目录
基于huffffman树的文件压缩
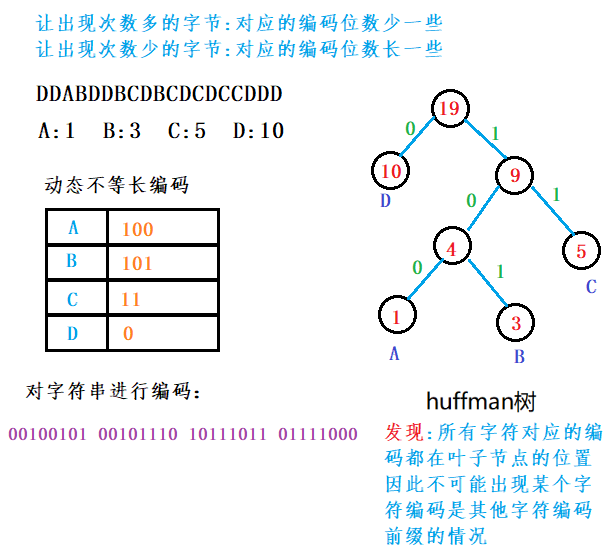
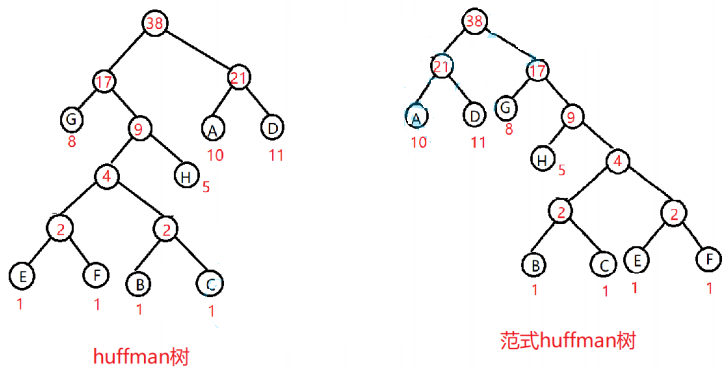
huffffman树
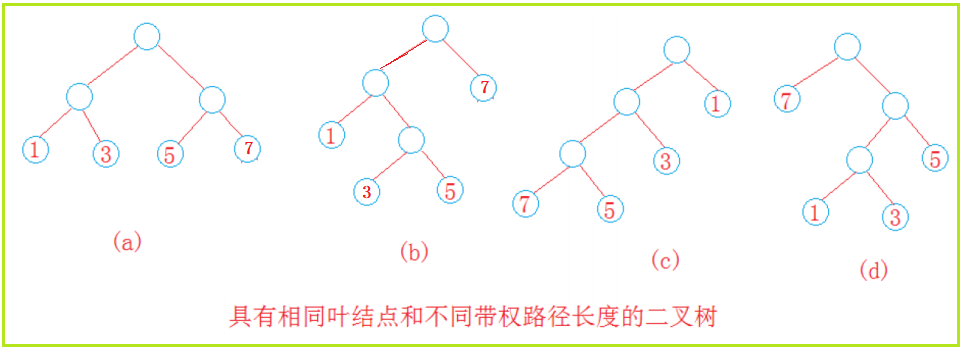
huffffman树构建
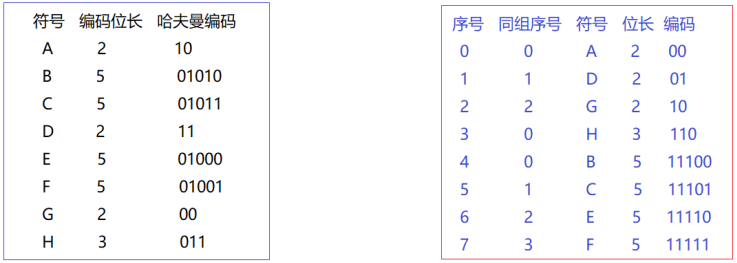
获取huffffman编码
huffman文件压缩格式:
huffman编码压缩过程:
huffman编码解压缩过程:
代码实现:
LZ77
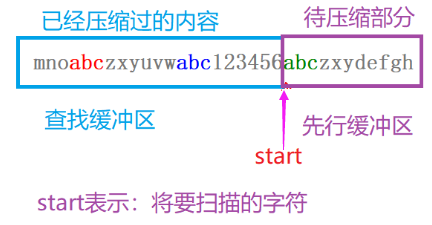
LZ77原理:
代码实现前的一些问题:
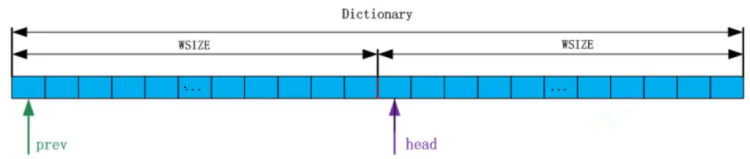
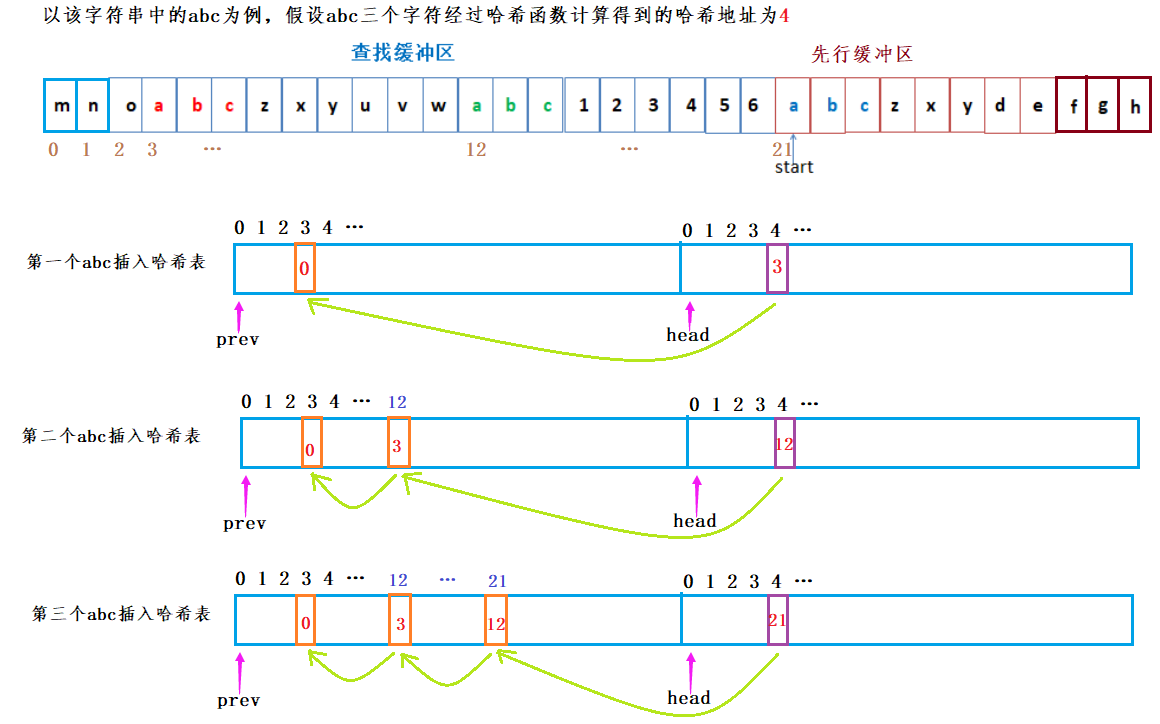
哈希表实现:
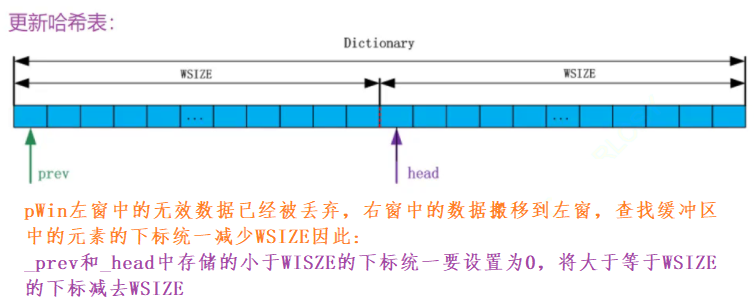
LZ77处理大文件:
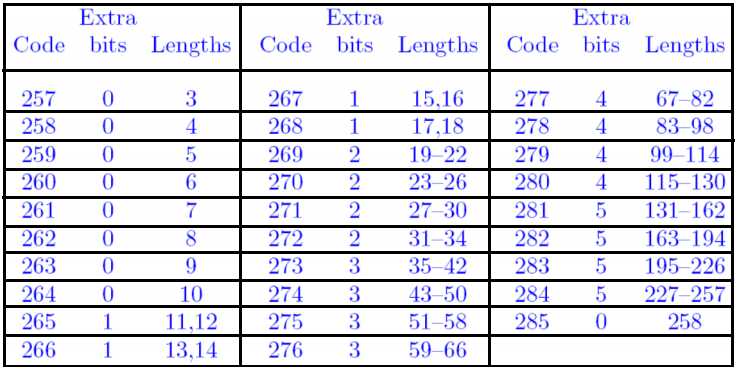
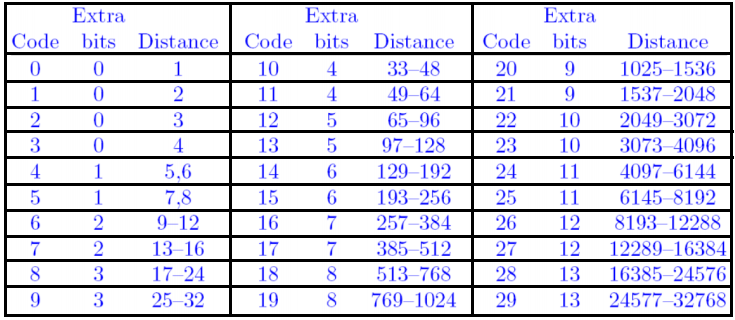
LZ77压缩
压缩格式数据保存
解压缩
huffman压缩之后的结果为什么会变大:
LZ77压缩之后的结果为什么会变大
GZIP: LZ77和Huffman的结合










 京公网安备 11010802041100号
京公网安备 11010802041100号