2019独角兽企业重金招聘Python工程师标准>>> 
根据CheckpointingMode的不同,Flink提供了2种不同的检查点模式:
1、Exactly once
2、At least once
- 其中默认的模式是EXACTLY_ONCE。
对应这两种不同的模式,Flink提供了2种不同的实现类:
1、BarrierBuffer类(对应于Exactly Once)
2、BarrierTracker类(对应于At Least Once)
exactly once其核心就是一个input channel收到barrier,立刻阻塞,然后判断是否收到所有input channel的barrier,如果全部收到,则广播出barrier,触发此task的检查点,并对阻塞的channel释放锁。
实际上,为了防止输入流的背压(back-pressuring),BarrierBuffer并不是真正的阻塞这个流,而是将此channel中,barrier之后数据通过一个BufferSpiller来buffer起来,当channel的锁释放后,再从buffer读回这些数据,继续处理。
1、Exactly_once简介
Exactly_once语义是Flink的特性之一,那么Flink到底提供了什么层次的Excactly_once?有人说是是每个算子保证只处理一次,有人说是每条数据保证只处理一次。
Exactly_once是为有状态的计算准备的!
换句话说,没有状态的算子操作(operator),Flink无法也无需保证其只被处理Exactly_once!为什么无需呢?因为即使失败的情况下,无状态的operator(map、filter等)只需要数据重新计算一遍即可。例如:
dataStream.filter(_.isInNYC)
当机器、节点等失败时,只需从最近的一份快照开始,利用可重发的数据源重发一次数据即可,当数据经过filter算子时,全部重新算一次即可,根本不需要区分哪个数据被计算过,哪个数据没有被计算过,因为没有状态的算子只有输入和输出,没有状态可以保存。
2、Flink的恢复机制
Flink的失败恢复依赖于“检查点机制+可部分重发的数据源”。
2.1、检查点机制:检查点定期触发,产生快照,快照中记录了(1)当前检查点开始时数据源(例如Kafka)中消息的offset,(2)记录了所有有状态的operator当前的状态信息(例如sum中的数值)。
2.2、可部分重发的数据源:Flink选择最近完成的检查点K。然后系统重放整个分布式的数据流,然后给予每个operator他们在检查点k快照中的状态。数据源被设置为从位置Sk开始重新读取流。例如在Apache Kafka中,那意味着告诉消费者从偏移量Sk开始重新消费。
3、检查点与保存点
3.1、检查点
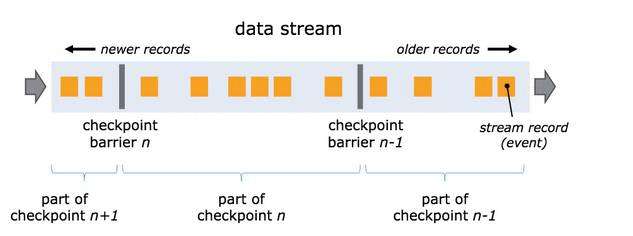
Flink的检查点机制实现了标准的Chandy-Lamport算法,并用来实现分布式快照。在分布式快照当中,有一个核心的元素:Barrier。
屏障作为数据流的一部分随着记录被注入到数据流中。屏障永远不会赶超通常的流记录,它会严格遵循顺序。屏障将数据流中的记录隔离成一系列的记录集合,并将一些集合中的数据加入到当前的快照中,而另一些数据加入到下一个快照中。每一个屏障携带着快照的ID,快照记录着ID并且将其放在快照数据的前面。屏障不会中断流处理,因此非常轻量级。来自不同快照的多个屏障可能同时出现在流中,这意味着多个快照可能并发地发生。
单流的barrier:
多流的barrier:
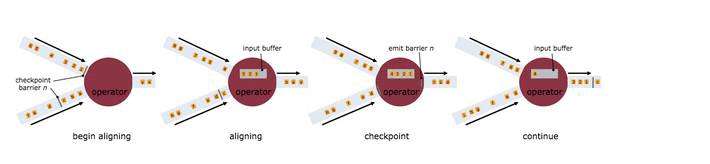
不止一个输入流的的operator需要在快照屏障上对齐(align)输入流。
在stream source中,流屏障被注入到并发数据流中。快照n被注入屏障的点(简称为Sn),是在source stream中的数据已被纳入该快照后的位置。例如,在Apache Kafka中,该位置将会是partition中最后一条记录的offset。这个Sn的位置将被报告给检查点协调器(Flink JobManager)。
屏障接下来会流向下游。当一个中间的operator从所有它的输入流中接收到一个来自快照n的屏障,它自身发射一个针对快照n的屏障到所有它的输出流。一旦一个sink operator(流DAG的终点)从它所有的输入流中接收到屏障n,它将会像检查点协调器应答快照n。在所有的sink应答该快照后,它才被认为是完成了。
程序中如何设置检查点?
val env = StreamExecutionEnvironment.getExecutionEnvironment()// start a checkpoint every 1000 ms
env.enableCheckpointing(1000)// advanced options:// set mode to exactly-once (this is the default)
env.getCheckpointConfig.setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE)// checkpoints have to complete within one minute, or are discarded
env.getCheckpointConfig.setCheckpointTimeout(60000)// allow only one checkpoint to be in progress at the same time
env.getCheckpointConfig.setMaxConcurrentCheckpoints(1)
3.2、保存点
保存点本质上就是一次检查点,但它与检查点的不同在于:
(1)手动触发
(2)不会过期,除非用户明确的处理
先来看一张图:
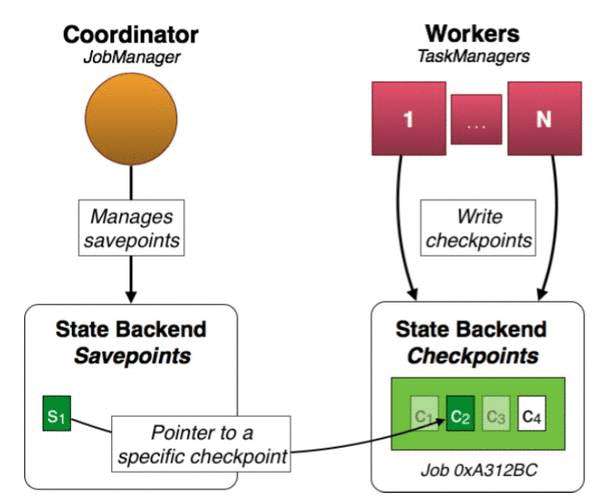
保存点仅仅是一个指向检查点的指针;同时,其默认保存在JobManager的memory中,但为了高可用,建议保存到hdfs上。通入如下参数调整:
savepoints.state.backend: filesystem
savepoints.state.backend.fs.dir: hdfs:///flink/savepoints
保存点在什么时候使用?
(1)应用程序升级
(2)Flink版本升级
(3)系统升级或系统迁移
(4)程序的模拟仿真情况
(5)A/B测试
如何手动触发及恢复保存点?
CLI方式:
触发:
flink savepoint
恢复:
flink run -s
4、状态简介
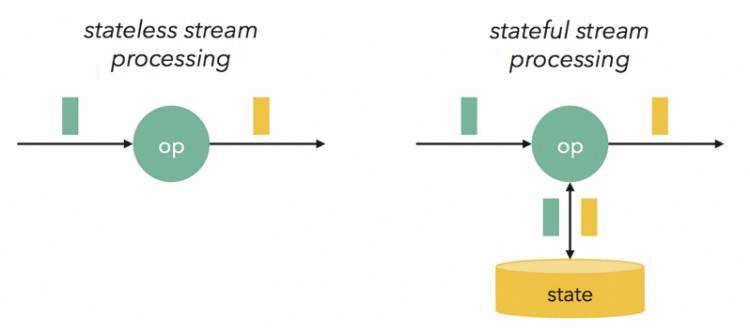
Flink流处理中的算子操作,是可以有状态的,这也是区别于其他流计算引擎的显著标志之一。
Flink提供了Exactly_once特性,是依赖于带有barrier的分布式快照+可部分重发的数据源功能实现的。而分布式快照中,就保存了operator的状态信息。
4.1、如何定义快照?
(1)使用window操作,基于EventTime、ProcessingTime、基于Count的窗口以及自定义的窗口。
(2)使用检查点接口,可以注册任何类型的java/scala对象。
(3)使用key/value状态接口,通过key来分区使用state。
4.2、重点说说如何使用基于key/value状态接口来定义state
既然是基于key/value的状态接口,那么这些状态只能用于keyedStream之上。keyedStream上的operator操作可以包含window或者map等算子操作。
key/value下可用的状态接口:
(1)ValueState : 状态保存的是一个值,可以通过update(T)来更新,T.value()获取。
(2)ListState : 状态保存的是一个列表,通过add(T)添加数据,Iterable.get获取。
(3)ReducingState : 状态保存的是一个经过聚合之后的值的列表,通过add(T)添加数据,通过指定的聚合方法获取。
通过创建一个StateDescriptor,可以得到一个包含特定名称的状态句柄,可以分别创建ValueStateDescriptor、 ListStateDescriptor或ReducingStateDescriptor状态句柄。
注意:状态是通过RuntimeContext来访问的,因此只能在RichFunction中访问状态。这就要求UDF时要继承Rich函数,例如RichMapFunction、RichFlatMapFunction等。
无状态的流与有状态的流的对比:
4.3、状态保存在哪里
状态终端用来对状态进行持久化存储,Flink支持多个状态终端:
(1)MemoryStateBackend
(2)FsStateBackend
(3)RocksDBStateBackend(第三方开发者实现)
五、带状态的operator例子
这里以flink-training上的例子作为样例:
keyBy之后是一个keyedStream,然后进行flatMap操作,转换为dataStream。定义状态就是在flatMap中实现。
.keyBy("rideId")
// compute the average speed of a ride
.flatMap(new SpeedComputer)
继承RichFlatMapFunction而非FlatMapFunction,此例中state是一个基于key/value接口的ValueState方法。而RichFlatMapFunction又继承了AbstractRichFunction,其中要覆写open方法;同时覆写RichFlatMapFunction中的flatMap方法。
class SpeedComputer extends RichFlatMapFunction[TaxiRide, (Long, Float)] {var state: ValueState[TaxiRide] = nulloverride def open(config: Configuration): Unit = {state = getRuntimeContext.getState(new ValueStateDescriptor("ride", classOf[TaxiRide], null))}override def flatMap(ride: TaxiRide, out: Collector[(Long, Float)]): Unit = {if(state.value() == null) {// first ridestate.update(ride)}else {// second rideval startEvent = if (ride.isStart) ride else state.value()val endEvent = if (ride.isStart) state.value() else rideval timeDiff = endEvent.time.getMillis - startEvent.time.getMillisval speed = if (timeDiff != 0) {(endEvent.travelDistance / timeDiff) * 60 * 60 * 1000} else {-1}// emit average speedout.collect( (startEvent.rideId, speed) )// clear state to free memorystate.update(null)}}}
通过这个例子,可以知道如何在operator中实现state。
六、总结
最后说一下我对Flink中有状态的算子在恢复时是如何进行的:
假设场景Job:1个Source(Kafka)+1个不带state的operator+1个带state的operator+1个sink。
如果失败,则Flink选择最近的一份检查点开始恢复,检查点中记录了这次检查点开始时数据源(kafka)中对应的topic的offset,从offset开始重新发送数据,当数据流到1个不带state的算子时,数据全部应用在这个算子上;接着数据流向1个带有state的算子,由于快照中记录着这个state的状态的值,因此,数据重新计算时只从记录着状态的值的地方开始计算,而不会从头开始计算,例如key0=2,那么只从key0=2开始计算。随后进行sink。由于失败时可能有些数据已经sink了,那么根据幂等性原则,即使中间输出的结果存在异常,但是重发之后再次sink是正确的,最终的结果还是正确的。
由于sink一般都是外围系统,因此sink的设计一般都没有状态,但是如果保证幂等性,最终的结果也没问题。









 京公网安备 11010802041100号
京公网安备 11010802041100号