本文所搭建的 HBase 版本为 HBase 0.98.6-cdh5.3.2。HBase 有两种运行模式:单机模式 和 分布式模式。本文只重点讲解 “分布式模式“。
在搭建 HBase 0.98.6-cdh5.3.2 之前,笔者已经在集群搭建并启动好 Hadoop 和 ZooKeeper 集群。具体请参考:
在开始安装 HBase 之前需要做一些准备工作,这涉及到系统设置、分布式模式 Hadoop 的部署及 HBase 自身的配置,因此要确保在运行 Hbase 之前这些条件已经具备。以下将介绍 HBase 依赖的一些重要的中间件、系统服务或配置。
| IP | 主机名 | 用户名 | HBase 地位 | 启动后进程 |
|---|---|---|---|---|
| 10.6.3.43 | master5 | hadoop5 | 主 Master | HMaster |
| 10.6.3.33 | master52 | hadoop5 | 备份 Master | HMaster |
| 10.6.3.48 | slave51 | hadoop5 | RegionServer | HRegionServer |
| 10.6.3.32 | slave52 | hadoop5 | RegionServer | HRegionServer |
| 10.6.3.38 | slave53 | hadoop5 | RegionServer | HRegionServer |
1. 安装 jdk 1.8.0
安装 jdk 1.8.0 至 /usr/local/jdk1.8.0_60 ,具体请参考 “安装 jdk1.8.0”
2. 配置免密 ssh 登陆
具体请参考:Centos6.5下SSH免密码登陆配置
3. 域名系统 DNS
Hbase 通过本地主机名 (Host Name)或 域名 (Domain Name)来获取 IP 地址,因此要确保正向和反向 DNS 解析是正常的。在进行 DNS 解析时会首先本地 /etc/hosts 文件,因此建议通过配置该文件指定主机名或域名到 IP 地址的映射关系而不使用域名解析服务,这样做将更易于维护,当出现主机无法识别的异常时也更加容易定位问题出现的位置,并且通过本地 /etc/hosts 文件解析 IP 地址速度也会更快一些。
编辑 /etc/hosts 文件内容均一致,都要将集群中的各 IP 和 主机名对应起来
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
10.6.3.43 master5
10.6.3.33 master52
10.6.3.48 slave51
10.6.3.32 slave52
10.6.3.36 slave53
当决定使用 DNS 服务的时候,还可以通过如下设置更加精确地控制 HBase 的行为。
如果有多个网卡,可以通过参数 hbase.regionserver.dns.interface 指定网卡,该配置参数的默认值是 default ,可以通过这个参数指定网络接口,不过要求集群所有节点配置是相同的且每台主机都使用相同的网卡配置,可以修改这个配置参数为 eth0 或 eth1 ,这要视具体的硬件配置而定。
另一个配置是指定 hbase.regionserver.dns,nameserver 可以选择一个不同的 DNS 的 nameserver。
4. 本地回环地址 Loopback IP
HBase 要求将本地回环接口配置成 127.0.0.1,可以在 /etc/hosts 文件配置,通常系统安装后都已经包含了该配置
127.0.0.1 localhost
HBase 要求集群中节点间的系统时间要基本一致,可以容忍一些偏差,默认相差 30s 以内。可以通过设置参数 hbase.master.maxclockskew 属性值修改最大容忍偏差时间。偏差时间较多时集群会产生一些奇怪的行为。用户需要在集群中数据发生了一些莫名其妙的问题,例如读到的不是刚写进集群的数据而是旧数据,这时就要检查集群各节点间时间是否同步。
笔者采用的是在 10.6.3.43 上搭建 NTP 时间服务器,集群中其他节点都随时与 10.6.3.43 保持时间同步。关于 NTP 服务器的搭建,可以参考:NTP 时间服务器实战
如果不愿意搭建 NTP 服务器,可以用脚本实现在每台主机上同时键入时间
date -s "2014-1-4 12:16:00"
同时设置下 hbase.master.maxclockskew 参数,这个具体请看 附录
ZooKeeper 是 HBase 集群的 “协调器” ,负责解决 HMaster 的单点问题,以及 root 的路由,所以一个独立的 ZooKeeper 服务时必需的。要确保事先先安装好一个 ZooKeeper 集群。具体请参考:ZooKeeper-3.4.5 安装
以下操作均在主 Master(即 10.6.3.43)上进行操作
1. 下载安装 HBase
不同版本的 HBase 依赖于特定的 Hadoop 版本,应该选择最适合的 HBase 版本。笔者使用的 Hadoop-2.5.0-cdh5.3.2,ZooKeeper-3.4.5-cdh5.3.2。故本文所搭建的 HBase 版本为 HBase 0.98.6-cdh5.3.2,下载地址:http://archive.cloudera.com/cdh5/cdh/5/
下载后的 tar.gz 包先暂放在路径 ~/softwares/tar_packages 下
2. 创建安装目录
sudo mkdir -p /usr/local/cluster/hbase
sudo chown -R hadoop5:hadoop5 /usr/local/cluster/
3. 解压至安装目录下
sudo tar -zxvf ~/softwares/tar_packages/hbase-0.98.6-cdh5.3.2.tar.gz -C /usr/local/cluster/hbase --strip-components 1
sudo chown -R hadoop5:hadoop5 /usr/local/cluster/hbase
4. 编辑环境变量并使其生效
Note:这一步在 HBase 集群中的所有节点上都完成
vim ~/.bash_profile
添加如下:
export HBASE_HOME=/usr/local/cluster/hbase
export PATH=$PATH:$HBASE_HOME/bin
最后:
source ~/.bash_profile
在这个文件中还可以设置 HBase 的运行环境,诸如 Heap Size 和 其他有关 JVM 的选项,比如日志保存目录、进程优先级等。当然最重要的还是设置 JAVA_HOME 指向 java 安装的路径。
cd /usr/local/cluster/hbase/conf
vim hbase-env.sh
添加如下:
export JAVA_HOME=/usr/local/jdk1.8.0_60
export HBASE_CLASSPATH=/usr/local/cluster/hadoop/etc/hadoop
export HBASE_HEAPSIZE=4000
export HBASE_LOG_DIR=${HBASE_HOME}/logs
export HBASE_MANAGES_ZK=false
JAVA_HOME 和 HBASE_CLASSPATH 根据实际情况进行配置HBASE_HEAPSIZE 的大小根据你的集群配置,默认是 1000HBASE_LOG_DIR 是 HBase 日志存放位置HBASE_MANAGES_ZK=false 含义为 hbase 不托管 zookeeper 的启动与关闭,因为笔者的 ZooKeeper 是独立安装的vim hbase-site.xml
注意:接下来的配置均在两个 configuration 之间添加完成的,如下图所示
<property>
<name>hbase.rootdirname>
<value>hdfs://master5:8020/hbasevalue>
property><property>
<name>hbase.cluster.distributedname>
<value>truevalue>
property><property>
<name>hbase.mastername>
<value>60000value>
property><property>
<name>hbase.tmp.dirname>
<value>/usr/local/cluster/data/hbase-tmpvalue>
property><property>
<name>hbase.zookeeper.quorumname>
<value>slave51,slave52,slave53value>
property><property>
<name>hbase.zookeeper.property.dataDirname>
<value>/usr/local/cluster/zookeeper/datavalue>
property><property>
<name>hbase.zookeeper.property.clientPortname>
<value>2181value>
property><property>
<name>zookeeper.session.timeoutname>
<value>120000value>
property><property>
<name>hbase.regionserver.restart.on.zk.expirename>
<value>truevalue>
property>
更多配置请参考 :HBase 默认配置
1. hbase.rootdir
这个目录是 RegionServer 的共享目录,用来持久化 HBase。特别注意的是 hbase.rootdir 里面的 HDFS 地址是要跟 Hadoop 的 core-site.xml 里面的 fs.defaultFS 的 HDFS 的 IP 地址或者域名、端口必须一致。
2. hbase.cluster.distributed
HBase 的运行模式。为 false 表示单机模式,为 true 表示分布式模式。若为 false,HBase 和 ZooKeeper 会运行在同一个 JVM 中
3. hbase.master
4. hbase.tmp.dir
本地文件系统的临时文件夹。可以修改到一个更为持久的目录上。(/tmp会在重启时清除)
5. hbase.zookeeper.quorum
对于 ZooKeeper 的配置。至少要在 hbase.zookeeper.quorum 参数中列出全部的 ZooKeeper 的主机,用逗号隔开。该属性值的默认值为 localhost,这个值显然不能用于分布式应用中。
6. hbase.zookeeper.property.dataDir
这个参数用户设置 ZooKeeper 快照的存储位置,默认值为 /tmp,显然在重启的时候会清空。因为笔者的 ZooKeeper 是独立安装的,所以这里路径是指向了 $ZOOKEEPER_HOME/conf/zoo.cfg 中 dataDir 所设定的位置。
7. hbase.zookeeper.property.clientPort
表示客户端连接 ZooKeeper 的端口。
8. zookeeper.session.timeout
ZooKeeper 会话超时。Hbase 把这个值传递改 zk 集群,向它推荐一个会话的最大超时时间
9. hbase.regionserver.restart.on.zk.expire
当 regionserver 遇到 ZooKeeper session expired , regionserver 将选择 restart 而不是 abort。
在这里列出了希望运行的全部 Regionserver ,一行写一个主机名(就像 Hadoop 中的 slaves 一样)。这里列出的 Server 会随着集群的启动而启动,集群的停止而停止。
vim regionservers
添加如下:
slave51
slave52
slave53
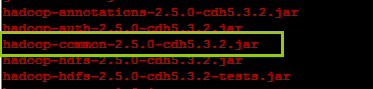
由于 HBase 依赖于 Hadoop,因此在安装包的 lib 文件夹下包含了一个 Hadoop 的核心 jar 文件。在分布式模式下,HBase 使用的 Hadoop 版本必须和运行中的 Hadoop 集群的 jar 文件版本一致。将运行的分布式 Hadoop 版本的 jar 文件替换 HBase 的 lib 目录下的 Hadoop 的 jar 文件,以避免版本不匹配问题。确认替换了集群中所有节点的 HBase 安装目录下 lib 目录的 jar 文件。Hadoop 版本不匹配问题有不同的表现,但看起来 HBase 像挂掉了。
但因为笔者所用的 HBase 是从 CDH 官网上直接下载配套 Hadoop-2.5.0-cdh5.3.2 版本的,其 lib 包下的已经替换了相关的 jar 包,如下所示:
如果读者的 hbase 包下并未替换,可以使用如下命令:
cp ${HADOOP_HOME}/share/hadoop/common/hadoop-common-2.5.0-cdh5.3.2.jar ${HBASE_HOME}/lib/
cd /usr/local/cluster/hbase/lib
mv slf4j-log4j12-1.7.5.jar slf4j-log4j12-1.7.5.jar.bak
如果不移除的话,将会出现以下 warning :
scp -r /usr/local/cluster/hbase/ hadoop5@master52:/usr/local/cluster/
scp -r /usr/local/cluster/hbase/ hadoop5@slave51:/usr/local/cluster/
scp -r /usr/local/cluster/hbase/ hadoop5@slave52:/usr/local/cluster/
scp -r /usr/local/cluster/hbase/ hadoop5@slave53:/usr/local/cluster/
友情提醒:在启动之前,笔者已经将 ZooKeeper 和 Hadoop (至少是 HDFS)给启动了。
1. 在其中一台主机上启动 Hmaster,即笔者在 master5 上,执行以下命令
start-hbase.sh
2. 在另一台 Hmaster 的主机上,即笔者在 master52 上,执行以下命令
hbase-daemon.sh start master
zkCli.sh
3. 查看相应进程
master5
master52
slave53
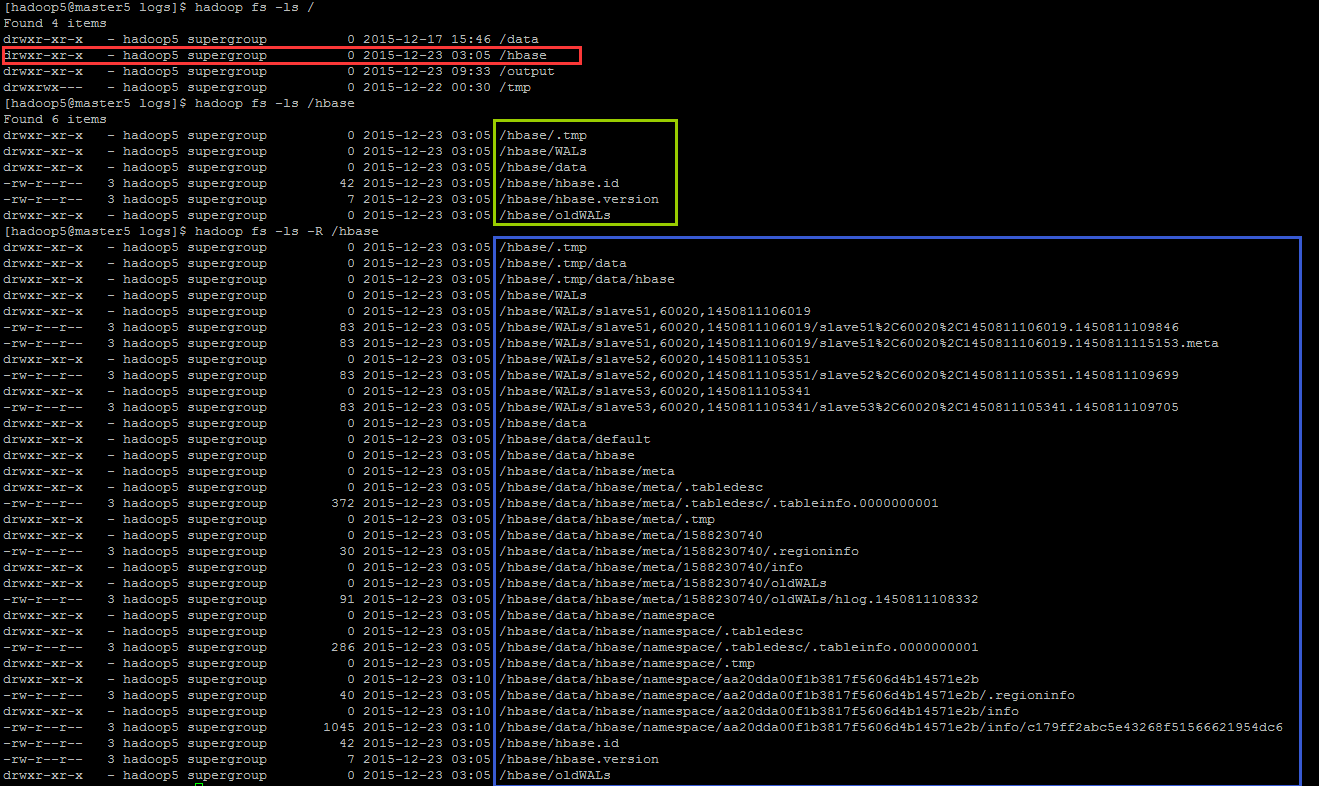
在 master5 上查看启动 HBase 后在 HDFS 上产的目录。该路径是由 hbase.rootdir 属性参数所决定的
hadoop fs -ls -R /hbase
今后 HBase 的数据就是存放在此了。
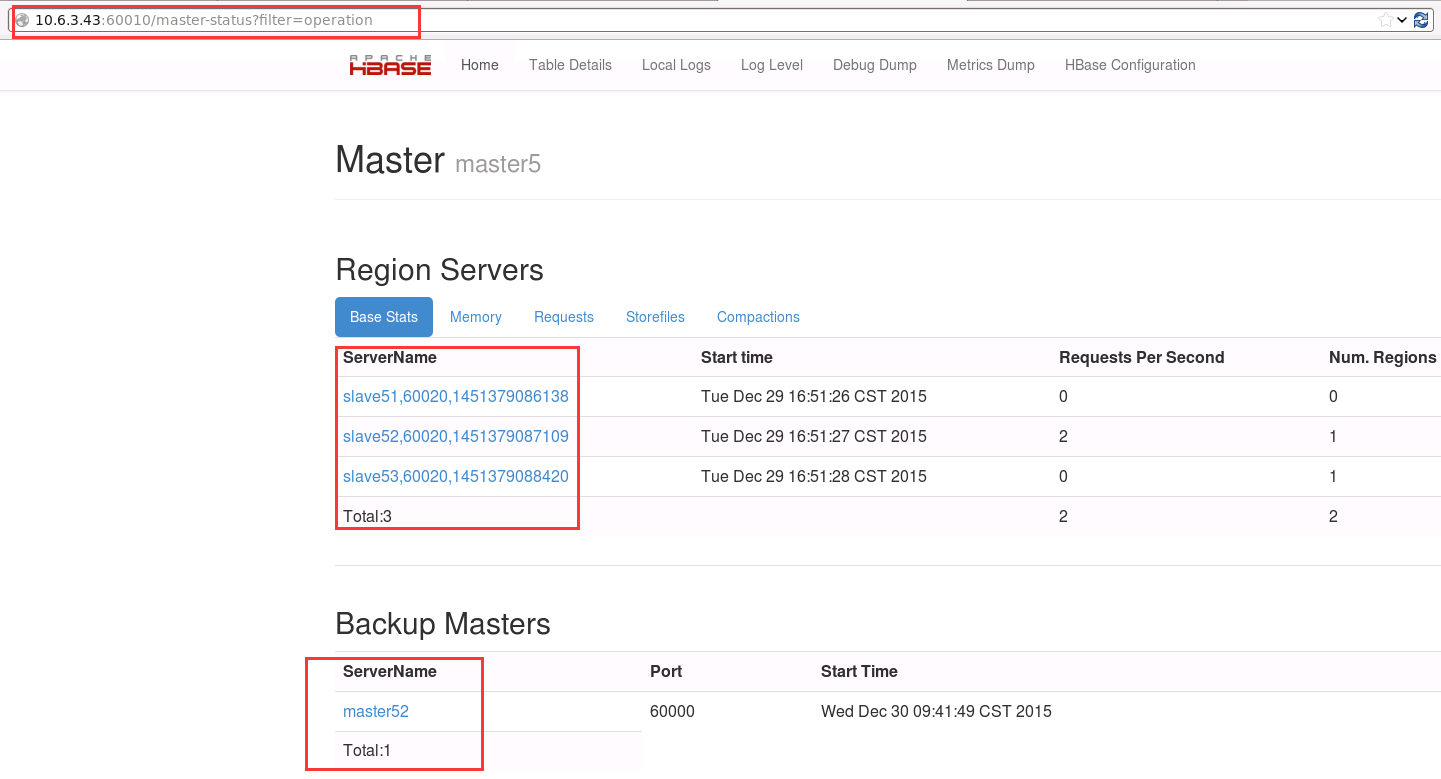
1. 当 master5 的 HBase 正常工作时
打开浏览器可以查看到:
10.6.3.43:60010
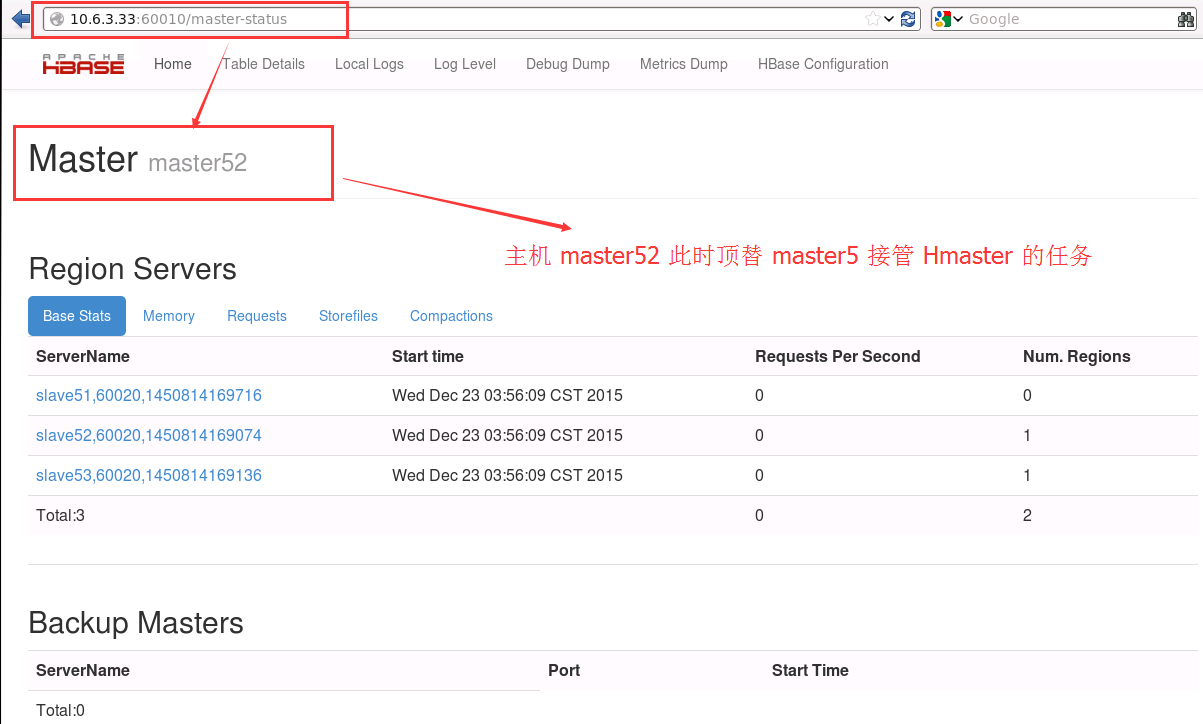
2. 模拟 master5 失效后 ,Hmaster 故障切换
hbase-daemon.sh stop master
10.6.3.33:60010
补充:关闭集群
Note:在关闭之前请确保 ZooKeeper 并没有关闭!
stop-hbase.sh
1. 进入hbase命令行
hbase shell
2. 建立一个表,具有三个列族member_id 、address、info
create &#39;member&#39;,&#39;member_id&#39;,&#39;address&#39;,&#39;info&#39;
3. 查看当前 HBase 中具有哪些表
list
4. 查看表的构造
describe &#39;member&#39;
5. 删除列族 member_id
drop &#39;member&#39;
6. 退出 shell 命令行
exit
只要上述操作无报错,那么恭喜你,安装成功!
HBase 和其他的数据库软件一样会同时打开很多文件。Linux 中默认的 ulimit 值是 1024,这对 HBase 来说太小了。当批量导入数据的时候会得到这样的异常信息: java.io.IOException:Too many open files 。我们需要改变这个值,注意,这是对操作系统的参数调整,而不是通过 HBase 配置文件来完成的。我们可以大致估算出 ulimit 值需要配置多大才合适。
存储文件个数 * 列族数 * 每个 RegionServer 中的 Region 数量 = RegionServer 主机管理的存储文件数量
假设每个 Region 有 3 个列族,每个列族平均有 3 个存储文件,每个 RegionServer 有 100 个 region ,将至少需要 3*3*100=900 个文件。这些存储文件会频繁被客户端调用,涉及大量的磁盘操作,应根据实际情况调整 ulimit 参数值的大小。
1. 关于 ulimit 有两个地方需要调整,通过在 /etc/security/limits.conf** 追加参数进行设置,一个参数是 nofile ,设置如下:**
soft nofile 10240
hard nofile 10240
如果 没有设置这个参数会得到上面说的异常。这个设置表示限制打开的文件数。这个配置不能及时生效,还需要通过 ulimit -n 设置。
ulimit -n 10240
2. 另一个参数是 noproc,这个配置是限制用户打开的进程数,设置如下:
soft noproc 10240
hard noproc 10240
该设置可以及时生效,可以通过 ulimit -c 查看。如果不设置 noproc 可能会得到如下异常:
java.lang.OutOfMemoryError:unable to create new native thread
实际上这两个参数对于 HDFS 和 MapReduce 也至关重要,应该在启动 Hadoop 之前就设置好。另外注意的是这两个参数针对操作系统用户的, * 代表对所有用户生效。
<property><name>hbase.master.maxclockskewname><value>180000value><description>Time difference of regionserver from masterdescription>property>
附:cm-5.13下hbase高可用配置:
1.很简单,安装hbase服务的时候,直接选定两个master节点(应该会自动判定主备master,我是先是单master,后又添加的master)。
2.完成后界面如下:(仅截取从节点的web ui 界面)
3.手动停止主master节点后,刷新备master节点ui界面:
4.完美达到预期
参考资料:





 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有