一、Goroutine
Go 协程可以看做成一个轻量级的线程,Go 协程相比于线程的优势:
Goroutine 的成本更低大小只有 2 kb 左右,线程有几个兆。
Goroutine 会复用线程,比如说:我有 100 个协程,但是都是共用的的 3 个线程。
Goroutine 之间通信是通过 channel 通信的。(Go 推崇的是信道通信,而不推崇用共享变量通信)
1、启动一个 Goroutine
func test() {
fmt.Println("go go go")
}
func main() {
fmt.Println("主线程开始")
// go 关键字开启 Goroutine,一个 Goroutine只占2kb左右
go test() // 一个 go 就是一个协程,多个就是多个协程,也可以for循环起多个协程
go test()
time.Sleep(1*time.Second) // Go 语言中主线程不会等待Goroutine执行完成,要等待它结束需要自己处理
fmt.Println("主线程结束")
}
// 输出:
主线程开始
go go go
go go go
主线程结束
2、Go 语言的GMP模型
G:就是我们开起的 Goroutine
- 它们会被相对平均的放到 P 的队列中
M:M 可以当成操作系统真正的线程,但是实际上是用户态的线程(用户线程)
- 虽然 M 执行 G,但是实际上,M 只是映射到操作系统的线程上执行的
- 然后操作系统的调度器把真正的操作系统的线程调度到CPU上执行
P:Processor 1.5版本以后默认情况是 CPU 核数(可以当做CPU核数)
- P 会和 M 做交互,真正执行的是 M 在执行 G ,只不过 P 是在做调度
- 一旦某个 G 阻塞了,那么 P 就会把它调度成下一个 G,放到 M 里面去执行
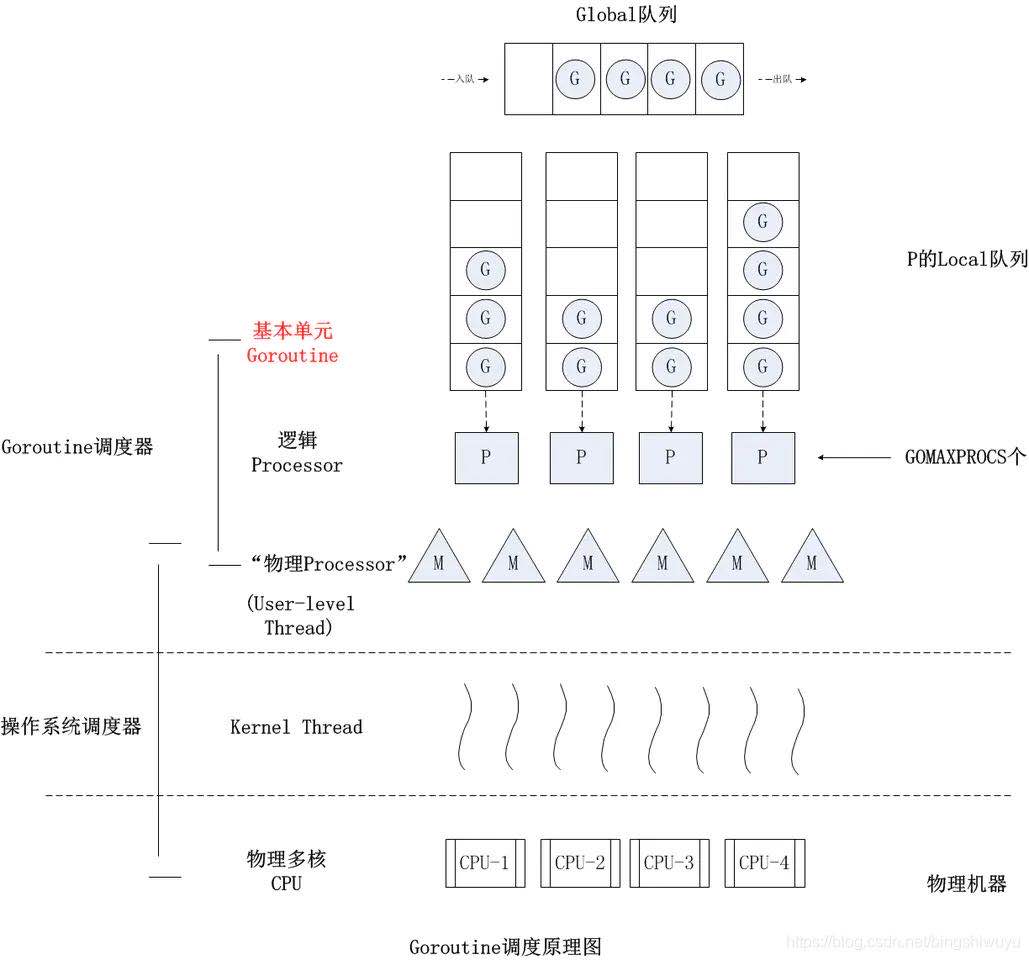
用户线程操作系统线程:
在 Python 中,用户线程跟操作系统线程是 1:1 的对应关系
Go 语言中,用户线程和操作系统线程是 m:n 的关系
二、信道
信道(Channel)也就是 Go 协程之间的通信管道,一端发送一端接收。
func main() {
// 1、定义 channel
var c chan int
// 2、管道的零值
//———>空值为 nil 说明是引用类型,当做参数传递时,不需要取地址,改的就是原来的,需要初始化在使用
fmt.Println(c) // 输出:
// 3、管道初始化
c = make(chan int)
go test(c) // c 是引用类型直接传
// 4、从信道中取值,信道默认不管放值还是取值,都是阻塞的
count := <-c // 阻塞
fmt.Println(count)
/*
当程序执行 go test(c) 时就开了一个 Goroutine
然后继续执行到 count := <-c 从信道取值,这时就阻塞住了
它会等待 Goroutine 往信道中放值后才会取出值,才会继续执行 fmt.Println(count)
*/
}
func test(c chan int) {
fmt.Println("GO GO GO")
time.Sleep(1 * time.Second)
// 5、往信道中放一个值,信道默认不管放值还是取值,都是阻塞的
c <- 1 // 阻塞
}
// 输出:
GO GO GO
1
1、死锁
当 Goroutine 给一个信道放值的时候,按理会有其他 Goroutine 来接收数据,没有的话就会形成死锁。
func main() {
c := make(chan int)
c <- 1
}
// 报错:应为没有其他 Goroutine 从 c 中取值
2、单向信道
显而易见就是只能读或者只能写的信道
方式一:
func WriteOnly(c chan<- int) {
c <- 1
}
func main() {
write := make(chan<- int) // 只写信道
go WriteOnly(write)
fmt.Println(<-write) // 报错 ——>只写信道往外取就报错
}
方式二:
func WriteOnly(c chan<- int) {
c <- 1
// <-c // 报错
}
func main() {
write := make(chan int) // 定义一个可读可写信道
go WriteOnly(write) // 传到函数中就成了只写信道,在Goroutine中只负责写,不能往外读
fmt.Println(<-write) // 主协程读
}
3、for 循环信道
for 循环循环信道,如果不关闭,会报死锁,如果关闭了,放不进去,循环结束。
func producer(chnl chan int) {
for i := 0; i <10; i++ {
chnl <- i // i 放入信道
}
close(chnl) // 关闭信道
}
func main() {
ch := make(chan int)
go producer(ch)
// 循环获取信道内容
for value := range ch {
fmt.Println(value)
}
}
/*
当 for 循环 range ch 的时候信道没有值,会阻塞等待 go producer(ch) 开起的 Goroutine 中放入值
当 Goroutine 中放入一个值,就会阻塞,那么 range ch 就会取出一个值,然后再次阻塞等待
直到 Goroutine 放入值完毕关闭信道,for 循环 range ch 也就结束循环了
*/
4、缓冲信道
在默认情况下信道是阻塞的,缓冲信道也就是说我信道里面可以缓冲一些东西,可以不阻塞了。
只有在缓冲已满的情况,才会阻塞信道
只有在缓冲为空的时候,才会阻塞主缓冲信道接收数据
func main() {
// 指定的数字就是缓冲大小
var c chan int = make(chan int, 3) // 无缓冲信道数字是0
c <- 1
c <- 2
c <- 3
c <- 4 // 缓冲满了,死锁
<-c
<-c
<-c
<-c // 取空了,死锁
fmt.Println(len(c)) // 长度:目前放了多少
fmt.Println(cap(c)) // 容量:可以最多放多少
}
5、WaitGroup
等待所有 Goroutine 执行完成
func process1(i int, wg *sync.WaitGroup) {
fmt.Println("started Goroutine ", i)
time.Sleep(2 * time.Second)
fmt.Printf("Goroutine %d ended
", i)
// 3、一旦有一个完成,减一
wg.Done()
}
func main() {
var wg sync.WaitGroup // 没有初始化,值类型,当做参数传递,需要取地址
for i := 0; i <10; i++ {
wg.Add(1) // 1、启动一个 Goroutine,add 加 1
go process1(i, &wg) // 2、把wg传过去,因为要改它并且它是值类型需要取地址传过去
}
wg.Wait() // 4、一直阻塞在这,直到调用了10个 Done,计数器减到零
}
6、Select
Select 语句用于在多个发送 / 接收信道操作中进行选择。
例如:我要去爬百度,我发送了三个请求去,可能有一些网络原因,或者其他原因,不一定谁先回来,Select 选择就是谁先回来我先用谁。
场景一:对性能极致的要求,我就可以选择一个最快的线路执行我最快的功能,就可以用Select来做
场景二:我去拿这个数据的时候,不是一直等在这里,而是我可以干一点别的事情,使用死循环 Select 的时候加上 default 去做其他事情。
// 模拟去服务器去取值
func server(ch chan string) {
time.Sleep(3 * time.Second)
ch <- "from server"
}
func main() {
output1 := make(chan string)
output2 := make(chan string)
// 开起两个协程执行 server
go server(output1)
go server(output2)
select {
case s1 := <-output1: // 阻塞,谁先回来就执行谁
fmt.Println(s1, "output1")
case s2 := <-output2: // 阻塞,谁先回来就执行谁
fmt.Println(s2, "output2")
}
}
7、Mutex
使用锁的场景:多个 Goroutine 通过共享内存来实现数据通信,就会出现并发安全的问题,并发安全的问题就需要加锁。
临界区:当程序并发运行时修改共享资源的代码,也就同一块内存的变量的时候,这些修改的资源的代码就称为临界区。
如果在任意时刻只允许一个 Goroutine 访问临界区,那么就可以避免竞争条件,而使用 Mutex(锁) 可以实现
不加用锁的情况下:
var x = 0 //全局,各个 Goroutine 都可以拿到并且操作
func increment(wg *sync.WaitGroup) {
x = x + 1
wg.Done()
}
func main() {
var w sync.WaitGroup
for i := 0; i <1000; i++ {
w.Add(1)
go increment(&w)
}
w.Wait()
fmt.Println("最终的值:", x)
}
// 输出:理想情况下是1000,因为并发有安全的问题,所以数据乱了
最终的值: 978
加锁的情况:
var x = 0 //全局,各个 Goroutine 都可以拿到并且操作
func increment(wg *sync.WaitGroup, m *sync.Mutex) {
m.Lock() // 加锁
x = x + 1 // 同一时间只能有一个 Goroutine 执行
m.Unlock() // 解锁
wg.Done()
}
func main() {
var w sync.WaitGroup
var m sync.Mutex // 因为是个值类型,函数传递需要传地址
fmt.Println(m) // 输出:{0 0} ——>值类型
for i := 0; i <1000; i++ {
w.Add(1)
go increment(&w, &m)
}
w.Wait()
fmt.Println("最终的值:", x)
}
// 输出:
最终的值: 1000
使用信道来实现:
var x = 0
func increment(wg *sync.WaitGroup, ch chan bool) {
ch <- true // 缓冲信道放满了,就会阻塞。
x = x + 1
<-ch // 执行完了就取出
wg.Done()
}
func main() {
var w sync.WaitGroup
ch := make(chan bool, 1) // 定义了一个有缓存大小为1的信道
for i := 0; i <1000; i++ {
w.Add(1)
go increment(&w, ch)
}
w.Wait()
fmt.Println("最终的值:", x)
}
// 输出:
最终的值:1000
总结:不同 Goroutine 之间传递数据的方式:共享变量、信道。
如果是修改变量,倾向于用 Mutex
如果是 Goroutine 之间通信,倾向于用信道
三、异常处理
defer:延时执行,并且即便程序出现严重错误,也会执行
func main() {
defer fmt.Println("我最后执行")
defer fmt.Println("我倒数第三执行")
fmt.Println("我先执行")
var a []int
fmt.Println(a[10]) // 报错
fmt.Println("后执行") // 不会执行了
}
// 输出:
我先执行
我倒数第三执行
我最后执行
panic: runtime error: index out of range [10] with length 0
panic:主动抛出异常
recover:恢复程序,继续执行
func f1() {
fmt.Println("f1 f1")
}
func f2() {
defer func() { // 这个匿名函数永远会执行
//如果没有错误,执行 recover 会返回 nil,如果有错误执行 recover 会返回错误信息
if error := recover(); error != nil {
// 表示出错了,打印一下错误信息,程序恢复了,继续执行
fmt.Println(error)
}
fmt.Println("我永远会执行,不管是否出错")
}()
fmt.Println("f2 f2")
panic("主动抛出错误")
}
func f3() {
fmt.Println("f3 f3")
}
func main() {
//捕获异常,处理异常,让程序继续运行
f1()
f2()
f3()
}
Go 语言异常捕获与 Python 异常捕获对比
Python:
try:
可能会错误的代码
except Exception as e:
print(e)
finally:
无论是否出错,都会执行的代码
Go :
defer func() {
if error:=recover();error!=nil{
// 错误信息 error
fmt.Println(error)
}
相当于finally,无论是否出错,都会执行的代码
}()
可能会错误的代码









 京公网安备 11010802041100号
京公网安备 11010802041100号