Nginx (web server,web reverse proxy)
重点是反向代理
http协议:80/tcp 超文本传输协议,为了传输超文本例如html
html:超文本标记语言
文本:HTTP/1.0,MIME
一,MIME
MIME: Multipurpose Internet Mail Extension 多功能因特网邮件扩展,也能过支持多媒体
MIME类型是由一个媒体类型和一个子类型组成。媒体类型和子类型用一个斜杠(/)分隔开,例如text/css,它会告诉浏览器文件是纯文本文件,也是一个CSS样式表。每一个媒体类型都表示一种文件类型,媒体类型及说明见下表。
一 媒体类型及说明
MIME类型
二,web服务器url解析,请求报文及响应报文
web服务器,如果访问资源,必须靠url标记
-
:// : @ : / : ? # - 最重要的3个部分:
- scheme:方案,访问服务器以获取资源时要使用哪种协议,如:http 【最重要】
- host:主机,资源宿主服务器的主机名,ip地址 【最重要】
- path:路径,服务端上的资源本地名,由斜杠分割开来,如:index.html 【最重要】
- user:password,访问资源时需要的用户名和密码,中间冒号不能丢
- port:端口,默认端口为80
- params:参数,参数为名/值对(如:name='xiaodeng'),url可以包含多个参数字段,他们之间以及与路径的其余部分之间用‘&’分隔。
- query:查询,用字符‘?’将其与url的其他部分分割开来
通过url来标记众多资源,因此互联网的资源至少有一个标识
用户代理跟服务器资源交互,这一次叫http事物
基本流程:
a. 域名解析
b. 发起TCP的3次握手
c. 建立TCP连接后发起http请求
d. 服务器端响应http请求,浏览器得到html代码
e. 浏览器解析html代码,并请求html代码中的资源
f. 浏览器对页面进行渲染呈现给用户
报文:
有两部分组成:request Message(请求报文)response Message(响应报文)
请求方一般是有用户代理发起的,响应服务器端进行响应,为了能够二者之前的请求响应能够互相通信,要借助于底层的tcp/ip协议通信子网来完成通信
但http自己的工作流程则在应用层协议,http请求协议的报文中得以维持和包含
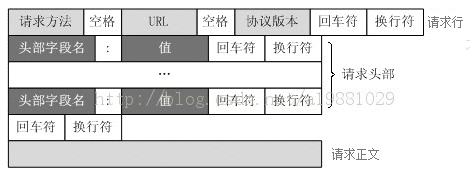
http请求报文格式:
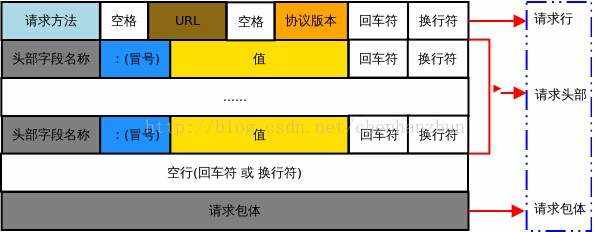
一个HTTP请求报文由请求行(request line)、请求头部(header)、空行和请求数据4个部分组成

If-Modified-Since
If-None-Match
在缓存中作用比较大
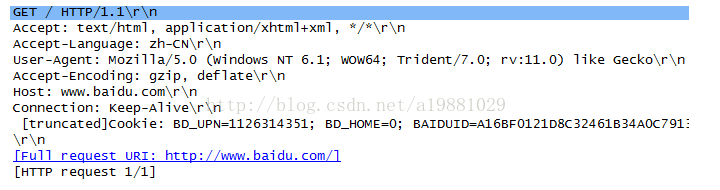
例子:
GAT
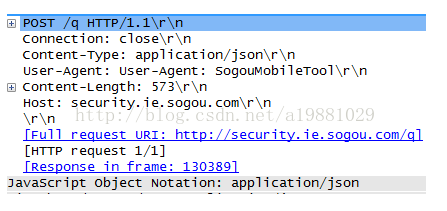
POST
http响应报文格式:
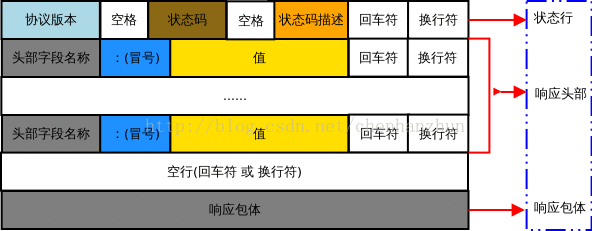
一个HTTP请求报文由状态行、响应头部、空行和响应主体4个部分组成
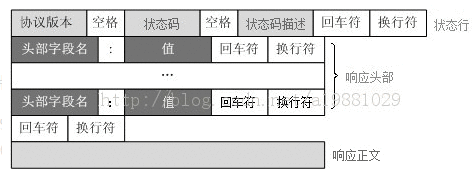
请求行:
响应头部:
响应主体:
状态行:
由3部分组成,分别为:协议版本,状态码,状态码描述,之间由空格分隔
状态代码为3位数字,200~299的状态码表示成功,300~399的状态码指资源重定向,400~499的状态码指客户端请求出错,500~599的状态码指服务端出错(HTTP/1.1向协议中引入了信息性状态码,范围为100~199)
https://www.cnblogs.com/jianying/p/7992622.html
1**(信息类):表示接收到请求并且继续处理
100——客户必须继续发出请求
101——客户要求服务器根据请求转换HTTP协议版本
2**(响应成功):表示动作被成功接收、理解和接受
200——表明该请求被成功地完成,所请求的资源发送回客户端
201——提示知道新文件的URL
202——接受和处理、但处理未完成
203——返回信息不确定或不完整
204——请求收到,但返回信息为空
205——服务器完成了请求,用户代理必须复位当前已经浏览过的文件
206——服务器已经完成了部分用户的GET请求
3**(重定向类):为了完成指定的动作,必须接受进一步处理
300——请求的资源可在多处得到
301——本网页被永久性转移到另一个URL
302——请求的网页被转移到一个新的地址,但客户访问仍继续通过原始URL地址,重定向,新的URL会在response中的Location中返回,浏览器将会使用新的URL发出新的Request。
303——建议客户访问其他URL或访问方式
304——自从上次请求后,请求的网页未修改过,服务器返回此响应时,不会返回网页内容,代表上次的文档已经被缓存了,还可以继续使用
305——请求的资源必须从服务器指定的地址得到
306——前一版本HTTP中使用的代码,现行版本中不再使用
307——申明请求的资源临时性删除
4**(客户端错误类):请求包含错误语法或不能正确执行
400——客户端请求有语法错误,不能被服务器所理解
401——请求未经授权,这个状态代码必须和WWW-Authenticate报头域一起使用
HTTP 401.2 - 未授权:服务器配置问题导致登录失败
HTTP 401.3 - ACL 禁止访问资源
HTTP 401.4 - 未授权:授权被筛选器拒绝
HTTP 401.5 - 未授权:ISAPI 或 CGI 授权失败
402——保留有效ChargeTo头响应
403——禁止访问,服务器收到请求,但是拒绝提供服务
HTTP 403.1 禁止访问:禁止可执行访问
HTTP 403.2 - 禁止访问:禁止读访问
HTTP 403.3 - 禁止访问:禁止写访问
HTTP 403.4 - 禁止访问:要求 SSL
HTTP 403.5 - 禁止访问:要求 SSL 128
HTTP 403.6 - 禁止访问:IP 地址被拒绝
HTTP 403.7 - 禁止访问:要求客户证书
HTTP 403.8 - 禁止访问:禁止站点访问
HTTP 403.9 - 禁止访问:连接的用户过多
HTTP 403.10 - 禁止访问:配置无效
HTTP 403.11 - 禁止访问:密码更改
HTTP 403.12 - 禁止访问:映射器拒绝访问
HTTP 403.13 - 禁止访问:客户证书已被吊销
HTTP 403.15 - 禁止访问:客户访问许可过多
HTTP 403.16 - 禁止访问:客户证书不可信或者无效
HTTP 403.17 - 禁止访问:客户证书已经到期或者尚未生效
404——一个404错误表明可连接服务器,但服务器无法取得所请求的网页,请求资源不存在。eg:输入了错误的URL
405——用户在Request-Line字段定义的方法不允许
406——根据用户发送的Accept拖,请求资源不可访问
407——类似401,用户必须首先在代理服务器上得到授权
408——客户端没有在用户指定的饿时间内完成请求
409——对当前资源状态,请求不能完成
410——服务器上不再有此资源且无进一步的参考地址
411——服务器拒绝用户定义的Content-Length属性请求
412——一个或多个请求头字段在当前请求中错误
413——请求的资源大于服务器允许的大小
414——请求的资源URL长于服务器允许的长度
415——请求资源不支持请求项目格式
416——请求中包含Range请求头字段,在当前请求资源范围内没有range指示值,请求也不包含If-Range请求头字段
417——服务器不满足请求Expect头字段指定的期望值,如果是代理服务器,可能是下一级服务器不能满足请求长。
5**(服务端错误类):服务器不能正确执行一个正确的请求
HTTP 500 - 服务器遇到错误,无法完成请求
HTTP 500.100 - 内部服务器错误 - ASP 错误
HTTP 500-11 服务器关闭
HTTP 500-12 应用程序重新启动
HTTP 500-13 - 服务器太忙
HTTP 500-14 - 应用程序无效
HTTP 500-15 - 不允许请求 global.asa
Error 501 - 未实现
HTTP 502 - 网关错误
HTTP 503:由于超载或停机维护,服务器目前无法使用,一段时间后可能恢复正常
常见的:

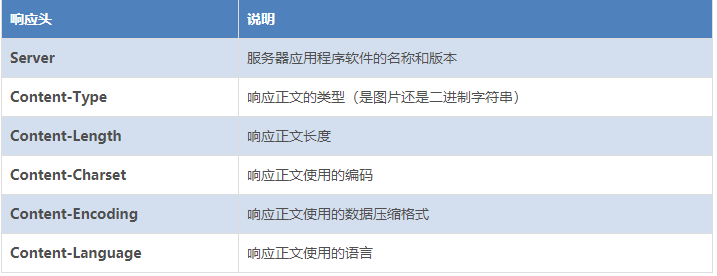
响应头部
与请求头部类似,为响应报文添加了一些附加信息
常见响应头部如下:
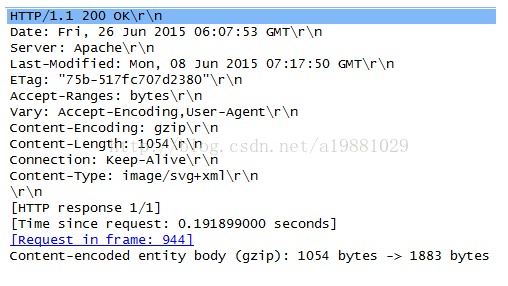
例子:
三,IO模型
web页面,由多个资源组成
打开任何一个网站,都是先主页面,有可能是html,php,jsp,里面有各个资源,为了能够快速的访问站内站外,引用了缓存是浏览器私有缓存,
event支持时间驱动所以这里有IO模型
IO模型
一方提供服务,一方需要调用别人的服务,调用向被调用方请求一个运行一个库调用或者系统调用,被调用方在本地在处理结束后返回,怎么知道什么时候处理完
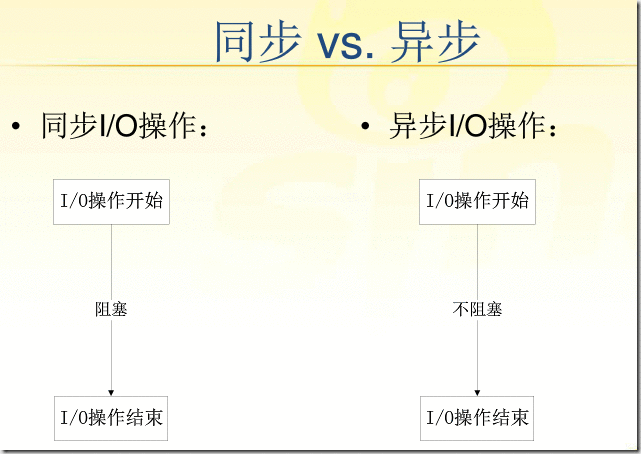
同步和异步:synchronous,asyncronous
同步:调用发出后不会立即返回,但一旦返回,则返回即是最终结果:
异步:调用发出后,被调用方立即返回消息,但返回的并非最终结果,被调用者通过状态、通知机制等来通知调用者,或通过回调函数来处理结果
阻塞和非阻塞
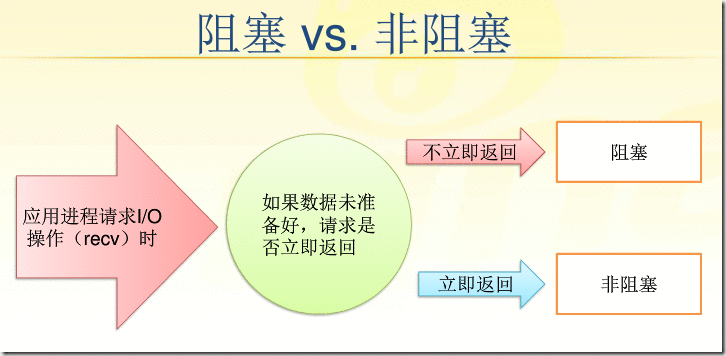
1,阻塞
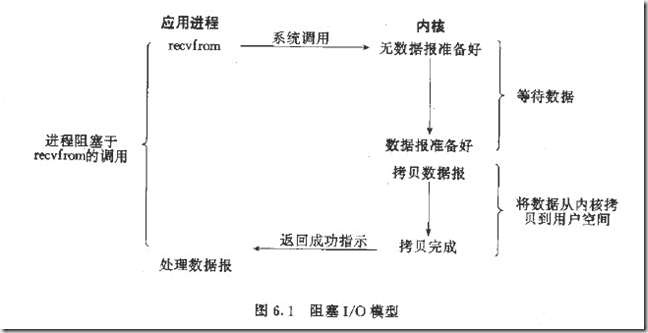
read为例:
(1)进程发起read,进行recvfrom系统调用;
(2)内核开始第一阶段,准备数据(从磁盘拷贝到缓冲区),进程请求的数据并不是一下就能准备好;准备数据是要消耗时间的;
(3)与此同时,进程阻塞(进程是自己选择阻塞与否),等待数据ing;
(4)直到数据从内核拷贝到了用户空间,内核返回结果,进程解除阻塞。
也就是说,内核准备数据和数据从内核拷贝到进程内存地址这两个过程都是阻塞的。
例如:
阻塞I/O, 一天早上你大老早去找报摊老伯买当天报纸,结果告诉你,你来得太早了想要的报纸还没有(也就是进程想要读取的数据被其他占用了,不能马上得到想要的数据),这个时候你就干脆等着,等老板什么时候拿到报纸再给你,老板给你一张小板凳,你什么事情都不做,坐等拿到报纸后就撤退!这里的阻塞分了两部分,一个是你等老板(IO的请求),另一个是老板也在等送报人按照订购清单派发后清点种类和数量(IO操作,内核从磁盘提取数据),你们两个人都在等,所以两个阶段都是阻塞的。
2,非阻塞
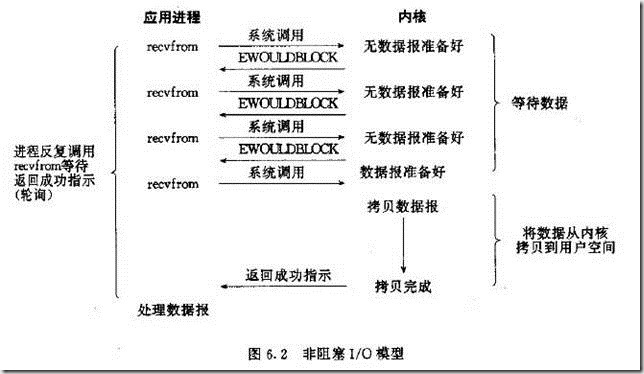

(1)当用户进程发出read操作时,如果kernel中的数据还没有准备好;
(2)那么它并不会阻塞用户进程,而是立刻返回一个error,从用户进程角度讲 ,它发起一个read操作后,并不需要等待,而是马上就得到了一个结果;
(3)用户进程判断结果是一个error时,它就知道数据还没有准备好,于是它可以再次发送read操作。一旦kernel中的数据准备好了,并且又再次收到了用户进程的system call;
(4)那么它马上就将数据拷贝到了用户内存,然后返回。
所以,nonblocking IO的特点是用户进程在内核准备数据的阶段需要不断的主动询问数据好了没有。
例子:
非阻塞I/O, 这种情况是你老板没有小板凳,而你也不想一直等着,等着的时间浪费了还不如干点其他事情。所以你先离开了,然后每隔一段时间就跑回来看看想要的报纸有没有,这种不是一直等待的就是非阻塞,可是对于老板来说他也要等着从送报员手中收到报纸,这过程对于老板也算是阻塞(你最后一次问老板,老板告诉你报纸已经有了,就相当于数据已经复制到内核的缓冲区),而老板虽然告诉你已经有你要报纸,但是老板最后还需要从一堆报纸中找到给你(这是IO的实际操作了,相当于内核从磁盘读取数据,读取完之后再进行的第二个个步骤,从内核复制到进程内存),老板找的过程你就一直等待,所以虽然是非阻塞,但因为第二个步骤你要等待即为同步。
io 复用
也叫多路复用,事件驱动
#######必须是从非阻塞才能到多路复用
I/O多路复用实际上就是用select, poll, epoll监听多个io对象,当io对象有变化(有数据)的时候就通知用户进程。好处就是单个进程可以处理多个socket。
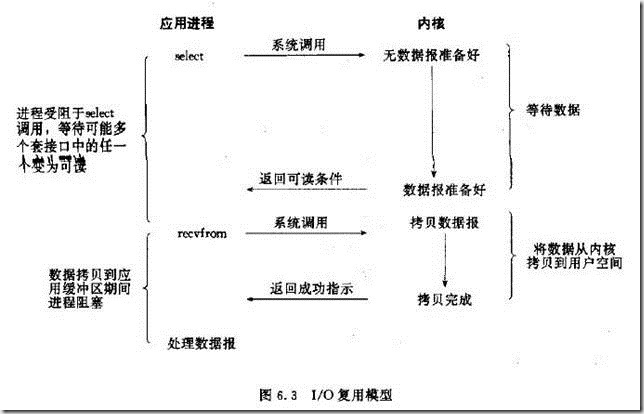
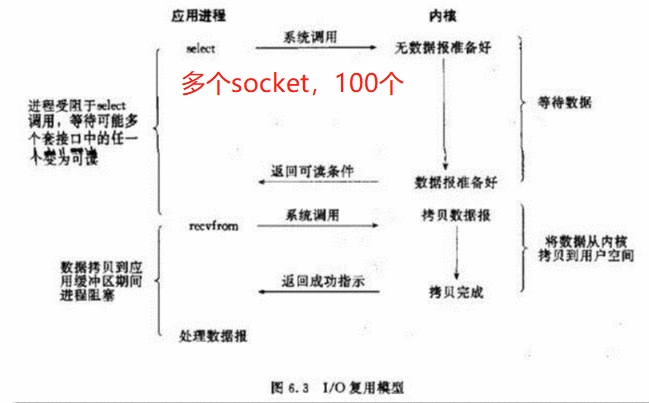
(1)当用户进程调用了select思莱科特,那么整个进程会被block;
(2)而同时,kernel会“监视”所有select负责的socket;
(3)当任何一个socket中的数据准备好了,select就会返回;
(4)这个时候用户进程再调用read操作,将数据从kernel拷贝到用户进程。
例子:
I/O多路复用, 上面第二种方式可以发现有很大缺陷了,你需要不断地去看报纸送到老板手上了没有,一来二去的想想都累,尤其是当你要的多份报纸要在几个地方才能买到(多路复用更适用于多个IO的情景),这样你就需要每个地方反复的去看一遍有没有到货,累成狗了吧。这个时候多路复用的功能就是,你找个人来帮你跑,这个人会定时地将每个报亭的报纸是否有库存记录下来,你要做的事情只需要老老实实待在你和中介的见面点喝茶(阻塞,进程受阻于select调用),一旦发现中介跑回来的就向他询问,当某次得知所有报亭都已经到货,你就可以走一圈买到所有报纸。
异步io
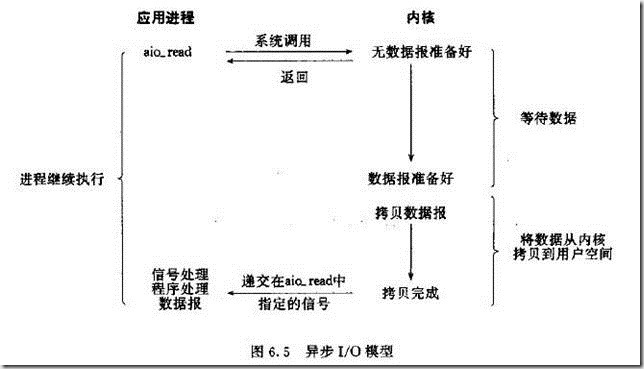
(1)用户进程发起read操作之后,立刻就可以开始去做其它的事。
(2)而另一方面,从kernel的角度,当它受到一个asynchronous read之后,首先它会立刻返回,所以不会对用户进程产生任何block。
(3)然后,kernel会等待数据准备完成,然后将数据拷贝到用户内存,当这一切都完成之后,kernel会给用户进程发送一个signal,告诉它read操作完成了。









 京公网安备 11010802041100号
京公网安备 11010802041100号