流数据流经source,再到operator,由于网络延迟等原因,导致乱序的产生(这里的乱序是指事件产生的时间EventTime和到达处理机制进行处理的顺序不一样),特别是使用kafka的话,多个分区的数据source之后无法保证有序。所以在进行window计算的时候,如果有涉及时间的,比如(前一小时的访问量),必须要有个机制来保证操作结果的相对准确性。Flink运用一下几个机制来保证事件事件和操作时间的相对一致。
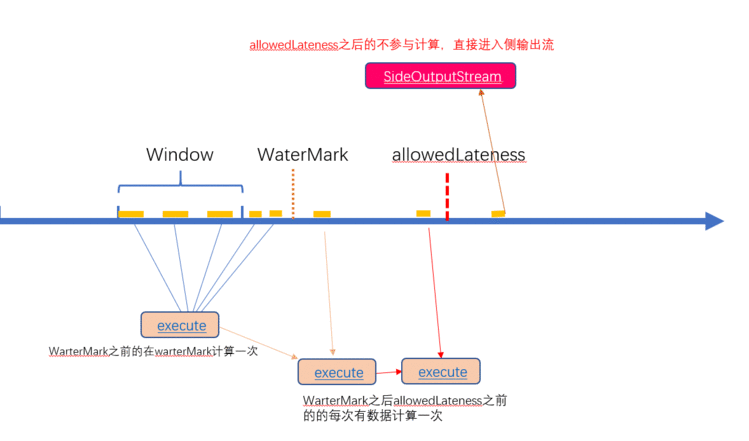
1.warterMark
在不添加EventTime,只有窗口操作的情况下,Flink实时性得到了最大的发挥,但是于此同时,操作结果也非常不准确,只要过来的数据有达到窗口的结束时间window_end_time的,将会马上触发窗口,那么在接收数据是乱序的情况下,将会导致此窗口的数据大部分的丢失
warter是用来定义延迟触发窗口操作的时间的,假设窗口时00:00~00:05,warter为1分钟,那么相当于将接收这个窗口中的数据的时间向后延长了1分钟,自然操作这些数据的时间也会延迟1分钟。这是为了形象的理解,实际上时warterMark倒退了1分钟,等到wartermark的时间真正达到和window_end_time时间相同时,才触发窗口。
2.allowedLateness
在添加warterark之后,保证了绝大多数数据的准确性,但是warterMark的时间也不能设置过长,因为flink框架的特点就是低延迟,设置过高不利于保证实时性。因此,我们一般会将warter设置在一个较小但是又能保证绝大多数数据都会被计算。那么剩下仍旧有少数数据没有在此事件内到达,导致我们没有在warterMark这段时间内接收到,allowedLateness是为了保证warter之后短时间内的数据可以被计算的,在window_end_time+watermark 至window_end_time+watermark+allowedLateness的属于此窗口的数据,只要来一次就会和window中的其它数据被计算一次,这样保证了短期内对计算结果的更新。
3.OutputLateData
window_end_time+watermarkallowedLateness之后的极少量数据,将会被放入OutputLateData进行处理,不会主动并入之前的计算结果进行计算。
如下,是刚才花了很久时间画出来的一张很丑的图。。。。。。。。。。。。。。。








 京公网安备 11010802041100号
京公网安备 11010802041100号