheflushinterval= 3600000 | 小,短暂阻塞写 |
| 手动刷新 | 用户可以通过shell命令flush table 或者flush region name分别对一个表或者一个region进行flush | 小,短暂阻塞写 |
从memstore flush的动作来看,对业务影响最大是regionserver级别的flush操作,假设每个memstore大小为256mb,每个region有两个cf,整个regionserver上有100个region,根据计算可知,总消耗内存 = 256mb2100 = 51.2g >> 0.40*80g = 32g ,很显然这样的设置情况下,很容易触发region server级别的flush操作,对用户影响较大。
根据如上分析,memstore的设置大小不仅取决于读写的比例,也要根据业务的region数量合理分配memstore大小,同样的我们对每台regionserver上region的数量及每张表cf的数量上的控制也能达到理想的效果。
heap模式分配内存会调用byteBuffer.allocate方法,从JVM提供的heap区分配。
内存分配时heap模式需要首先从操作系统分配内存再拷贝到JVM heap,相比offheap直接从操作系统分配内存更耗时,但反之读取缓存时heap模式可以从JVM heap中直接读取比较快。
offheap模式会调用byteBuffer.allocateDirect方法,直接从操作系统分配,因为内存属于操作系统,所以基本不会产生CMS GC,也就在任何情况下都不会因为内存碎片导致触发Full GC。
内存分配时offheap直接从操作系统分配内存比较快,但反之读取时offheap模式需要首先从操作系统拷贝到JVM heap再读取,比较费时。
file使用Fussion-IO或者SSD等作为存储介质,相比昂贵的内存,这样可以提供更大的存储容量。
使用堆外内存,可以将大部分BlockCache读缓存迁入BucketCache,减少jvm heap的size,可以减少GC发生的频次及每次GC时的耗时
BucketCache没有使用JVM 内存管理算法来管理缓存,而是自己对内存进行管理,因此其本身不会因为出现大量碎片导致Full GC的情况发生。
读取data block时,需要将off heap的内存块拷贝到jvm heap在读取,比较费时,对读性能敏感用户不太合适。
对于读多写少且对读性能要求不高的业务场景,offheap模式能够有效的减少gc带来的影响,线上的vac集群在开启offheap模式后,GC频次和耗时都能有效降低,但是因为bucketcache 读的性能的问题达不到要求而回退到heap模式。
Hbase服务是基于JVM的,其中对服务可用性最大的挑战是jvm执行full gc操作,此时会导致jvm暂停服务,这个时候,hbase上面所有的读写操作将会被客户端归入队列中排队,一直等到jvm完成gc操作, 服务在遇到full gc操作时会有如下影响
如何避免和预防GC超时的不良影响,我们需要对JVM的参数进行优化
hbase-env.sh
| 配置项 | 重要参数详解 |
|---|---|
| export HBASE_HEAPSIZE=4096 | HBase 所有实例包括Master和RegionServer占用内存的大小,不过一般用Master和RegionServer专有参数来分别设定他们的内存大小,推荐值给到4096 |
| export HBASE_MASTER_OPTS=" -Xms8g -Xmx8g -Xmn1g -XX:+UseParNewGC -XX:+UseConcMarkSweepGC -XX:CMSInitiatingOccupancyFraction=70" | Master专有的启动参数,Xms、Xmx、Xmn分别对应初始堆、最大堆及新生代大小 Master小堆,新生代用并行回收器、老年代用并发回收器,另外配置了CMSInitiatingOccupancyFraction,当老年代内存使用率超过70%就开始执行CMS GC,减少GC时间,Master任务比较轻,一般设置4g、8g左右,具体按照群集大小评估 |
| export HBASE_REGIONSERVER_OPTS="-XX:+UseG1GC -Xms75g –Xmx75g -XX:InitiatingHeapOccupancyPercent=83 -XX:G1HeapRegiOnSize=32M -XX:ParallelGCThreads=28 -XX:COncGCThreads=20 -XX:+UnlockExperimentalVMOptions -XX:G1NewSizePercent=8 -XX:G1HeapWastePercent=10 -XX:MaxGCPauseMillis=80 -XX:G1MixedGCCountTarget=16 -XX:MaxTenuringThreshold=1 -XX:G1OldCSetRegiOnThresholdPercent=8 -XX:+ParallelRefProcEnabled -XX:-ResizePLAB -XX:+PerfDisableSharedMem -XX:-OmitStackTraceInFastThrow -XX:+PrintFlagsFinal -verbose:gc -XX:+PrintGC -XX:+PrintGCTimeStamps -XX:+PrintGCDateStamps -XX:+PrintAdaptiveSizePolicy -XX:+PrintGCDetails -XX:+PrintGCApplicationStoppedTime -XX:+PrintTenuringDistribution -XX:+PrintReferenceGC -XX:+UseGCLogFileRotation -XX:NumberOfGCLogFiles=5 -XX:GCLogFileSize=100M Xloggc:${HBASE_LOG_DIR}/gc-regionserver$(hostname)-`date +'%Y%m%d%H%M'`.log -Dcom.sun.management.jmxremote.port=10102 $HBASE_JMX_BASE" | RegionServer专有的启动参数,RegionServer大堆,采用G1回收器,G1会把堆内存划分为多个Region,对各个Region进行单独的GC,最大限度避免Full GC及其影响 初始堆及最大堆设置为最大物理内存的2/3,128G/3*2 ≈80G,在某些度写缓存比较小的集群,可以近一步缩小。 InitiatingHeapOccupancyPercent代表了堆占用了多少比例的时候触发MixGC,默认占用率是整个 Java 堆的45%,改参数的设定取决于IHOP > MemstoreSize%+WriteCache%+10~20%,避免过早的MixedGC中,有大量数据进来导致Full GC G1HeapRegionSize 堆中每个region的大小,取值范围【1M..32M】2^n,目标是根据最小的 Java 堆大小划分出约 2048 个区域,即heap size / G1HeapRegiOnSize= 2048 regions ParallelGCThreads设置垃圾收集器并行阶段的线程数量,STW阶段工作的GC线程数,8+(logical processors-8)(5/8) ConcGCThreads并发垃圾收集器使用的线程数量,非STW期间的GC线程数,可以尝试调大些,能更快的完成GC,避免进入STW阶段,但是这也使应用所占的线程数减少,会对吞吐量有一定影响 G1NewSizePercent新生代占堆的最小比例,增加新生代大小会增加GC次数,但是会减少GC的时间,建议设置5/8对应负载normal/heavy集群 G1HeapWastePercent触发Mixed GC的堆垃圾占比,默认值5 MaxGCPauseMillis 垃圾回收的最长暂停时间,默认200ms,如果GC时间超长,那么会逐渐减少GC时回收的区域,以此来靠近此阈值,一般来说,按照群集的重要性 50/80/200来设置 verbose:gc在日志中输出GC情况 |







 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有