作者:女孩明天_会更好 | 来源:互联网 | 2023-06-28 10:47
一、前期准备
1.1下载
点击下面的网址进行下载:
Apache Flink: Downloads
注:新版本需要自己下载相应的shaded打包。如:flink-shaded-hadoop2-uber-1.3.3.jar

测试用,我使用的是1.3.3,大家可以使用高一点的版本。
1.2环境准备
1.2.1安装部署了Hadoop HA和zookeeper;
没有的可以参考:
Hadoop HA环境部署_一个人的牛牛的博客-CSDN博客
zookeeper单机和集群(全分布)的安装过程_一个人的牛牛的博客-CSDN博客
1.2.2安装jdk1.8以上;
没有的可以参考:
Linux系统CentOS7安装jdk_一个人的牛牛的博客-CSDN博客
1.2.3集群配置了免密登录;
没有的可以参考:
Linux配置免密登录单机和全分布_一个人的牛牛的博客-CSDN博客
1.2.4做了ip地址映射
1.3机器准备
| 主节点 | 从节点 |
| hadoop01 | hadoop02 |
| hadoop02 | hadoop03 |
二、安装部署
2.1上传安装包
2.2解压
tar -zvxf flink-1.3.3-bin-hadoop27-scala_2.11.tgz /training/
2.3配置环境变量
vi ~/.bash_profile
添加以下内容并改成自己的路径
#flink
export FLINK_HOME=/training/flink-1.3.3
export PATH=$PATH:$FLINK_HOME/bin
# 配置Hadoop配置文件所在目录
export HADOOP_CONF_DIR=/training/hadoop-2.7.3/etc/hadoop
2.4环境变量生效
source ~/.bash_profile
2.5修改flink-conf.yaml
vi flink-conf.yaml
修改/添加以下内容并改成自己的主机名称
jobmanager.rpc.address: hadoop01high-availability: zookeeper
# HAhadoop01为hadoop HA的名称
high-availability.storageDir: hdfs://HAhadoop01/ha/
high-availability.zookeeper.quorum: hadoop01:2181,hadoop02:2181,hadoop03:2181//用户提交作业失败时,重新执行次数
yarn.application-attempts: 4
2.6修改slaves
vi slaves
hadoop02
hadoop03
2.7修改zoo.cfg
vi zoo.cfg
添加
server.1=hadoop01:2888:3888
server.2=hadoop02:2888:3888
server.3=hadoop03:2888:3888
2.8 拷贝flink
scp -r /training/flink-1.3.3 root@hadoop02:/training/
scp -r /training/flink-1.3.3 root@hadoop03:/training/
三、验证
3.1启动
start-cluster.sh
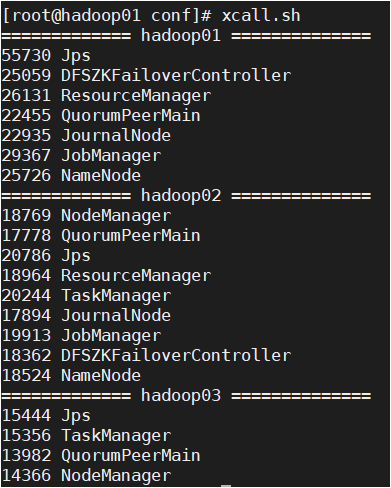
3.2jps查看进程
xcall.sh是我写的群起脚本
jps、kafka、zookeeper群起脚本和rsync文件分发脚本(超详细)_一个人的牛牛的博客-CSDN博客
3.3浏览器访问
http://hadoop01:8081
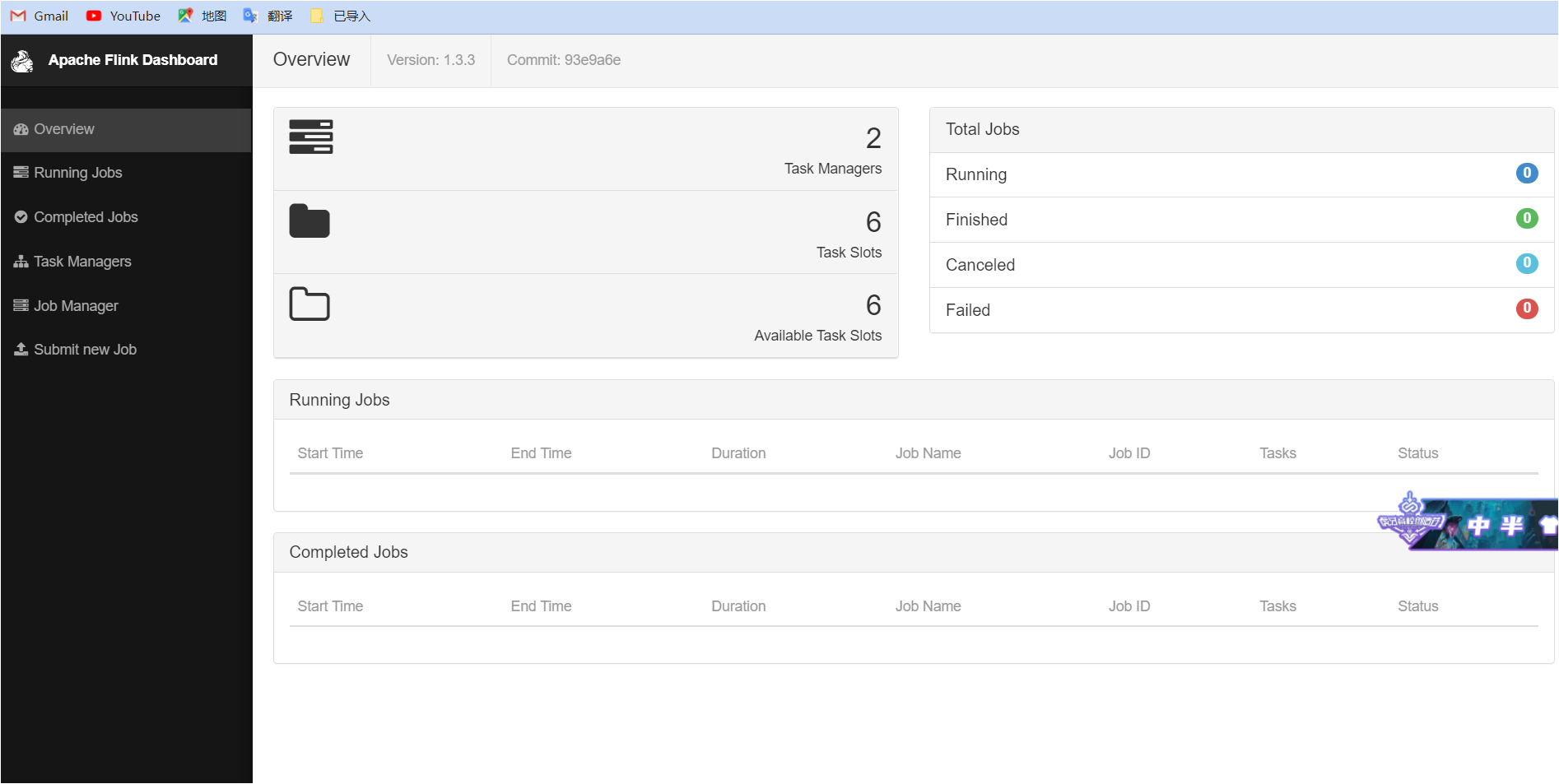
成功!!!
参考于:
Flink三种安装部署方式(HA)_小学僧丶Monk的博客-CSDN博客_flink部署模式
若兰幽竹的博客_CSDN博客-Kettle,Spark,Hadoop领域博主








 京公网安备 11010802041100号
京公网安备 11010802041100号