流处理应用程序通常是有状态的,“记住”已处理事件的信息,并使用它来影响进一步的事件处理。在Flink中,记忆的信息(即状态)被本地存储在配置的状态后端中。为了防止发生故障时丢失数据,状态后端会定期将其内容快照保存到预先配置的持久性存储中。该RocksDB[1]状态后端(即RocksDBStateBackend)是Flink中的三个内置状态后端之一。这篇博客文章将指导您了解使用RocksDB管理应用程序状态的好处,解释何时以及如何使用它,以及清除一些常见的误解。话虽如此,这不是一篇说明RocksDB如何深入工作或如何进行高级故障排除和性能调整的博客文章;如果您需要任何有关这些主题的帮助,可以联系Flink用户邮件列表[2]。
为了更好地了解Flink中的状态和状态后端,区分运行中状态和状态快照非常重要。运行中状态(也称为工作状态)是Flink作业正在处理的状态。它始终存储在本地内存中(有可能溢出到磁盘中),并且在作业失败而不会影响作业可恢复性的情况下可能会丢失。状态快照(即检查点[3]和保存点[4])存储在远程持久性存储中,用于在作业失败的情况下还原本地状态。选择适合生产部署的状态后端取决于系统的可伸缩性,吞吐量和延迟要求。
将RocksDB视为需要在群集上运行并由专门的管理员进行管理的分布式数据库是一个常见的误解。RocksDB是用于快速存储的可嵌入持久化的kv存储。它通过Java本机接口(JNI)与Flink进行交互。下图显示了RocksDB在Flink集群节点中的适合位置。以下各节说明了详细信息。
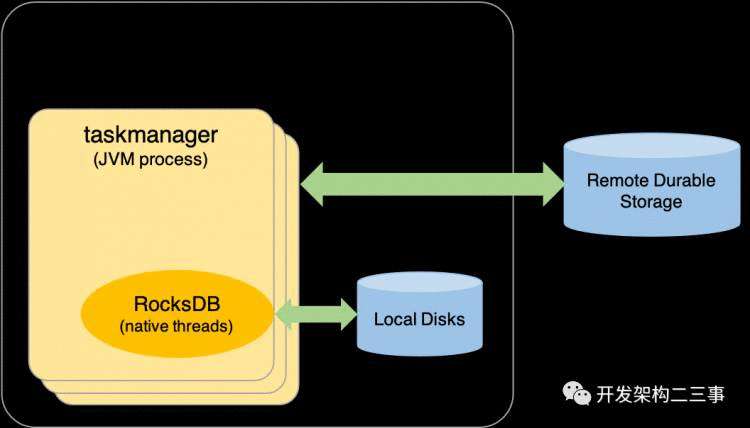
将RocksDB用作状态后端所需的一切都捆绑在Apache Flink发行版中,包括本机共享库:
$ jar -tvf lib/flink-dist_2.12-1.12.0.jar| grep librocksdbjni-linux648695334 Wed Nov 27 02:27:06 CET 2019 librocksdbjni-linux64.so
在运行时,RocksDB嵌入在TaskManager进程中。它在本机线程中运行,并与本地文件一起使用。例如,如果您有一个配置为在Flink集群中运行的RocksDBStateBackend的作业,您将看到类似于以下内容,其中32513是TaskManager进程ID。
$ ps -T -p 32513 | grep -i rocksdb32513 32633 ? 00:00:00 rocksdb:low032513 32634 ? 00:00:00 rocksdb:high0
注意: 该命令仅适用于Linux。对于其他操作系统,请参阅其相关文档。
除了RocksDBStateBackend,Flink还具有其他两个内置状态后端:MemoryStateBackend和FsStateBackend。它们都基于堆,因为运行中状态存储在JVM堆中。目前,让我们忽略MemoryStateBackend,因为它仅用于本地开发和调试,而不适合用于生产。
使用RocksDBStateBackend,运行中状态首先被写入堆外/本机内存,然后在达到配置的阈值时刷新到本地磁盘。这意味着RocksDBStateBackend可以支持大于已配置总堆容量的状态。您可以在RocksDBStateBackend中存储的状态量仅受整个群集中可用磁盘空间量的限制。另外,由于RocksDBStateBackend不使用JVM堆来存储运行中的状态,因此不受JVM垃圾收集的影响,因此带来的延迟是可预测。
除了完整的独立状态快照之外,RocksDBStateBackend还支持增量检查点[5]作为性能调整选项。增量检查点仅存储自最近完成的检查点以来发生的更改。与执行完整快照相比,这大大减少了检查点时间。RocksDBStateBackend是当前唯一支持增量检查点的状态后端。
在以下情况下,RocksDB是一个不错的选择:
•您的工作状态大于本地内存所能容纳的状态(例如,长窗口,大keyed state[6]);•您正在研究增量检查点,以减少检查点时间。•您希望具有可预测的延迟,而不受JVM Garbage Collection的影响。
否则,如果您的应用程序状态很小或要求非常低的延迟,则应考虑FsStateBackend。根据经验,RocksDBStateBackend比基于堆的状态后端要慢几倍,因为它将键/值对存储为序列化字节。这意味着任何状态访问(读/写)都需要经过JNI边界的反序列化处理,这比直接处理堆上的状态表示要昂贵。有利的是,对于相同数量的状态,与相应的堆上表示相比,它具有较低的内存占用量。
RocksDB完全嵌入TaskManager进程中,并由TaskManager进程完全管理。RocksDBStateBackend可以在集群级别配置为整个集群的默认值,也可以在作业级别配置为单个作业。作业级别配置优先于集群级别配置。
在中添加以下配置conf/flink-conf.yaml
[7]:
state.backend: rocksdbstate.backend.incremental: truestate.checkpoints.dir: hdfs:///flink-checkpoints # location to store checkpoints
创建StreamExecutionEnvironment之后,将以下内容添加到作业的代码中:
# 'env' is the created StreamExecutionEnvironment# 'true' is to enable incremental checkpointingenv.setStateBackend(new RocksDBStateBackend("hdfs:///fink-checkpoints", true));
注意: 除了HDFS,如果在FLINK_HOME / plugins[8]下添加了相应的依赖项,则还可以使用其他本地或基于云的对象存储。
我们希望本概述有助于您更好地了解RocksDB在Flink中的角色以及如何通过RocksDBStateBackend成功运行作业。为了解决这个问题,我们将探索一些最佳实践和一些参考点,以进行进一步的故障排除和性能调整。
如前所述,RocksDBStateBackend中的运行中状态会溢出到磁盘上的文件中。这些文件位于Flink配置指定的目录下state.backend.rocksdb.localdir
[9]。由于磁盘性能直接影响RocksDB的性能,因此建议将该目录放置在本地磁盘上。不建议将其配置到基于远程网络的位置(例如NFS或HDFS),因为写入远程磁盘通常较慢。此外,运行中的状态也不要求高可用性。如果需要高磁盘吞吐量,则首选本地SSD磁盘。
状态快照将持久保存到远程持久性存储中。在状态快照期间,TaskManager会为运行中的状态拍摄快照并远程存储。将状态快照传输到远程存储完全由TaskManager本身进行处理,而无需状态后端的参与。因此,state.checkpoints.dir
[10]或者您在代码中为特定作业设置的参数可以位于不同的位置,例如本地HDFS[11]群集或基于云的对象存储,例如Amazon S3[12],Azure Blob存储[13],Google Cloud Storage[14],阿里巴巴OSS[15]等。
要检查RocksDB在生产中的行为,您应该查找名为LOG的RocksDB日志文件。默认情况下,此日志文件与数据文件位于同一目录,即Flink配置指定的目录state.backend.rocksdb.localdir
[16]。启用后,RocksDB统计信息[17]也会记录在那里,以帮助诊断潜在的问题。欲了解更多信息,请RocksDB故障排除手册[18]中RocksDB wiki介绍[19]。如果您对一段时间以来的RocksDB行为趋势感兴趣,可以考虑为Flink作业启用RocksDB本机指标[20]。
注意: 从Flink 1.10开始,通过将日志级别设置为HEADER[21],有效地禁用了RocksDB日志记录。要启用它,请查看如何获取RocksDB的LOG文件以进行高级故障排除[22]。
警告 在Flink中启用RocksDB的本机指标可能会对您的工作产生负面的性能影响。
从Flink 1.10开始,Flink默认将RocksDB的内存分配配置为每个任务slot的托管内存量。改善与内存相关的性能问题的主要机制是通过Flink配置 taskmanager.memory.managed.size
[23] 或者 taskmanager.memory.managed.fraction
[24]增加Flink的托管内存[25]。要进行更细粒度的控制,您首先应通过设置state.backend.rocksdb.memory.managed
[26] 为 false
来禁用自动内存管理,然后从以下Flink配置开始:state.backend.rocksdb.block.cache-size
[27] (对应于RocksDB中的block_cache_size), state.backend.rocksdb.writebuffer.size
[28] (对应于RocksDB中的write_buffer_size), and state.backend.rocksdb.writebuffer.count
[29] (对应于RocksDB中的max_write_buffer_number)。有关更多详细信息,请查看此博客文章[30],了解如何在Flink中管理RocksDB内存大小以及RocksDB内存使用情况[31]Wiki页面。
在RocksDB中写入或覆盖数据时,RocksDB线程在后台管理从内存到本地磁盘的刷新和数据压缩。在具有许多CPU内核的计算机上,应通过设置Flink配置参数state.backend.rocksdb.thread.num
[32](对应于RocksDB中的max_background_jobs)来增加后台刷新和压缩的并行度。对于生产设置,默认配置通常太小。如果您需要经常从RocksDB中读取数据,则应考虑启用Bloom过滤器[33]。
对于其他RocksDBStateBackend配置,请查看Advanced RocksDB状态后端选项[34]上的Flink文档。为了进一步调优,检查RocksDB调优指南[35]中RocksDB wiki[36]。
该RocksDB[37]状态后端(即RocksDBStateBackend)是绑定在Flink中的三个状态后端之一,和配置流媒体应用时,可以成为一个强大的选择。它允许可伸缩的应用程序维护最多TB级别的状态,并提供exactly-once的处理保证。如果Flink作业的状态太大而无法容纳在JVM堆上,则您对增量检查点感兴趣,或者希望具有可预测的延迟,则应使用RocksDBStateBackend。由于RocksDB作为本地线程嵌入到TaskManager进程中,并且可以与本地磁盘上的文件一起使用,因此可立即支持RocksDBStateBackend,而无需进一步设置和管理任何外部系统或进程。
本文译自flink技术社区博客[38]。
[1]
RocksDB: https://rocksdb.org/[2]
Flink用户邮件列表: https://flink.apache.org/community.html#mailing-lists[3]
检查点: https://ci.apache.org/projects/flink/flink-docs-stable/ops/state/checkpoints.html[4]
保存点: https://ci.apache.org/projects/flink/flink-docs-stable/ops/state/savepoints.html#what-is-a-savepoint-how-is-a-savepoint-different-from-a-checkpoint[5]
增量检查点: https://ci.apache.org/projects/flink/flink-docs-stable/ops/state/large_state_tuning.html#incremental-checkpoints[6]
keyed state: https://ci.apache.org/projects/flink/flink-docs-stable/dev/stream/state/state.html[7]
conf/flink-conf.yaml
: https://ci.apache.org/projects/flink/flink-docs-stable/deployment/config.html[8]
FLINK_HOME / plugins: https://ci.apache.org/projects/flink/flink-docs-stable/deployment/filesystems/plugins.html[9]
state.backend.rocksdb.localdir
: https://ci.apache.org/projects/flink/flink-docs-stable/deployment/config.html#state-backend-rocksdb-localdir[10]
state.checkpoints.dir
: https://ci.apache.org/projects/flink/flink-docs-stable/deployment/config.html#state-checkpoints-dir[11]
HDFS: https://hadoop.apache.org/docs/current/hadoop-project-dist/hadoop-hdfs/HdfsDesign.html[12]
Amazon S3: https://aws.amazon.com/s3/[13]
Azure Blob存储: https://azure.microsoft.com/en-us/services/storage/blobs/[14]
Google Cloud Storage: https://cloud.google.com/storage[15]
阿里巴巴OSS: https://www.alibabacloud.com/product/oss[16]
state.backend.rocksdb.localdir
: https://ci.apache.org/projects/flink/flink-docs-stable/deployment/config.html#state-backend-rocksdb-localdir[17]
RocksDB统计信息: https://github.com/facebook/rocksdb/wiki/RocksDB-Tuning-Guide#rocksdb-statistics[18]
RocksDB故障排除手册: https://github.com/facebook/rocksdb/wiki/RocksDB-Troubleshooting-Guide[19]
RocksDB wiki介绍: https://github.com/facebook/rocksdb/wiki[20]
RocksDB本机指标: https://ci.apache.org/projects/flink/flink-docs-stable/deployment/config.html#rocksdb-native-metrics[21]
将日志级别设置为HEADER: https://github.com/apache/flink/blob/master/flink-state-backends/flink-statebackend-rocksdb/src/main/java/org/apache/flink/contrib/streaming/state/PredefinedOptions.java#L64[22]
如何获取RocksDB的LOG文件以进行高级故障排除: https://ververica.zendesk.com/hc/en-us/articles/360015933320-How-to-get-RocksDB-s-LOG-file-back-for-advanced-troubleshooting[23]
taskmanager.memory.managed.size
: https://ci.apache.org/projects/flink/flink-docs-stable/deployment/config.html#taskmanager-memory-managed-size[24]
taskmanager.memory.managed.fraction
: https://ci.apache.org/projects/flink/flink-docs-stable/deployment/config.html#taskmanager-memory-managed-fraction[25]
托管内存: https://ci.apache.org/projects/flink/flink-docs-stable/deployment/memory/mem_setup_tm.html#managed-memory[26]
state.backend.rocksdb.memory.managed
: https://ci.apache.org/projects/flink/flink-docs-stable/deployment/config.html#state-backend-rocksdb-memory-managed[27]
state.backend.rocksdb.block.cache-size
: https://ci.apache.org/projects/flink/flink-docs-stable/deployment/config.html#state-backend-rocksdb-block-cache-size[28]
state.backend.rocksdb.writebuffer.size
: https://ci.apache.org/projects/flink/flink-docs-stable/deployment/config.html#state-backend-rocksdb-writebuffer-size[29]
state.backend.rocksdb.writebuffer.count
: https://ci.apache.org/projects/flink/flink-docs-stable/deployment/config.html#state-backend-rocksdb-writebuffer-count[30]
此博客文章: https://www.ververica.com/blog/manage-rocksdb-memory-size-apache-flink[31]
RocksDB内存使用情况: https://github.com/facebook/rocksdb/wiki/Memory-usage-in-RocksDB[32]
state.backend.rocksdb.thread.num
: https://ci.apache.org/projects/flink/flink-docs-stable/deployment/config.html#state-backend-rocksdb-thread-num[33]
Bloom过滤器: https://github.com/facebook/rocksdb/wiki/RocksDB-Tuning-Guide#bloom-filters[34]
Advanced RocksDB状态后端选项: https://ci.apache.org/projects/flink/flink-docs-stable/deployment/config.html#advanced-rocksdb-state-backends-options[35]
RocksDB调优指南: https://github.com/facebook/rocksdb/wiki/RocksDB-Tuning-Guide[36]
RocksDB wiki: https://github.com/facebook/rocksdb/wiki[37]
RocksDB: https://rocksdb.org/[38]
博客: https://flink.apache.org/2021/01/18/rocksdb.html



 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有