前提: 搭建好大数据环境(hadoop hive hbase sqoop zookeeper oozie hue)
1.将所有数据库的数据汇总到hive (这里有三种数据源 ORACLE MYSQL SEQSERVER)
全量数据抽取示例:
ORACLE(注意表名必须大写!!!)
sqoop import --connect jdbc:oracle:thin:@//10.11.22.33:1521/LPDR.china.com.hh --username root --password 1234 \
--table DATABASENAME.TABLENAME --hive-overwrite --hive-import --hive-database bgda_hw --hive-table lp_tablename \
--target-dir /user/hadouser_hw/tmp/lp_tablename --delete-target-dir \
--null-non-string '\\N' --null-string '\\N' \
--hive-drop-import-delims --verbose --m 1
MYSQL:
sqoop import --connect jdbc:mysql://10.33.44.55:3306/DATABASEBANE --username ROOT --password 1234 \
--query 'select * from DEMO t where t.DATE1
--target-dir /user/hadouser_hw/tmp/DEMO --delete-target-dir \
--null-non-string '\\N' --null-string '\\N' \
--hive-drop-import-delims --verbose --m 1
SQLSERVER:
sqoop import --connect 'jdbc:sqlserver://10.55.66.15:1433;username=ROOT;password=ROOT;database=db_DD' \
--query 'select * from TABLE t where t.tasktime
--target-dir /user/hadouser_hw/tmp/TABLENAME --delete-target-dir \
--null-non-string '\\N' --null-string '\\N' \
--hive-drop-import-delims --verbose --m 1
2. 编写hive脚本,对数据进行处理
说明:
data 存储T+1跑出来的数据信息,只存一天的数据量
data_bak : 存储所有的数据信息
(初始化脚本)
use bgda_hw;
set hive.auto.convert.join=false;drop table data_bak;
create table data_bak(scanopt string ,scanoptname string ,statisdate string
) row format delimited fields terminated by '\001'; insert overwrite table data_bak
SELECT
a.scanopt
,x0.name as scanoptname
,to_date(a.scandate) as statisdate
from bgda_hw.scan a
left outer join bgda_hw.user x0 on x0.userid = a.scanopt
where 1=1
and datediff(a.scandate,'2019-01-01' )>=0
and datediff(a.scandate,&#39;2019-09-20&#39; )<0
GROUP BY a.scanopt,x0.name,a.scandate
order by a.scandate
;
&#xff08;t&#43;1脚本&#xff09;
use bgda_hw;
set hive.auto.convert.join&#61;false;drop table data;
create table data(scanopt string ,scanoptname string ,statisdate string
) row format delimited fields terminated by &#39;\001&#39;; insert overwrite table data
SELECT
a.scanopt
,x0.name as scanoptname
,to_date(a.scandate) as statisdate
from bgda_hw.scan a
left outer join bgda_hw.user x0 on x0.userid &#61; a.scanopt
where 1&#61;1
and a.scandate
GROUP BY a.scanopt,x0.name,a.scandate
order by a.scandate
;insert into table data_bak
select * from data
;
3.将结果数据抽取到结果库里
sqoop export \
--connect jdbc:mysql://10.6.0.115:3306/report \
--username root \
--password 1234 \
--table data \
--export-dir /user/hive/warehouse/bgda_hw.db/data \
--columns scanopt,scanoptname,statisdate \
--fields-terminated-by &#39;\001&#39; \
--lines-terminated-by &#39;\n&#39; \
--input-null-string &#39;\\N&#39; \
--input-null-non-string &#39;\\N&#39;
4.定义调度信息&#xff08;oozie&#xff09;,每天定时跑出结果数据&#xff0c;自动抽取到结果库中
HUE的基本使用
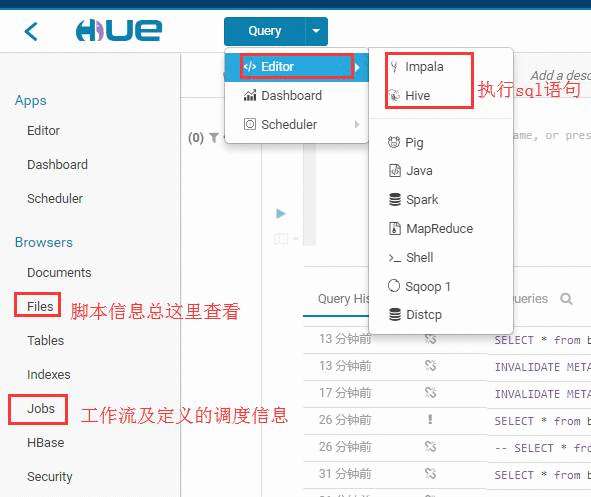
定义工作流信息
先进入workflow

开始定义

选定要执行的脚本

定义定时任务
先进入定时任务页面

新建定时任务

定时任务详细定义&#xff08;点击Options ,选择ShangHai时区&#xff0c;然后定义任务执行时长&#xff08;例如 从2019年到2099年&#xff0c;最后保存&#xff0c;保存好后记得点击执行&#xff01;&#xff01;&#xff01;&#xff09;&#xff09;

5.配置可视化组件展示数据 saiku
这部分详细教程请参考 https://www.cnblogs.com/DFX339/tag/saiku/








 京公网安备 11010802041100号
京公网安备 11010802041100号