 本篇了解MongoDB和传统关系数据库和Elasticsearch,从而更深印象理解MongoDB的使用场景,也通过docker-compose编排技术完成MongoDB分片集群的部署,进一步学习容器化技术,通过Spring Boot整合MongoDB熟悉数据文档操作概念,最后通过分片设置案例了解MongoDB最为代表性的可扩展性。
本篇了解MongoDB和传统关系数据库和Elasticsearch,从而更深印象理解MongoDB的使用场景,也通过docker-compose编排技术完成MongoDB分片集群的部署,进一步学习容器化技术,通过Spring Boot整合MongoDB熟悉数据文档操作概念,最后通过分片设置案例了解MongoDB最为代表性的可扩展性。
概述
定义
MongoDB官网 https://www.mongodb.com/ 社区版最新版本5.0,其中5.2版本很快也要面世了
MongoDB GitHub源码 https://github.com/mongodb
MongoDB文档地址 https://docs.mongodb.com/manual/
MongoDB是一个流行的开源分布式文档型数据库,由 C++ 语言编写,旨在处理大规模额数据,为 WEB 应用提供可扩展、高性能的数据存储解决方案。
MongoDB介于关系数据库和非关系数据库之间的产品,是非关系数据库当中功能最丰富,最像关系数据库的。前面我们学习了MySQL和Elasticsearch,我们本篇后续章节也会学习和聊聊MongoDB与这两者的故事。
特性
- 面向文档存储,MongoDB从存储结构上使用类似json的bjson格式,这就比关系型数据库MySQL存储更灵活些,不需要先定义表结构也让DDL管理更加简单,文档式结构也更容易理解;动态 DDL能力,没有强Schema约束也让DDL管理更加简单,支持更快速迭代。
- 完全分布式、高可用,高性能计算,提供基于内存的快速数据查询。
- 容易扩展,利用数据分片可以支持海量数据存储,实现自动分片和水平扩展。
- 丰富的功能集,支持二级索引、强大的聚合管道功能、事务、join,为开发者量身定做的功能,如数据自动老化、固定集合等等。MongoDB是NoSQL中最像SQL的数据库。
- 跨平台版本、支持多语言SDK。
bson和json的区别
bson是一种二进制形式的存储格式,采用了相似于C 语言结构体的名称、对表示方法,支持内嵌的文档对象和数组对象,具备轻量性、可遍历性、高效性的特色,能够有效描述非结构化数据和结构化数据,有点相似于Google的Protocol Buffer。
- 更快的遍历速度:对json格式来讲,太大的json结构会导致数据遍历变慢;在json中要跳过一个文档进行数据读取,须要对此文档进行扫描匹配比如括号的匹配,而bson将每个元素的长度存在元素的头部,这样就可快速读到指定位置。
- 操做更简易:对json来讲数据存储是无类型的,比如你要修改值9为10这样就从一个字符变成了两个字符,也即是后面的内容都要后移一位因此增加开销。而使用bson可以指定这个列为数字类型,那么数字从9改为10甚至是10000,这样都只是在存储数字上修改,不会致使数据总长度变化。当时在MongoDB中若是数字从整形增大到长整型那仍是会致使数据总长度变大的。
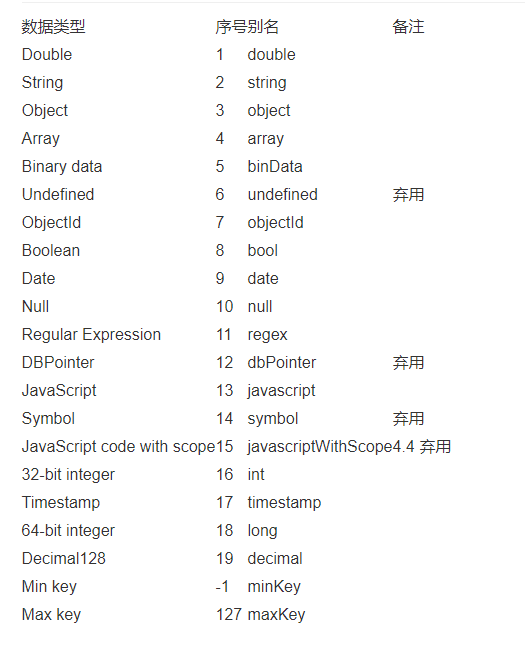
- 增加额外的数据类型:json是一个很方便的数据交换格式,可是其类型比较有限;bson在其基础上增长了“byte array”数据类型,这使得二进制的存储再也不需要先base64转换后再存成json,大大减小了计算开销和数据大小。下图为bson支持数据类型
数据模型与关系型数据库对比
- database-数据库,与关系型数据库(database)概念相同,一个数据库包含多个集合(表)。
- collection-集合,相当于关系型数据库中的表(table),一个集合可以存放多个文档(行)。不同之处就在于集合的结构(schema)是动态的,不需要预先声明一个严格的表结构。更重要的是默认情况下MongoDB 并不会对写入的数据做任何schema的校验。
- document-文档,相当于关系型数据库中的行(row),一个文档由多个字段(列)组成,并采用bson(json)格式表示。
- field-字段,相当于关系型数据库中的列(column),相比普通column的差别在于field的类型可以更加灵活比如支持嵌套的文档、数组,区分大小写。
- 其他说明
- id-主键,MongoDB 默认生成id 字段来保证文档的唯一性。
- reference-引用,勉强可以对应于外键(foreign key) 的概念,但reference 并没有实现任何外键约束,只是由客户端(driver)自动进行关联查询、转换的一个特殊类型。
- view-视图,MongoDB 3.4 开始支持视图,这个和关系型数据库的视图没有什么差异,视图是基于集合之上进行动态查询的一层对象,可以是虚拟的,也可以是物理的(物化视图)。
- index-索引,与关系型数据库的索引相同。
- $lookup-聚合操作符,可以用于实现类似关系型数据库-join连接的功能。
- transaction-事务,从 MongoDB 4.0 版本开始,提供了对于事务的支持。
- aggregation-聚合,MongoDB 提供了强大的聚合计算框架,group by是其中的一类聚合操作。
Elasticsearch与MongoDB对比
- 相同点
- 存储格式:MongoDB和Elasticsearch都属于json格式NoSQL大家族、文档型数据存储。
- 可用性和容错:MongoDB和ElasticSearch作为天生分布式的代表产品都支持数据分片、和副本、复制,两者都通过分片支持水平扩展, 同时都通过副本来支持高可用
- 分片:一个数据集的数据分为多份, 同时分布在多个节点上存储和管理, 主流分片有hash分片和range分片这两种方式,各有优势, 适合不同的场景。ElasticSearch是hash,Mongo是range和hash。
- 副本:一份数据集同时有一个或者多个复制品(或者叫主从), 每份复制品都一模一样, 但是为了保证数据的一致性, 往往多个副本中只有一个作为Primary副本(通过选主算法从多个副本中选出Primary), 提供写服务, 其他副本只提供读, 或者只提供备份服务。ElasticSearch和MongoDB都可以通过副本增强读能力, 而前面我们学习的kafka的副本是只有备份功能。
- 都支持CRUD操作、聚合、简单版join操作和处理超大规模的数据。MongoDB和ElasticSearch也都支持全文索引, 但是MongoDB的全文索引效果完全无法跟专业的搜索引擎产品ElasticSearch相比,被吊打也是可以理解的。
- 不同点
- 定位:MongoDB是文档型数据库, 提供 数据存储和管理服务,Elasticsearch 是搜索服务, 提供 数据检索服务;MongoDB作为一个数据库产品,是拥有源数据管理能力的,Elasticsearch作为一个搜索引擎, 定位是提供数据检索服务。
- 读写能力:Elasticsearch 可以从其他数据源同步数据过来提供查询, 但是不适合对数据进行存储和管理,Elasticsearch修改Mapping的代价非常高, 所以我们一般都是把新数据重新写一份新索引,然后直接切换新索引库,Elasticsearch更侧重数据的查询, 各种复杂的花式查询支持的很好。
- 存储引擎:MongoDB支持的存储引擎有WiredTiger和In-Memory;WiredTiger按照b-tree的形式来组织并进行扩展,支持两种基础文件格式:行存储和列存储,其中两者都是键/值存储的B+ tree实现,还支持日志结构的合并树实现也为B+树;In-Memory将数据只存储在内存中。Elasticsearch底层使用lucene全文检索引擎作为核心引擎。
- 部署与资源占用:集群化分片+副本的部署方式, Elasticsearch部署起来比MongoDB方便很多;MongoDB可以支持存储文件类型的数据, 作为数据库也有数据压缩能力, Elasticsearch则因为大量的索引存在需要占用大量的磁盘和内存空间,资源开销较大。
- 分布式方案:MongoDB是以节点为单位划分角色, 一旦一个节点被指定为副本, 其上面的数据都是副本;Elasticsearch是以分片为单位划分角色, 一个节点上即可以拥有某分片的主分片和可以同时拥有另一个分片的副本分片, 同时Elasticsearch还支持自动的副本负载均衡, 如果一个新节点上面什么数据都没有, 系统会自动分配分片数据过来。
- MongoDB支持事务,Elasticsearch不支持事务。
- Elasticsearch是Java编写,通过RESTFul接口操作数据。MongoDB是C++编写,通过driver操作数据。
- Elasticsearch是天生分布式,主副分片自动分配和复制,开箱即用,而MongoDB的要手动配置,且部署分片集群和配置较为麻烦。
- Elasticsearch偏向于检索、查询和数据分析,适用于OLAP(on-line Analytical Processing)系统,MongoDB偏向于大数据下的CRUD,适用于OLTP(on-line Transaction Processing)系统。
- 从时效性上看,Elasticsearch非实时,有丢数据的风险,而MongoDB是实时,理论上无丢数据的风险。
Elasticsearch和MongoDB适合使用场景
- MongoDB
- 对服务可用性和一致性有高要求,MongoDB对传统RDBMS造成强有力的竞争威胁。
- 无schema的数据存储+需要索引数据。
- 高读写性能要求, 数据使用场景简单的海量数据场景。
- 有热点数据, 有数据分片需求的数据存储。
- 日志、html、爬虫数据等半结构化或图片,视频等非结构化数据的存储。
- Elasticsearch
- 起初就是以检索查询为主要应用场景出道,与RDBMS做相互协助。
- 已经有其他系统负责数据管理。
- 对复杂场景下的查询需求,对查询性能有要求, 对写入及时性要求不高的场景。
- 监控信息/日志信息检索。
- 小团队但是有多语言服务,es拥有restful接口,用起来最方便。
分布式集群部署
集群架构
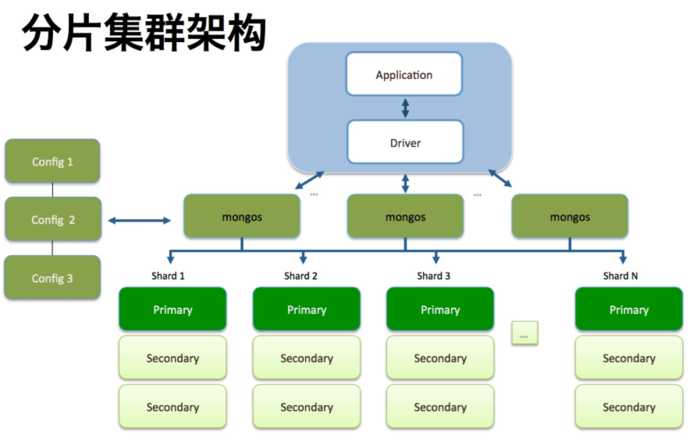
-
Shard:分片服务器:用于存储实际的数据块,实际生产环境中一个Shard Server角色可由几台机器组成一个replica set副本集承担,防止主机单点故障。
- 分片(sharding)是指将数据库拆分,将其分散在不同的机器上的过程。将数据分散到不同的机器上,不需要功能强大的服务器就可以存储更多的数据和处理更大的负载。基本思想就是将集合切成小块,这些块分散到若干片里,每个片只负责总数据的一部分,最后通过一个均衡器来对各个分片进行均衡(数据迁移)。通过一个名为mongos的路由进程进行操作,mongos知道数据和片的对应关系(通过配置服务器)。大部分使用场景都是解决磁盘空间的问题,对于写入有可能会变差,查询则尽量避免跨分片查询。
- 使用分片的时机
- 机器的磁盘不够用了。使用分片解决磁盘空间的问题。
- 单个mongod已经不能满足写数据的性能要求。通过分片让写压力分散到各个分片上面,使用分片服务器自身的资源。
- 把大量数据放到内存里提高性能,通过分片可以使用到分片服务器自身的资源。
- Config Server:配置服务器:mongod实例,存储了整个 分片群集的配置信息,其中包括 chunk信息。
- Mongos:前端路由,客户端由此接入,且让整个集群看上去像单一数据库,前端应用透明化。
部署规划
前面我们学习了Docker,本篇我们就利用docker-compose来编排部署MongoDB分片集群,那我们就开始练手了
部署一个两个副本集(每个副本集3个节点)、配置服务器集群(3个节点)、一个路由节点
一键部署脚本
当前目录下创建scripts文件夹,创建setup.sh、setup-cnf.sh、init-shard.sh和docker-compose.yml文件。
setup.sh内容如下:
#!/bin/bash
mongodb1=`getent hosts ${MONGO1} | awk '{ print $1 }'`
mongodb2=`getent hosts ${MONGO2} | awk '{ print $1 }'`
mongodb3=`getent hosts ${MONGO3} | awk '{ print $1 }'`
port=${PORT:-27017}
echo "Waiting for startup.."
until mongo --host ${mongodb1}:${port} --eval 'quit(db.runCommand({ ping: 1 }).ok ? 0 : 2)' &>/dev/null; do
printf '.'
sleep 1
done
echo "Started.."
echo setup.sh time now: `date +"%T" `
mongo --host ${mongodb1}:${port} <setup-cnf.sh内容如下:
#!/bin/bash
mongodb1=`getent hosts ${MONGO1} | awk '{ print $1 }'`
mongodb2=`getent hosts ${MONGO2} | awk '{ print $1 }'`
mongodb3=`getent hosts ${MONGO3} | awk '{ print $1 }'`
port=${PORT:-27017}
echo "Waiting for startup.."
until mongo --host ${mongodb1}:${port} --eval 'quit(db.runCommand({ ping: 1 }).ok ? 0 : 2)' &>/dev/null; do
printf '.'
sleep 1
done
echo "Started.."
echo setup-cnf.sh time now: `date +"%T" `
mongo --host ${mongodb1}:${port} <init-shard.sh内容如下:
#!/bin/bash
mongodb1=`getent hosts ${MONGOS} | awk '{ print $1 }'`
mongodb11=`getent hosts ${MONGO11} | awk '{ print $1 }'`
mongodb12=`getent hosts ${MONGO12} | awk '{ print $1 }'`
mongodb13=`getent hosts ${MONGO13} | awk '{ print $1 }'`
mongodb21=`getent hosts ${MONGO21} | awk '{ print $1 }'`
mongodb22=`getent hosts ${MONGO22} | awk '{ print $1 }'`
mongodb23=`getent hosts ${MONGO23} | awk '{ print $1 }'`
mongodb31=`getent hosts ${MONGO31} | awk '{ print $1 }'`
mongodb32=`getent hosts ${MONGO32} | awk '{ print $1 }'`
mongodb33=`getent hosts ${MONGO33} | awk '{ print $1 }'`
port=${PORT:-27017}
echo "Waiting for startup.."
until mongo --host ${mongodb1}:${port} --eval 'quit(db.runCommand({ ping: 1 }).ok ? 0 : 2)' &>/dev/null; do
printf '.'
sleep 1
done
echo "Started.."
echo init-shard.sh time now: `date +"%T" `
mongo --host ${mongodb1}:${port} <docker-compose.yml内容如下:
version: '3.9'
services:
mongo-1-2:
container_name: "mongo-1-2"
image: mongo:5.0.5
ports:
- "30012:27017"
command: mongod --replSet rs1 --shardsvr --port 27017 --oplogSize 16
restart: always
networks:
- mongo
mongo-1-3:
container_name: "mongo-1-3"
image: mongo:5.0.5
ports:
- "30013:27017"
command: mongod --replSet rs1 --shardsvr --port 27017 --oplogSize 16
restart: always
networks:
- mongo
mongo-1-1:
container_name: "mongo-1-1"
image: mongo:5.0.5
ports:
- "30011:27017"
command: mongod --replSet rs1 --shardsvr --port 27017 --oplogSize 16
restart: always
networks:
- mongo
mongo-rs1-setup:
container_name: "mongo-rs1-setup"
image: mongo:5.0.5
depends_on:
- "mongo-1-1"
- "mongo-1-2"
- "mongo-1-3"
volumes:
- ./scripts:/scripts
environment:
- MONGO1=mongo-1-1
- MONGO2=mongo-1-2
- MONGO3=mongo-1-3
- RS=rs1
entrypoint: [ "/scripts/setup.sh" ]
networks:
- mongo
mongo-2-2:
container_name: "mongo-2-2"
image: mongo:5.0.5
ports:
- "30022:27017"
command: mongod --replSet rs2 --shardsvr --port 27017 --oplogSize 16
restart: always
networks:
- mongo
mongo-2-3:
container_name: "mongo-2-3"
image: mongo:5.0.5
ports:
- "30023:27017"
command: mongod --replSet rs2 --shardsvr --port 27017 --oplogSize 16
restart: always
networks:
- mongo
mongo-2-1:
container_name: "mongo-2-1"
image: mongo:5.0.5
ports:
- "30021:27017"
command: mongod --replSet rs2 --shardsvr --port 27017 --oplogSize 16
restart: always
networks:
- mongo
mongo-rs2-setup:
container_name: "mongo-rs2-setup"
image: mongo:5.0.5
depends_on:
- "mongo-2-1"
- "mongo-2-2"
- "mongo-2-3"
volumes:
- ./scripts:/scripts
environment:
- MONGO1=mongo-2-1
- MONGO2=mongo-2-2
- MONGO3=mongo-2-3
- RS=rs2
entrypoint: [ "/scripts/setup.sh" ]
networks:
- mongo
mongo-cnf-2:
container_name: "mongo-cnf-2"
image: mongo:5.0.5
ports:
- "30102:27017"
command: mongod --replSet cnf-serv --configsvr --port 27017 --oplogSize 16
restart: always
networks:
- mongo
mongo-cnf-3:
container_name: "mongo-cnf-3"
image: mongo:5.0.5
ports:
- "30103:27017"
command: mongod --replSet cnf-serv --configsvr --port 27017 --oplogSize 16
restart: always
networks:
- mongo
mongo-cnf-1:
container_name: "mongo-cnf-1"
image: mongo:5.0.5
ports:
- "30101:27017"
command: mongod --replSet cnf-serv --configsvr --port 27017 --oplogSize 16
restart: always
networks:
- mongo
mongo-cnf-setup:
container_name: "mongo-cnf-setup"
image: mongo:5.0.5
depends_on:
- "mongo-cnf-1"
- "mongo-cnf-2"
- "mongo-cnf-3"
volumes:
- ./scripts:/scripts
environment:
- MONGO1=mongo-cnf-1
- MONGO2=mongo-cnf-2
- MONGO3=mongo-cnf-3
- RS=cnf-serv
- PORT=27017
entrypoint: [ "/scripts/setup-cnf.sh" ]
networks:
- mongo
mongo-router:
container_name: "mongo-router"
image: mongo:5.0.5
ports:
- "30001:27017"
depends_on:
- "mongo-rs1-setup"
- "mongo-rs2-setup"
- "mongo-cnf-setup"
command: mongos --configdb cnf-serv/mongo-cnf-1:27017,mongo-cnf-2:27017,mongo-cnf-3:27017 --port 27017 --bind_ip 0.0.0.0
restart: always
networks:
- mongo
mongo-shard-setup:
container_name: "mongo-shard-setup"
image: mongo:5.0.5
depends_on:
- "mongo-router"
volumes:
- ./scripts:/scripts
environment:
- MOnGOS=mongo-router
- MONGO11=mongo-1-1
- MONGO12=mongo-1-2
- MONGO13=mongo-1-3
- MONGO21=mongo-2-1
- MONGO22=mongo-2-2
- MONGO23=mongo-2-3
- RS1=rs1
- RS2=rs2
- PORT=27017
- PORT1=27017
- PORT2=27017
- PORT3=27017
entrypoint: [ "/scripts/init-shard.sh" ]
restart: on-failure:20
networks:
- mongo
networks:
mongo:
driver: bridge
ipam:
config:
- subnet: 10.200.1.10/24
部署
#docker-compose.yml当前目录下一键运行docker-compose,也可以使用-f docker-compose.yml指定文件
docker-compose up -d
#查看运行日志,至此分片集群启动和配置完成
docker-compose logs
#查看进程信息或者docker ps
docker-compose ps

##进入路由节点
docker exec -it 1eb3991a6f68 /bin/bash
## 执行mongo客户端
mongo
#查看集群分片信息,目前数据节点由rs1和rs2两个副本集组成
db.stats()
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-L6lsTfrK-1640346822317)(image-20211224172209608.png)]
#进入一个副本集节点里
docker exec -it 210f0e977622 /bin/bash
## 执行mongo客户端
mongo
#查看当前所在副本集的集群节点信息
rs.status()
实战
基础命令
MongoDB基于文档的管理,官方提供详细说明,包括插入数据、修改数据、删除数据、基础查询。
spring-boot整合
org.springframework.boot
spring-boot-starter-data-mongodb
yaml文件配置
spring:
data:
mongodb:
uri: mongodb://192.168.50.95:30001/test
import cn.aotain.entity.User;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.data.domain.Sort;
import org.springframework.data.mongodb.core.MongoTemplate;
import org.springframework.data.mongodb.core.query.Criteria;
import org.springframework.data.mongodb.core.query.Query;
import java.util.*;
@SpringBootTest
class GitTestApplicationTests {
@Autowired
private MongoTemplate mongoTemplate;
@Test
//批量插入
void batInsertUser() {
List users = new ArrayList<>();
for (long i = 1; i <= 1000; i++) {
users.add(new User(i,"user"+i, new Random().nextInt(100), UUID.randomUUID().toString(),new Date()));
}
mongoTemplate.insert(users,"user_info");
}
@Test
//查询全部
public void findAllUser() throws Exception {
List users = mongoTemplate.findAll(User.class,"user_info");
System.out.println("查询结果:" + users.toString());
}
@Test
//查询条件
public void findUserByConditionAndSort() {
Query query = new Query(Criteria.where("age").is(62)).with(Sort.by("createTime"));
List users = mongoTemplate.find(query, User.class,"user_info");
users.forEach(System.out::println);
}
@Test
//查询一个
public void findOneUser(){
Query query = new Query(Criteria.where("userId").is(233L));
User user = mongoTemplate.findOne(query, User.class,"user_info");
System.out.printf(user.toString());
}
}
分片键类型
对MongoDB集合进行分片时需要选择一个片键 , 片键是每条记录都必须包含的字段,且为建立了索引的单个字段或复合字段,MongoDB数据库按照片键将数据划分到不同的数据块中,并将数据块均衡地分布到所有分片中。为了按照片键划分数据块,MongoDB使用基于范围的分片方式或者基于哈希的分片方式。但需要注意的是一旦集合设置分片并插入文档之后每个文档的分片的键和值都是不可更改的。如果需要修改文档的分片键,必须要先删除文档,再修改分片键,然后重新插入文档。分片键也不支持数组索引,文本索引和地理空间索引。
- 基于范围的分片键
- 定义:基于范围的分片键是根据分片键值把数据分成一个个邻接的范围,如果没有指定特定的分片类型,则基于范围的分片键是默认的分片类型。
- 特点:基于范围的分片键对于范围类型的查询比较高效,给定一个片键的范围,分发路由可以很简单地确定哪个数据块存储了请求需要的数据,并将请求转发到相应的分片中。
- 使用场景:建议在分片键基数较大,频率较低,并且分片键值不是单调变化的情况下使用基于范围的分片键。
- 基于哈希的分片键
- 定义:基于哈希的分片键是指MongoDB数据库计算一个字段的哈希值,并用这个哈希值来创建数据块。
- 特点:保证了集群中数据的均衡。哈希值的随机性使数据随机分布在每个数据块中,因此也随机分布在不同分片中。
- 使用场景:如果分片键值的基数较大,拥有大量不一样的值,或者分片键值是单调变化的,则建议使用基于哈希的分片键。
分片配置
- 基于范围的分片键设置
#基于范围的分片键设置,使用如下命令,开启数据库分片开关,参数database表示要开启分片集合的数据库
sh.enableSharding(database)
#设置分片键,参数namespace表示需要进行分片的目标集合的完整命名空间.,key表示要设置分片键的索引,如果需要进行分片的目标集合是空集合,可以不创建索引直接进行下一步的分片设置,该操作会自动创建索引,如果需要进行分片的目标集合是非空集合,则需要先创建索引key。然后使用如下命令设置分片键。
sh.shardCollection(namespace, key)
- 哈希的分片键设置
然后再使用如下命令创建基于哈希的分片键#基于范围的分片键设置,使用如下命令,开启数据库分片开关,参数database表示要开启分片集合的数据库
sh.enableSharding(database)
#设置基于哈希的分片键,其中numInitialChunks值的估算方法是:db.collection.stats().size / 10*1024*1024*1024。
sh.shardCollection(".", { : "hashed" }* , false, {numInitialChunks: 预置的chunk个数})
#如果集合已经包含数据,则需要先使用如下命令对需要创建的基于哈希的分片键先创建哈希索引
db.collection.createIndex()
#然后再使用如下命令创建基于哈希的分片键
sh.shardCollection()
分片实验
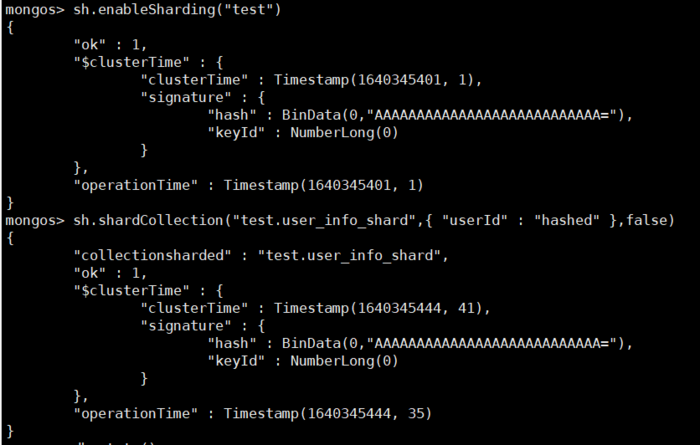
#基于Hash分片
sh.enableSharding("test")
sh.shardCollection("test.user_info_shard",{ "userId" : "hashed" },false)
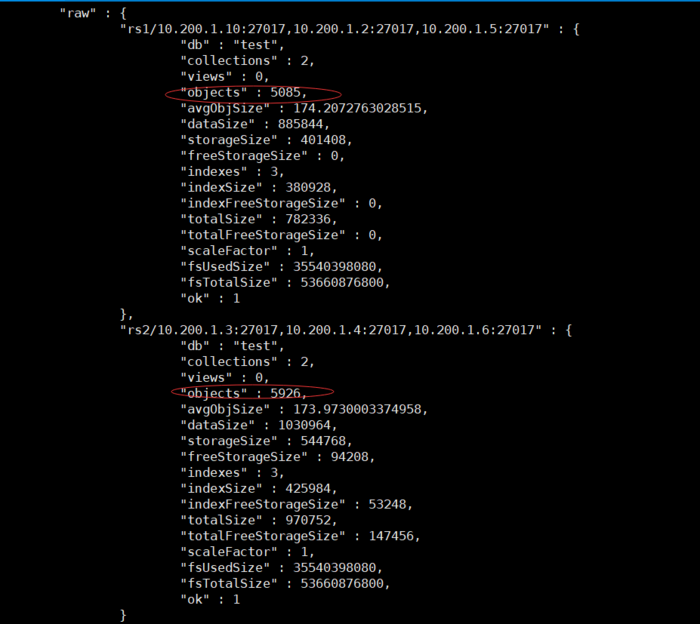
我们往test.user_info_shard集合中插入10000条数据,查看两个rs中的文档数可以看到数据已经分散到两个副本集集群中了。
**本人博客网站 **IT小神 www.itxiaoshen.com







 京公网安备 11010802041100号
京公网安备 11010802041100号