最近想起刚做实时数仓时候的项目架构,如下:从架构图可以看到,数仓是基于Flink和Kafka的实时能力做的,同时每层的结果会存一份到HBase(公司特点方便查数)那时候就想弄个支持
最近想起刚做实时数仓时候的项目架构,如下:
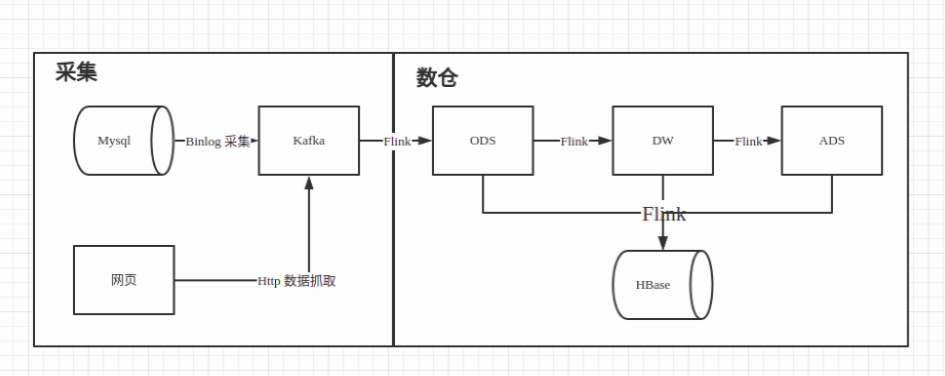
从架构图可以看到,数仓是基于 Flink 和 Kafka 的实时能力做的,同时每层的结果会存一份到 HBase(公司特点方便查数)
那时候就想弄个支持多路输出的 Table Sink,一直没有动手。现在先来个简单的 SocketTableSink 练练手
之前搞 Table Source 的时候,已经实现了 Socke Table Source(从官网抄的),这次刚好一起凑成一组 Table Source/Sink
先来个架构图:
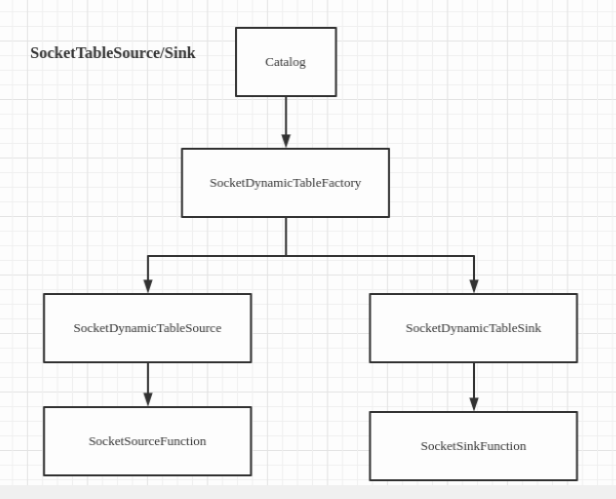
类图:
SocketDynamicTableFactory 实现 Flink 的 DynamicTableSourceFactory, DynamicTableSinkFactory
SocketDynamicTableSource 实现 Flink 的 ScanTableSource, ScanTableSource 实现了 DynamicTableSource
SocketDynamicTableSink 实现 Flink 的 DynamicTableSink
SocketSourceFunction 继承 Flink 的 RichSourceFunction
SocketSinkFunction 继承 RichSinkFunction
代码
SocketDynamicTableFactory
定义了connector 标识,和 Socket table source/sink 必选、可选的参数,如: hostname、port 等
@Override
public String factoryIdentifier() {
return "socket"; // used for matching to `cOnnector= '...'`
}
// define all options statically
public static final ConfigOption HOSTNAME = ConfigOptions.key("hostname")
.stringType()
.noDefaultValue();
public static final ConfigOption PORT = ConfigOptions.key("port")
.intType()
.noDefaultValue();
实现了 createDynamicTableSource、createDynamicTableSink 方法,解析 Catalog 中的参数,根据 format 类型选择合适的序列化器或反序列化器,最后创建 SocketDynamicTableSource、SocketDynamicTableSink
/**
* create socket table source
* @param context
* @return
*/
@Override
public DynamicTableSource createDynamicTableSource(Context context) {
// either implement your custom validation logic here ...
// or use the provided helper utility
final FactoryUtil.TableFactoryHelper helper = FactoryUtil.createTableFactoryHelper(this, context);
// discover a suitable decoding format
final DecodingFormat> decodingFormat = helper.discoverDecodingFormat(
DeserializationFormatFactory.class,
FactoryUtil.FORMAT);
// validate all options
helper.validate();
// get the validated options
final ReadableConfig optiOns= helper.getOptions();
final String hostname = options.get(HOSTNAME);
final int port = options.get(MAX_RETRY);
final byte byteDelimiter = (byte) (int) options.get(BYTE_DELIMITER);
// derive the produced data type (excluding computed columns) from the catalog table
final DataType producedDataType =
context.getCatalogTable().getResolvedSchema().toPhysicalRowDataType();
// create and return dynamic table source
return new SocketDynamicTableSource(hostname, port, byteDelimiter, decodingFormat, producedDataType);
}
/**
* create socket table sink
* @param context
* @return
*/
@Override
public DynamicTableSink createDynamicTableSink(Context context) {
// either implement your custom validation logic here ...
// or use the provided helper utility
final FactoryUtil.TableFactoryHelper helper = FactoryUtil.createTableFactoryHelper(this, context);
final EncodingFormat> encodingFormat = helper.discoverEncodingFormat(
SerializationFormatFactory.class,
FactoryUtil.FORMAT);
// validate all options
helper.validate();
// get the validated options
final ReadableConfig optiOns= helper.getOptions();
final String hostname = options.get(HOSTNAME);
final int port = options.get(PORT);
final int maxRetry = options.get(MAX_RETRY);
final long retryInterval = options.get(RETRY_INTERVAL) * 1000;
final byte byteDelimiter = (byte) (int) options.get(BYTE_DELIMITER);
Preconditions.checkState(maxRetry > 0, "max retry time max greater than 0, current : ", maxRetry);
// derive the produced data type (excluding computed columns) from the catalog table
final DataType producedDataType =
context.getCatalogTable().getResolvedSchema().toPhysicalRowDataType();
return new SocketDynamicTableSink(hostname, port, maxRetry, retryInterval, encodingFormat, byteDelimiter, producedDataType);
}
SocketDynamicTableSource
用 DecodingFormat 创建对应的反序列化器,创建 Source Function
@Override
public ScanRuntimeProvider getScanRuntimeProvider(ScanContext runtimeProviderContext) {
// create runtime classes that are shipped to the cluster
// create deserializer
final DeserializationSchema deserializer = decodingFormat.createRuntimeDecoder(
runtimeProviderContext,
producedDataType);
final SourceFunction sourceFunction = new SocketSourceFunction(hostname, port, byteDelimiter, deserializer);
return SourceFunctionProvider.of(sourceFunction, false);
}
SocketSourceFunction
从 socket 中获取输入流,反序列化数据,输出到下游
@Override
public void run(SourceContext ctx) throws Exception {
while (isRunning) {
// open and consume from socket
try (final Socket socket = new Socket()) {
currentSocket = socket;
socket.connect(new InetSocketAddress(hostname, port), 0);
try (InputStream stream = socket.getInputStream()) {
ByteArrayOutputStream buffer = new ByteArrayOutputStream();
int b;
while ((b = stream.read()) >= 0) {
// buffer until delimiter
if (b != byteDelimiter) {
buffer.write(b);
}
// decode and emit record
else {
ctx.collect(deserializer.deserialize(buffer.toByteArray()));
buffer.reset();
}
}
}
} catch (Throwable t) {
t.printStackTrace(); // print and continue
}
Thread.sleep(1000);
}
}
SocketDynamicTableSink
和 SocketDynamicTableSource 类似,用 EncodingFormat 创建序列化器,创建 SocketSinkFunction
@Override
public SinkRuntimeProvider getSinkRuntimeProvider(Context context) {
final SerializationSchema serializer = encodingFormat.createRuntimeEncoder(context, producedDataType);
SocketSinkFunction sink = new SocketSinkFunction(hostname, port, serializer, maxRetry, retryInterval);
return SinkFunctionProvider.of(sink);
}
SocketSinkFunction
将数据序列化后,写入到 socket 的输出流
@Override
public void invoke(RowData element, Context context) throws Exception {
int retryTime = 0;
byte[] message = serializer.serialize(element);
while (retryTime <= maxRetry) {
try {
os.write(message);
os.flush();
return;
} catch (Exception e) {
Thread.sleep(retryInterval);
++retryTime;
reconnect();
// LOG.warn("send data error retry: {}", retryTime);
}
}
LOG.warn("send error after retry {} times, ignore it: {}", maxRetry, new String(message));
}
测试
SQL 读 socket 写 socket:
-- kafka source
drop table if exists user_log;
CREATE TABLE user_log (
user_id VARCHAR
,item_id VARCHAR
,category_id VARCHAR
,behavior VARCHAR
,ts TIMESTAMP(3)
,WATERMARK FOR ts AS ts - INTERVAL '5' SECOND
) WITH (
'connector' = 'socket'
,'hostname' = 'thinkpad'
,'port' = '12345'
,'format' = 'json'
-- ,'format' = 'csv'
);
-- set table.sql-dialect=hive;
-- kafka sink
drop table if exists socket_sink;
CREATE TABLE socket_sink (
user_id STRING
,item_id STRING
,category_id STRING
,behavior STRING
,ts timestamp(3)
) WITH (
'connector' = 'socket'
,'hostname' = 'localhost'
,'max.retry' = '2'
-- ,'retry.interval' = '2'
,'port' = '12346'
,'format' = 'csv'
);
-- streaming sql, insert into mysql table
insert into socket_sink
SELECT user_id, item_id, category_id, behavior, ts
FROM user_log;
先打开两个端口:
nc -lk localhost 12345
nc -lk localhost 12346
输入数据:

输出:

- 注: 要先打开输入、输出的端口,不然连不上端口,source 和sink 都要报错
完整示例参考: github sqlSubmit
欢迎关注Flink菜鸟公众号,会不定期更新Flink(开发技术)相关的推文










 京公网安备 11010802041100号
京公网安备 11010802041100号