作者:手机用户2602901335 | 来源:互联网 | 2023-06-02 21:21
Flink-ExactlyOnce(如何保证数据的唯一性和不重复!)kafka中如何保证数据不丢失1.kafka中如何保证数据不丢失2.向kafka中sink数据packageco
Flink-Exactly Once(如何保证数据的唯一性和不重复!) kafka中如何保证数据不丢失
1. kafka中如何保证数据不丢失
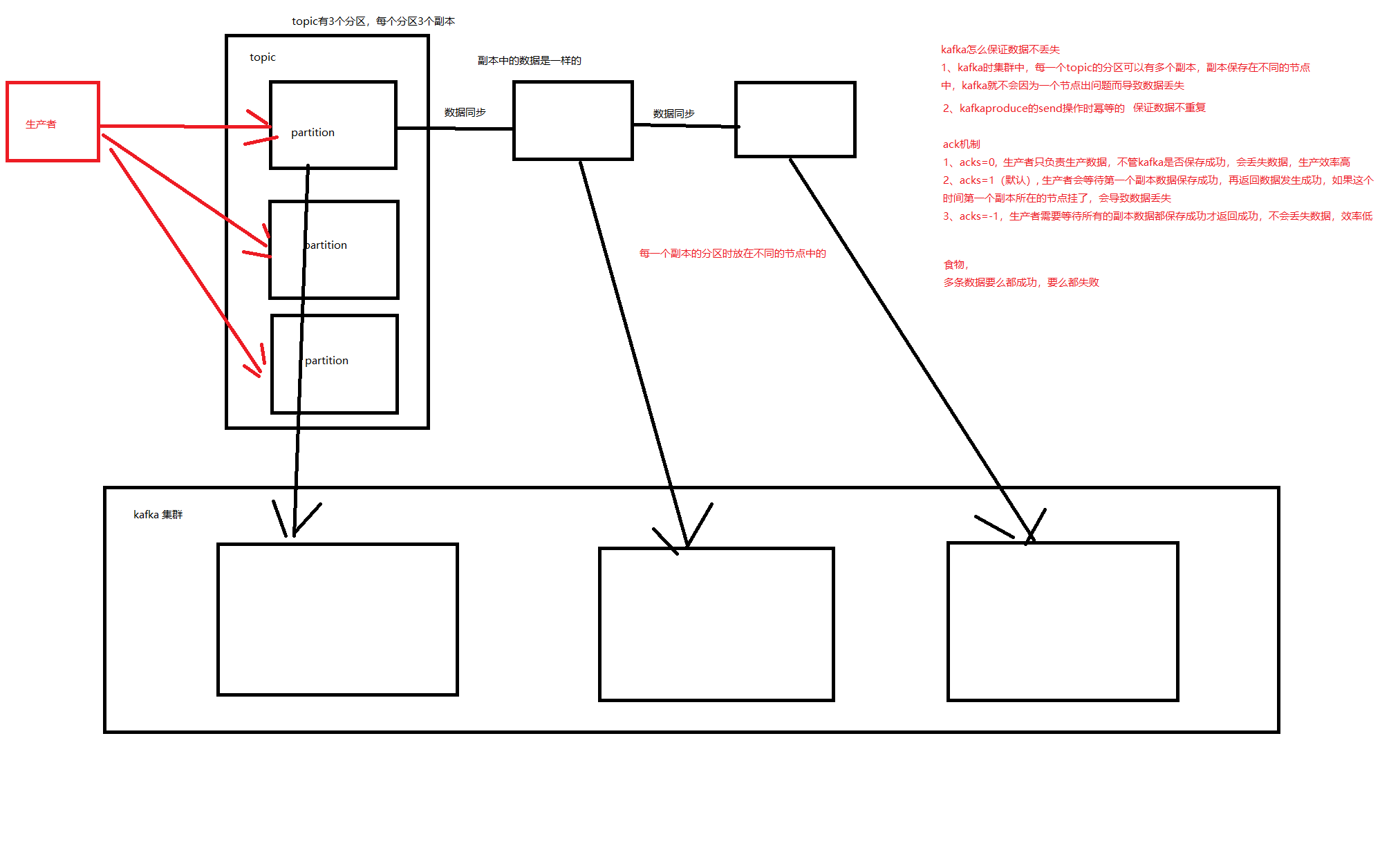
2. 向kafka中sink数据
package com.wt.flink.sink
import org.apache.flink.api.common.serialization.SimpleStringSchema
import org.apache.flink.connector.kafka.sink.{KafkaRecordSerializationSchema, KafkaSink}
import org.apache.flink.streaming.api.scala._
object Demo5KafkaSink {
def main(args: Array[String]): Unit = {
val env: StreamExecutiOnEnvironment= StreamExecutionEnvironment.getExecutionEnvironment
val studentDS: DataStream[String] = env.readTextFile("data/students.json")
/**
* 将数据保存到kafka中 --- kafka sink
*
* DeliveryGuarantee.EXACTLY_ONCE: 唯一一次
* DeliveryGuarantee.AT_LEAST_ONCE: 至少一次,默认
*/
val sink: KafkaSink[String] = KafkaSink
.builder[String]()
.setBootstrapServers("master:9092,node1:9092,node2:9092") //broker地址
.setRecordSerializer(
KafkaRecordSerializationSchema
.builder[String]()
.setTopic("students_json") //topic
.setValueSerializationSchema(new SimpleStringSchema())
.build())
//.setDeliverGuarantee(DeliveryGuarantee.AT_LEAST_ONCE) //唯一一次
.build()
//使用kafka sink
studentDS.sinkTo(sink)
env.execute()
//kafka-console-consumer.sh --bootstrap-server master:9092,node2:9092,node2:9092 --from-beginning --topic students_json
}
}
我们在从命令行读取学生的json数据
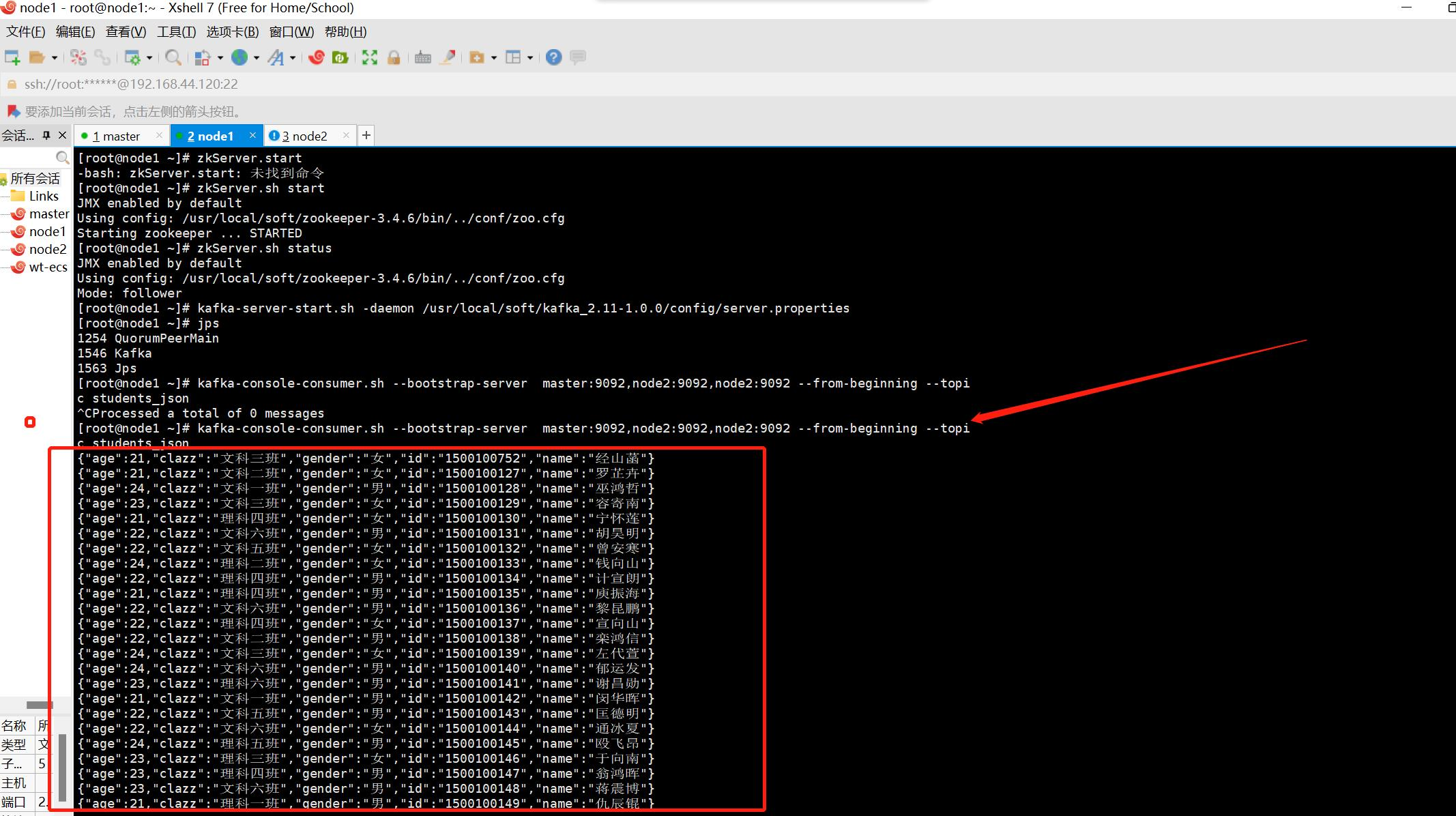
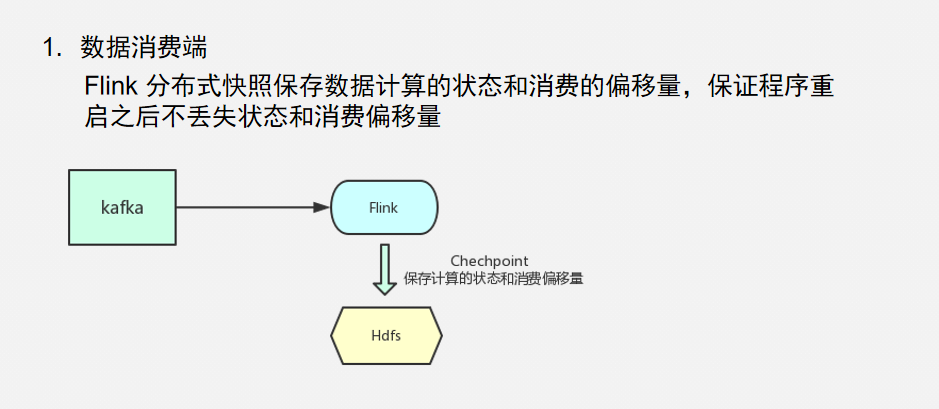
3 . Flink从kafka中读取数据
package com.wt.flink.core
import org.apache.flink.api.common.eventtime.WatermarkStrategy
import org.apache.flink.api.common.serialization.SimpleStringSchema
import org.apache.flink.connector.kafka.source.KafkaSource
import org.apache.flink.connector.kafka.source.enumerator.initializer.OffsetsInitializer
import org.apache.flink.runtime.state.hashmap.HashMapStateBackend
import org.apache.flink.streaming.api.CheckpointingMode
import org.apache.flink.streaming.api.environment.CheckpointConfig.ExternalizedCheckpointCleanup
import org.apache.flink.streaming.api.scala._
object Demo16ExactlyOnce {
def main(args: Array[String]): Unit = {
/**
* 使用flink从kafka中读取数据,怎么保证数据处理的唯一一次
*
*/
val env: StreamExecutiOnEnvironment= StreamExecutionEnvironment.getExecutionEnvironment
/**
* 开启checkpoint
*
*/
// 每 1000ms 开始一次 checkpoint
env.enableCheckpointing(20000)
// 高级选项:
// 设置模式为精确一次 (这是默认值)
env.getCheckpointConfig.setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE)
// 确认 checkpoints 之间的时间会进行 500 ms
env.getCheckpointConfig.setMinPauseBetweenCheckpoints(500)
// Checkpoint 必须在一分钟内完成,否则就会被抛弃
env.getCheckpointConfig.setCheckpointTimeout(60000)
// 允许两个连续的 checkpoint 错误
env.getCheckpointConfig.setTolerableCheckpointFailureNumber(2)
// 同一时间只允许一个 checkpoint 进行
env.getCheckpointConfig.setMaxConcurrentCheckpoints(1)
// 使用 externalized checkpoints,这样 checkpoint 在作业取消后仍就会被保留
//RETAIN_ON_CANCELLATION: 当任务取消时保留checkpoint
env.getCheckpointConfig.setExternalizedCheckpointCleanup(
ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION)
//需要设置flink checkpoint保存的位置
env.setStateBackend(new HashMapStateBackend())
//将状态保存到hdfs中
env.getCheckpointConfig.setCheckpointStorage("hdfs://master:9000/flink/checkpoint")
/**
* 消费kafka中的数据
*
*/
val source: KafkaSource[String] = KafkaSource.builder[String]
.setBootstrapServers("master:9092,node1:9092,node2:9092")
.setTopics("words")
.setGroupId("Demo16ExactlyOnce")
.setStartingOffsets(OffsetsInitializer.earliest) //只在第一次启动的时候生效,如果开启了checkpoint,任务重启之后会按照checkpoint中保证的偏移量消费数据
.setValueOnlyDeserializer(new SimpleStringSchema())
.build
val kafkaSource: DataStream[String] = env.fromSource(source, WatermarkStrategy.noWatermarks(), "Kafka Source")
val wordsDS: DataStream[String] = kafkaSource.flatMap(_.split(","))
val kvDS: DataStream[(String, Int)] = wordsDS.map((_, 1))
val keyByDS: KeyedStream[(String, Int), String] = kvDS.keyBy(_._1)
val countDS: DataStream[(String, Int)] = keyByDS.sum(1)
countDS.print()
env.execute("Demo16ExactlyOnce")
}
}
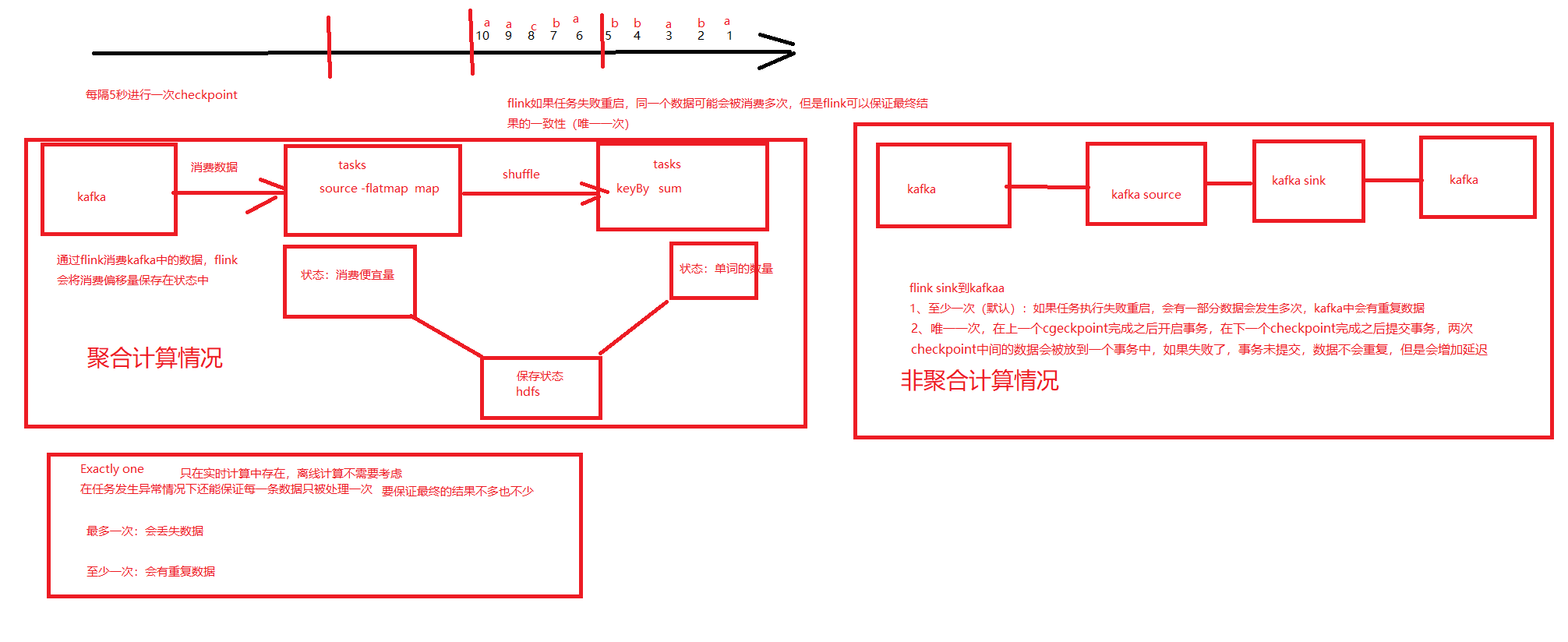
4. 从kafka中读取数据,然后再存到kafka中
重点
DeliveryGuarantee.AT_LEAST_ONCE:至少异常,会有重复数据
DeliveryGuarantee.EXACTLY_ONCE: 唯一一次
读取数据的时候.需要指定:
--isolation-level read_committed : 只读已提交的数据
package com.wt.flink.core
import org.apache.flink.api.common.eventtime.WatermarkStrategy
import org.apache.flink.api.common.serialization.SimpleStringSchema
import org.apache.flink.connector.base.DeliveryGuarantee
import org.apache.flink.connector.kafka.sink.{KafkaRecordSerializationSchema, KafkaSink}
import org.apache.flink.connector.kafka.source.KafkaSource
import org.apache.flink.connector.kafka.source.enumerator.initializer.OffsetsInitializer
import org.apache.flink.runtime.state.hashmap.HashMapStateBackend
import org.apache.flink.streaming.api.CheckpointingMode
import org.apache.flink.streaming.api.environment.CheckpointConfig.ExternalizedCheckpointCleanup
import org.apache.flink.streaming.api.scala._
import java.util.Properties
object Demo17ExactlyOnce {
def main(args: Array[String]): Unit = {
val env: StreamExecutiOnEnvironment= StreamExecutionEnvironment.getExecutionEnvironment
//开启checkpoint
// 每 1000ms 开始一次 checkpoint
env.enableCheckpointing(20000)
// 高级选项:
// 设置模式为精确一次 (这是默认值)
env.getCheckpointConfig.setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE)
// 确认 checkpoints 之间的时间会进行 500 ms
env.getCheckpointConfig.setMinPauseBetweenCheckpoints(500)
// Checkpoint 必须在一分钟内完成,否则就会被抛弃
env.getCheckpointConfig.setCheckpointTimeout(60000)
// 允许两个连续的 checkpoint 错误
env.getCheckpointConfig.setTolerableCheckpointFailureNumber(2)
// 同一时间只允许一个 checkpoint 进行
env.getCheckpointConfig.setMaxConcurrentCheckpoints(1)
// 使用 externalized checkpoints,这样 checkpoint 在作业取消后仍就会被保留
//RETAIN_ON_CANCELLATION: 当任务取消时保留checkpoint
env.getCheckpointConfig.setExternalizedCheckpointCleanup(
ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION)
/**
* 需要设置flink checkpoint保存状态的位置
*
*/
env.setStateBackend(new HashMapStateBackend())
//将状态保存到hdfs中
env.getCheckpointConfig.setCheckpointStorage("hdfs://master:9000/flink/checkpoint")
val source: KafkaSource[String] = KafkaSource.builder[String]
.setBootstrapServers("master:9092,node1:9092,node2:9092")
.setTopics("source")
.setGroupId("Demo16ExactlyOnce")
.setStartingOffsets(OffsetsInitializer.earliest) //只在第一次启动的时候生效,如果开启了checkpoint,任务重启之后会按照checkpoint中保证的偏移量消费数据
.setValueOnlyDeserializer(new SimpleStringSchema())
.build
val kafkaSource: DataStream[String] = env.fromSource(source, WatermarkStrategy.noWatermarks(), "Kafka Source")
//过滤空数据
val filterDS: DataStream[String] = kafkaSource.filter(_.nonEmpty)
/**
* DeliveryGuarantee.AT_LEAST_ONCE:至少异常,会有重复数据
* DeliveryGuarantee.EXACTLY_ONCE: 唯一一次
*
*/
//将清洗之后的数据保存到kafka中
val properties = new Properties()
//设置事务的超时时间,要比15分钟小
properties.setProperty("transaction.timeout.ms", 10 * 60 * 1000 + "")
val kafkaSink: KafkaSink[String] = KafkaSink
.builder[String]()
.setBootstrapServers("master:9092,node1:9092,node2:9092") //broker地址
.setKafkaProducerConfig(properties) //设置额外的参数
.setRecordSerializer(
KafkaRecordSerializationSchema
.builder[String]()
.setTopic("sink") //topic
.setValueSerializationSchema(new SimpleStringSchema())
.build())
.setDeliverGuarantee(DeliveryGuarantee.EXACTLY_ONCE)
.build()
filterDS.sinkTo(kafkaSink)
/**
* 通过命令好消费sink数据
* --isolation-level read_committed : 只读已提交的数据
* kafka-console-consumer.sh --bootstrap-server master:9092,node1:9092,node2:9092 --isolation-level read_committed --from-beginning --topic sink
*
*/
env.execute()
}
}






 京公网安备 11010802041100号
京公网安备 11010802041100号