作者:chucai | 来源:互联网 | 2023-06-11 11:55
一.简介为了在Scala和JavaAPI之间保持相当程度的一致性,用于批处理和流传输的标准API省略了一些允许在Scala中进行高水平表达的功能。如果想享受完整的S
一.简介 为了在Scala和Java API之间保持相当程度的一致性,用于批处理和流传输的标准API省略了一些允许在Scala中进行高水平表达的功能。
import org. apache. flink. api. scala. extensions. _
2.DataStream API
import org. apache. flink. streaming. api. scala. extensions. _
另外,也可以根据需要导入单个扩展。
二.扩展模式匹配 通常,DataSet和DataStream API都不接受匿名模式匹配函数来匹配元组,案例类或集合,如下所示:
val data: DataSet[ ( Int, String, Double) ] = . map { case ( id, name, temperature) = > }
此扩展在DataSet和DataStream Scala API中引入了新方法,这些新方法在扩展API中具有一对一的对应关系。这些扩展方法支持匿名模式匹配功能。
import org. apache. flink. api. scala. extensions. acceptPartialFunctions
2.DataStream API
import org. apache. flink. streaming. api. scala. extensions. acceptPartialFunctions
三.代码案例 以下代码片段显示了如何一起使用这些扩展方法(与DataSet API一起使用)的示例:
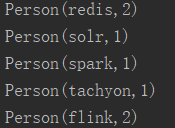
package cn. extensionsimport org. apache. flink. api. scala. _import org. apache. flink. api. scala. ExecutionEnvironmentcase class Person ( x: String, y: Int) { def main ( args: Array[ String] ) : Unit = { val env = ExecutionEnvironment. getExecutionEnvironmentval text = "Apache Flink apache spark apache solr hbase hive flink kafka redis tachyon redis" val persons = text. toLowerCase. split ( " " ) . map ( row = > Person ( row, 1 ) ) import org. apache. flink. api. scala. extensions. _val ds = env. fromCollection ( persons) val result = ds. filterWith { case Person ( x, y) = > y > 0 } . groupingBy{ case Person ( x, _) = > x} . sum ( "y" ) result. first ( 5 ) . print ( ) } }
异常报错信息:
Exception in thread "main" java. lang. UnsupportedOperationException: Aggregate does not support grouping with KeySelector functions, yet. at org. apache. flink. api. scala. operators. ScalaAggregateOperator. translateToDataFlow ( ScalaAggregateOperator. java: 220 ) at org. apache. flink. api. scala. operators. ScalaAggregateOperator. translateToDataFlow ( ScalaAggregateOperator. java: 55 ) at org. apache. flink. api. java. operators. OperatorTranslation. translateSingleInputOperator ( OperatorTranslation. java: 148 ) at org. apache. flink. api. java. operators. OperatorTranslation. translate ( OperatorTranslation. java: 102 ) at org. apache. flink. api. java. operators. OperatorTranslation. translateSingleInputOperator ( OperatorTranslation. java: 146 ) at org. apache. flink. api. java. operators. OperatorTranslation. translate ( OperatorTranslation. java: 102 ) at org. apache. flink. api. java. operators. OperatorTranslation. translate ( OperatorTranslation. java: 63 ) at org. apache. flink. api. java. operators. OperatorTranslation. translateToPlan ( OperatorTranslation. java: 52 ) at org. apache. flink. api. java. ExecutionEnvironment. createProgramPlan ( ExecutionEnvironment. java: 955 ) at org. apache. flink. api. java. ExecutionEnvironment. createProgramPlan ( ExecutionEnvironment. java: 922 ) at org. apache. flink. api. java. LocalEnvironment. execute ( LocalEnvironment. java: 85 ) at org. apache. flink. api. java. ExecutionEnvironment. execute ( ExecutionEnvironment. java: 816 ) at org. apache. flink. api. java. DataSet. collect ( DataSet. java: 413 ) at org. apache. flink. api. java. DataSet. print ( DataSet. java: 1652 ) at org. apache. flink. api. scala. DataSet. print ( DataSet. scala: 1726 ) at cn. extensions. Match$. main ( Match. scala: 29 ) at cn. extensions. Match. main ( Match. scala) at sun. reflect. NativeMethodAccessorImpl. invoke0 ( Native Method) at sun. reflect. NativeMethodAccessorImpl. invoke ( NativeMethodAccessorImpl. java: 62 ) at sun. reflect. DelegatingMethodAccessorImpl. invoke ( DelegatingMethodAccessorImpl. java: 43 ) at java. lang. reflect. Method. invoke ( Method. java: 497 ) at com. intellij. rt. execution. application. AppMain. main ( AppMain. java: 144 )
可知是使用groupingWith导致的,意思是不支持使用该扩展API,换回原来的groupWith即可:











 京公网安备 11010802041100号
京公网安备 11010802041100号