作者:aatwo19668035 | 来源:互联网 | 2023-09-16 11:00
在上一篇博客中,介绍了关键词提取的无监督方法:点击这里查看文章。本篇主要是介绍关键词提取的有监督方法。
可以从如下角度去做有监督学习:
二分类模型:短语是否为关键短语。 LTR(learn to rank):学习排序模型,选取top K 的作为关键短语。 encoder-decoder:类似翻译的思想,将文本作为源语言,关键短语作为目标语言。 序列标注:类似于实体识别的思路,实体识别提取实体词,这里提取关键短语。 对于上述的每种方法,都用1~2个模型去说明。
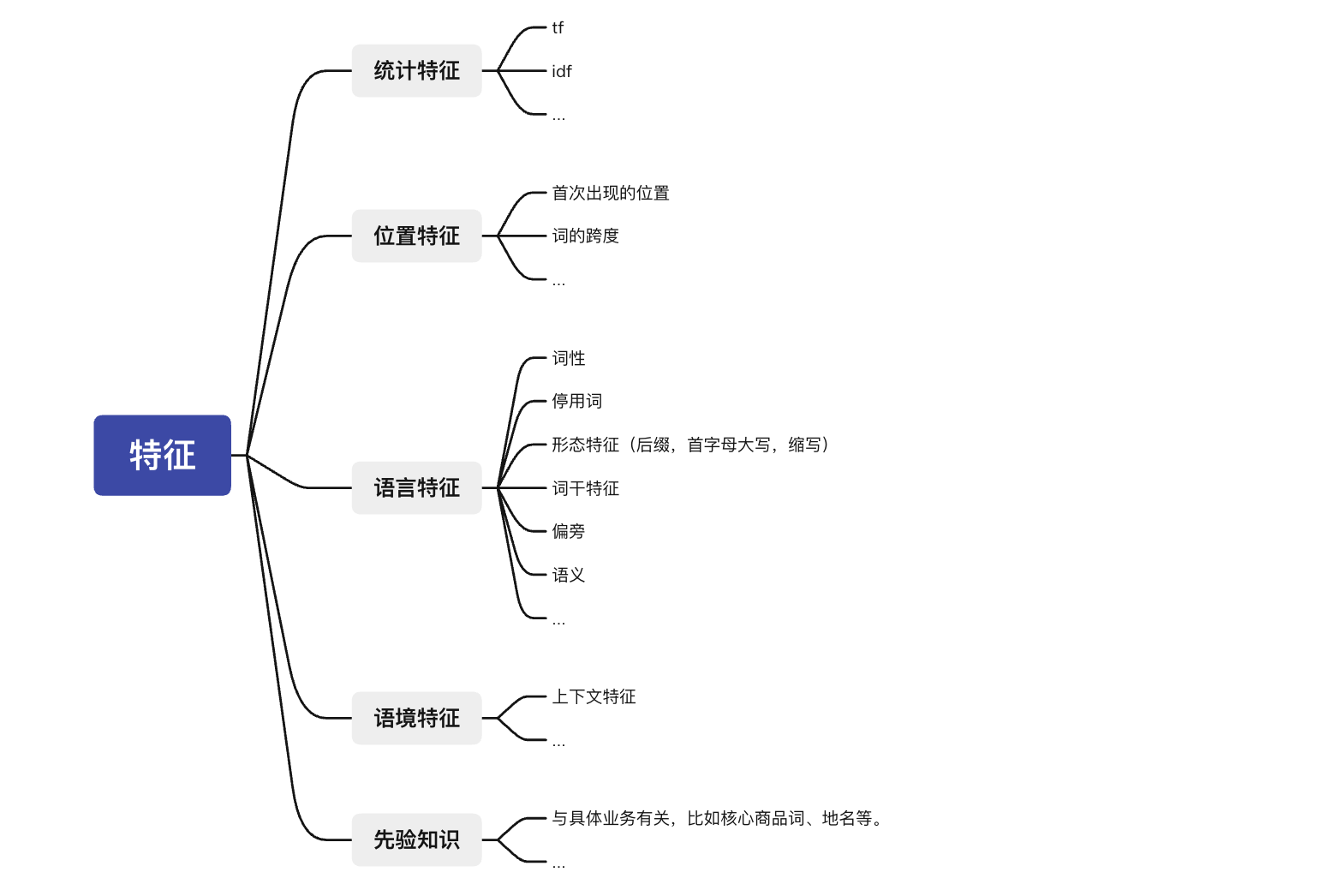
特征
LTR RankingSVM
使用的特征:
The features include TF-IDF score, phrase length, position of phrase’s first occurrence, phrase’s appearance in document title, uniformity of phrase’s distribution within document (measured by entropy), frequency of most and least frequent word of phrase, etc.
rankingsvm简介:
rankingsvm是一种pointwise的排序算法。给定文档dd d k1>k2>k3k_1>k_2>k_3 k 1 > k 2 > k 3 k1k_1 k 1 k2,k3k_2,k_3 k 2 , k 3 x1,x2,x3x_1,x_2,x_3 x 1 , x 2 , x 3 k1,k2,k3k_1,k_2,k_3 k 1 , k 2 , k 3 x1−x2,x1−x3,x2−x3x_1-x_2,x_1-x_3,x_2-x_3 x 1 − x 2 , x 1 − x 3 , x 2 − x 3 x2−x1,x3−x1,x3−x2x_2-x_1,x_3-x_1,x_3-x_2 x 2 − x 1 , x 3 − x 1 , x 3 − x 2
Bert-KPE
Encoder-Decoder 论文Deep Keyphrase Generation中使用encoder-decoder完成关键词的抽取。
Deep Keyphrase Generation的源码地址。
Deep Keyphrase Generation:
问题定义:
假设语料库中包含N条语料,对于其中的第ii i (x(i),p(i))(x^{(i)},p^{(i)}) ( x ( i ) , p ( i ) ) x(i)x^{(i)} x ( i ) p(i)p^{(i)} p ( i ) MiM_i M i MiM_i M i p(i)=(p(i,1),⋯,p(i,Mi))p^{(i)}=(p^{(i,1)},\cdots,p^{(i,M_i)}) p ( i ) = ( p ( i , 1 ) , ⋯ , p ( i , M i ) ) (x(i),p(i))(x^{(i)},p^{(i)}) ( x ( i ) , p ( i ) ) MiM_i M i ((xi,p(i,1)),⋯,(xip(i,Mi)))((x^{i},p^{(i,1)}),\cdots,(x^{i}p^{(i,M_i)})) ( ( x i , p ( i , 1 ) ) , ⋯ , ( x i p ( i , M i ) ) ) (x,y)(x,y) ( x , y )
encoder-decoder model:cc c cc c f,qf,q f , q cc c
decoder部分:将cc c y=(y1,y2,⋯,yT′)y=(y_1,y_2,\cdots,y_{T'}) y = ( y 1 , y 2 , ⋯ , y T ′ ) sts_t s t
encoder 和 decoder 的细节:HH H SS S 而重要的短语其实与其所在的位置以及语法信息有关,Copying Mechanism通过从原文中获取word,从而能够输出OOV,但包含在源文本中的词。
那么,新的概率分布定义如下:pgp_g p g pcp_c p c
序列标注 BiLSTM-CRF:
关于序列标注的更多细节,可以看我的下一篇博客: 命名实体识别。
参考 https://zhuanlan.zhihu.com/p/163426574
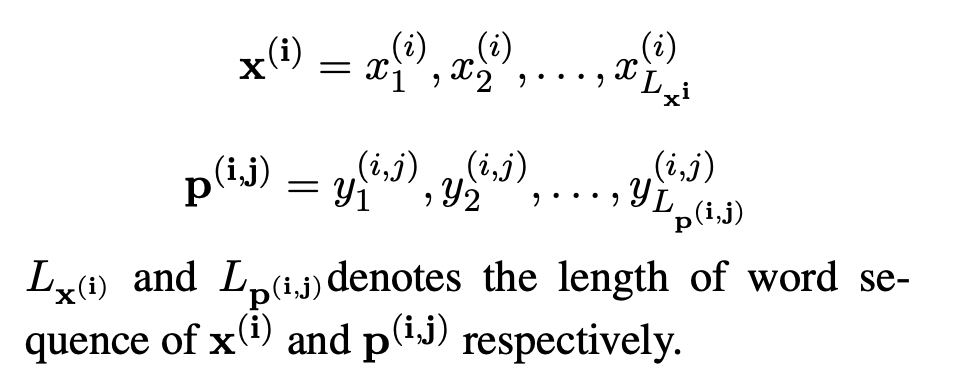
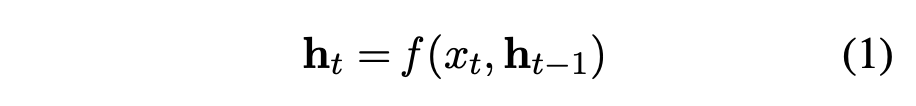
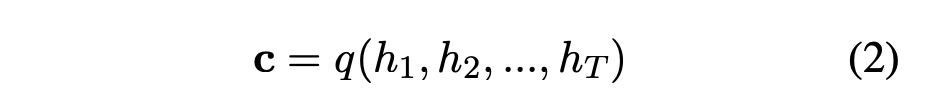
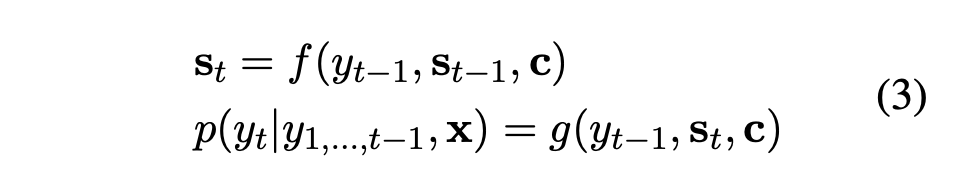
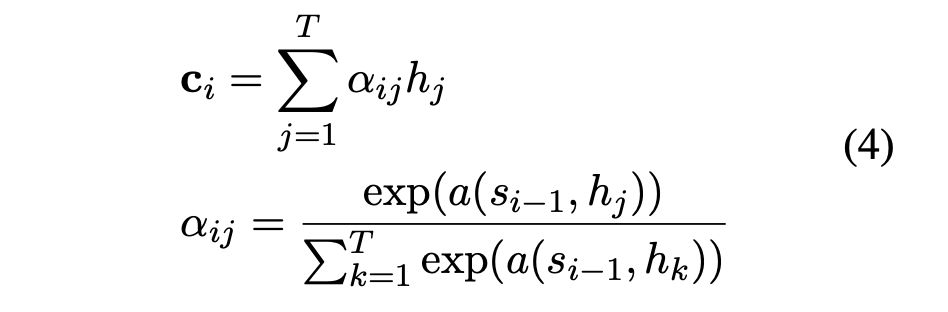
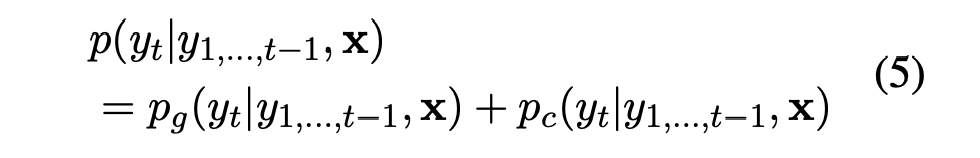








 京公网安备 11010802041100号
京公网安备 11010802041100号