篇首语:本文由编程笔记#小编为大家整理,主要介绍了AIOps关键技术:日志模板提取相关的知识,希望对你有一定的参考价值。
日志是AIOps需要处理常见数据,是程序运行过程中由代码打印出的一些程序完成的任务和系统的状态。从属于非结构化文本的日志数据中提炼特征挑战性大,不能简单采用NLP(自然语言处理)方法,需要首先结合运维领域知识从日志中提炼日志模板(事件)。本文介绍清华NetMan实验室发表在IWQoS 2017的研究成果:FT-Tree——一种新型的日志模板提取技术,用于准确地和增量式地学习交换机日志模板。该系统被用于NetMan实验室发表在SIGMETRICS 2018 上数据中心。
在数据中心中,对于交换机故障的诊断和预测来说,交换机系统日志是一个丰富的信息源。但是,只有通过对系统日志合理地处理之后,这些信息才能被有效的提取出来。
一种通用的系统日志预处理的方法是从历史系统日志消息中提取模板,然后,将系统日志消息映射到模板上。但是,当前提出的模板提取方法或者在学习“正确” 模板集合时准确性较低,或者不支持增量式学习。当模板提取放法不支持增量式学习时,如果一种新的模板加入,所有的历史系统日志消息都要被重新处理一遍以重新构建整个模板集合。这对于大型的数据中心网络来说,将消耗太多的计算资源。因此,我们提出了FT-Tree,它能够比现有方法更加准确地提取消息模板,并从本质上支持增量式学习。
从交换机日志中提取消息模板会面临如下挑战:
1、非结构化:交换机系统日志消息通常是非结构化的文本。
2、数据量大:数据中心中每天会产生数以千万计的系统日志信息。
3、类型多样:交换机日志会随着设备厂商和设备型号的变化而变化。
系统日志处理的目的是不依赖于任何专家知识,自动地从系统日志中提取模板——系统日志消息中详细信息字段的子类型。FT-tree 是一种扩展的前缀树结构,用以表示交换机系统日志消息模板。FT-tree 的基本思想是,系统日志消息中详细信息字段的子类型通常是频繁出现的单词的最长组合。因此,提取模板等价于从系统日志消息中识别出频繁出现单词的最长组合。下面通过一个具体的实例来介绍FT-tree的构建过程。
FT-tree构建过程
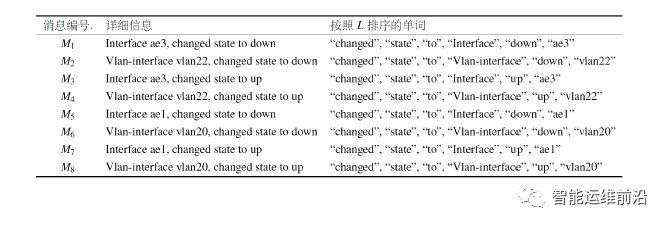
令DM = (M1, M2, ..., Mn) 为系统日志消息的集合,每个Mi 是一条系统日志消息。I = (a1, a2, ..., am) 是系统日志消息集合中出现的不同单词的集合。一个单词组合(即单词的集合) A 的支持度(即单词出现的频率) 等于DM 中包含A 的系统⽇志消息的数量。如果A 频繁地出现(即具有较大的支持度),那么A 就是一个模板。例如下表的第二列展示了日志消息的集合DM = (M1, M2, ..., M8),其中每条日志都是属于”SIF”类型。
我们首先扫描一次DM, 并且以每个单词出现频率(每个”:”之后的数字)的降序得到一个列表L。例如,L = <(“changed”:8),(“state”:8), (“to”:8), (“Interface”:4), (“Vlan-interface”:4), (“down”:4), (“up”:4), (“ae3”:2),(“ae1”:2), (“vlan22”:2), (“vlan20”:2)>。
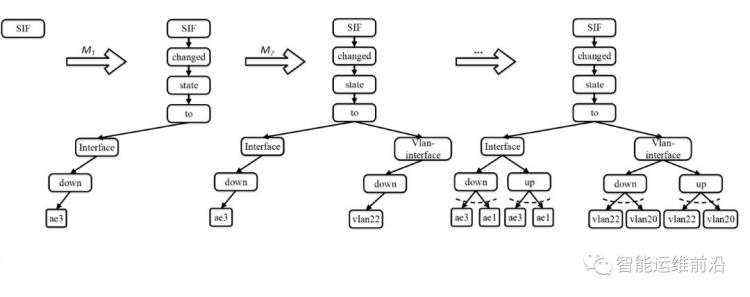
然后,创建树的根节点,这一根节点是由消息类型标记的,如下图中第一步所示,在本文中树的根节点是“SIF”。之后,FT-tree第二次扫描DM。通过处理M1,得到树的第一条路径如下<“changed”, “state”, “to”, “Interface”, “down”, “ae3”>,这些单词是根据L中单词的顺序排序的。当处理M2 时,因为它排完序的单词列表<“changed”, “state”, “to”, “Vlan-interface”, “down”, “vlan22”> 与已存在的路径/分支<“changed”, “state”, “to”, “Interface”, “down”, “ae3”> 共享一个共同前缀<“changed”, “state”, “to”>,所以,FT-tree 需要创建一个新的分支<“Vlan-interface”,“down”,“vlan22”> 作为节点“to”的子树。同理,剩余的6 条系统日志消息的处理方式也是一样的。最后,得到的FT-tree 如下图最右边的树所示。
最后,修剪FT-tree,直到它满足以下节点的度的约束。直观地来看,每个消息类型应该只有少量的子类型。并且,对于每个子类型,应该有许多不同的系统日志消息与之匹配。因此,如果FT-tree的一个节点有太多的子节点,那么它的所有子节点就从FT-tree 中删除。这样,该子节点就变成叶节点。
增量式模板学习
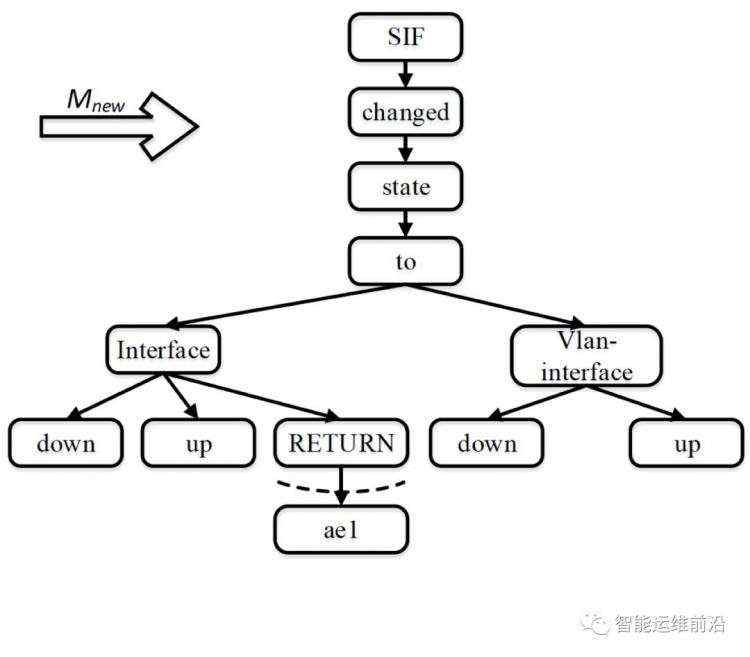
对于一个给定的系统日志消息的消息类型,由于操作系统或固件升级,可能会出现新的子类型消息。此时,需要生成新的消息模板,以匹配这些新的子类型的系统日志消息,这是通过向FT-tree 中插入新的节点来完成的。如下图所示,假设交换机生成了新的系统日志消息Mnew =“Interface ae1 changed state to RETURN”。并且,在此之前,FT-tree 是上图中最右边的树,且所有子节点(“ae3”, “ae1”, “vlan22” 等)已经都被剪枝。然后,新的系统日志消息Mnew 生成后,需要将分支(“RETURN”→“ae1”)插入到FT-tree 中。
我们使用了从真实收集的交换机系统日志和交换机故障记录,比较了FT-tree与特征树、STE和LogSimilarity三种现有方法在模板学习和交换机故障预测方面的性能,从而对FT-tree进行评价和验证。
评价模板学习的准确性
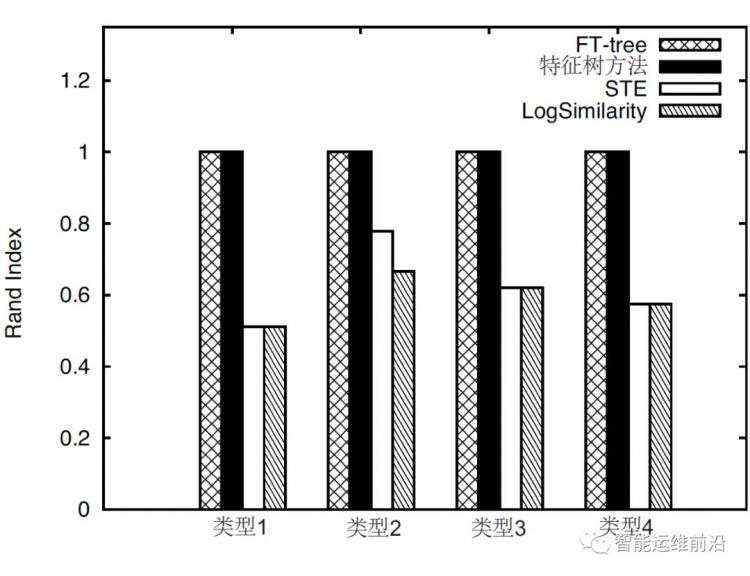
我们随机地收集了500条日志消息。然后基于每条系统日志消息代表的事件,由运维人员人工地对系统日志消息分类。然后分别运行FT-tree、特征树方法、STE 和LogSimilarity,以学习上述日志消息的模板,然后使用了RandIndex方法(一种流行的用于评估两种数据 聚类算法之间相似性的方法)来定量比较四种算法的准确性。从下图中我们可以看出,FT-tree 和特征树方法的平均Rand index 接近于1.0 ,且在所有四种消息类型中均表现得很好,然而,FT-tree 可以构造树并增量式地学习系统日志消息模板,但是特征树方法却不能,所以FT-Tree更适合于系统日志模板的提取。
评价故障预测的准确性
下图展示了FT-tree, 特征树,STE和LogSimilarity四中算法的故障预测结果的PR曲线,从PR 曲线可以看出,在预测故障时,应用FT-tree 和特征树方法以学习系统日志消息模板,比应用STE 和LogSimilarity 能够取得更高的准确性。
1、数据中心中的交换机每天产生大量的日志,运维工程师只关心某几类日志,比如端口Up/Down,并且希望过滤掉其他的常态日志,然后由工程师标记其关心的日志模板。当新产生的日志到来后,如果能与已标记的模板,则显示在日志查询系统中,这样可以极大的减少运维工程师查询日志的工作量。类似的功能已在某公司的日志白名单系统中线上使用。
2、许多基于日志的异常检测工作都是分为四个步骤,分别是日志收集、日志预处理、特征提取以及异常检测。本文中提到的日支模板提取就是用在第二步日志预处理中。换句话说,如果设备产生的日志数据实时地转换成日志模板编号,那日志文本处理的问题就转换成了时间序列处理。
本文介绍了一种新型的模板提取技术——FT-tree,用于准确地和增量式地学习模板。我们使用真实的2 年的交换机故障案例和系统日志来评价和对于FT-tree和现有方法的性能,评价实验结果清楚地证明了FT-tree 的优点:高准确性,低计算成本和可增量式学习。
论文题目:Syslog Processing for Switch Failure Diagnosis and Prediction in Datacenter Networks
论文链接:请点击文末右下角“阅读原文”









 京公网安备 11010802041100号
京公网安备 11010802041100号