分布式系统由多个独立的代码片段组成,它们在多个位置的许多处理节点上并行或并发地执行。因此,根据定义,任何分布式系统都是并发系统,即使每个节点一次只处理一个事件。当然,必须协调各个节点的行为,才能使应用程序按照所需的方式运行。
在分布式系统中协调节点充满了危险。幸运的是,行业已经足够成熟,可以提供复杂、强大的软件框架,这些框架将许多分布式系统的危险从我们的应用程序中隐藏起来——至少大多数时候是这样。
本文关注的是我们的系统在单个节点上的并发行为。通过显式地编写软件以并发执行多个操作,我们可以优化单个节点上的处理和资源利用率,从而提高本地和系统范围内的处理能力。
本文使用Java 并发功能作为示例。在构建并发和分布式系统时,了解并发系统如何“接近机器”运行是基本的基础知识。一旦理解了构建并发系统的较低机制,就更容易优化地利用更抽象的方法。
本文是并发的入门。不涉及构建复杂、高性能并发系统所需的所有知识。
想想一个繁忙的咖啡店。如果每个人都点了一杯简单的咖啡,那么咖啡师就可以快速、稳定地把每一杯都送上来。突然,你前面的人点了一杯豆奶,香草,不加糖,四倍浓缩冰酿。排队的每个人都叹气,开始阅读他们的社交媒体。两分钟后队伍就出了门。
在Web应用程序中处理请求类似于我们的咖啡示例。在咖啡店里,我们会请一位新咖啡师帮忙,用不同的机器同时煮咖啡,以控制排队的长度,并迅速为顾客服务。在软件中,为了使应用程序能够响应,我们需要以某种方式在服务器中以重叠的方式处理请求,并发地处理请求。
在过去的计算机时代,每个CPU在任何时候都只能执行一条机器指令。如果我们的服务器应用程序运行在这样一个CPU上,为什么我们需要构造我们的软件系统来并发地执行多个指令呢?这一切似乎无意义。
其实有一个很好的理由。事实上,每个程序不仅仅是执行机器指令。例如,当一个程序试图从一个文件中读取数据或在网络上发送消息时,它必须与作为CPU外围设备的硬件子系统(磁盘、网卡)交互。从现代硬盘读取数据大约需要10毫秒(ms)。在此期间,程序必须等待数据可用以进行处理。
现在,即使是一个古老的CPU,比如大约1988年的Intel 803861,每秒也可以执行超过1000万条指令(mips)。10毫秒是百分之一秒。我们的80386在1/100秒内可以执行多少条指令?事实上,这浪费了大量的处理能力。
这就是像Linux这样的操作系统如何在一个CPU上运行多个程序。当一个程序在等待输入-输出(I-O)事件时,操作系统调度另一个程序执行。通过明确地构造我们的软件,使其具有可以并行执行的多个活动,操作系统可以在其他任务等待I-O时安排有工作要做的任务。
2001年,IBM推出了世界上第一个多核处理器,一个有两个cpu的芯片-参见图1的简化说明。如今,普通的笔记本都有8个cpu,也就是人们通常所说的核心。在多核芯片中,一个软件系统被构造成具有多个并行活动,可以在每个核上并发执行,增加可用核的数量。这样可以充分利用多核芯片上的处理资源,从而提高应用程序的处理能力。
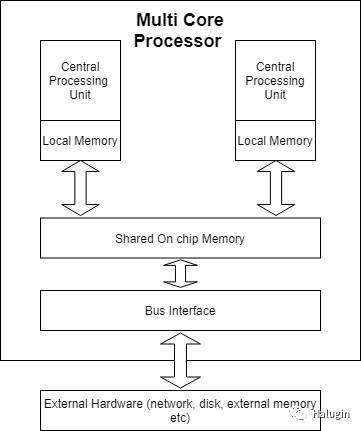
将软件系统构造为并发活动的主要方法是使用线程。几乎每一种编程语言都有自己的线程机制。所有这些机制的底层语义都是相似的——只有少数主流使用的主要线程模型——但显然语法因语言而异。如下,我将解释Java中如何支持线程,以及在并行执行时如何设计安全(即正确)和高效的程序。掌握了这些知识后,要想了解其他语言中支持的并发特性应该不会太费力。
并发模型
本文描述了并发系统的一种模型,基于使用锁对共享的可变资源进行操作的独立执行线程。近50年来,并发模型一直是计算机科学中一个被广泛研究和探索的主题。人们提出了许多理论建议,其中一些是用现代编程语言实现的。这些模型为在程序中组织和协调并行活动提供了可选的方法。
Go:通信顺序过程(CSP)模型是Go并发特性的基础在CSP中,进程通过使用称为通道的通信抽象发送消息来进行同步。在Go中,并发单元是goroutine, goroutine通过使用非缓冲或缓冲通道发送消息进行通信。非缓冲通道用于同步发送方和接收方,因为只有当两个goroutine都准备好交换数据时才会发生通信。
Erlang:Erlang实现了Actor模型的并发。参与者是没有共享状态的轻量级进程,通过异步向其他参与者发送消息进行通信。参与者使用邮箱或队列来缓冲消息,并可以使用模式匹配来选择要处理的消息。
Node.js:Node.js避免了任何类似于多线程的东西,而是利用了一个由事件循环管理的单线程、非阻塞模型这意味着当需要输入-输出(IO)操作时,比如访问数据库,Node.js会启动操作,但不会等到操作完成。操作委托给操作系统异步执行,完成后,结果作为回调放在主线程的堆栈上。这些回调函数随后在事件循环中执行。这个模型对于执行频繁IO请求的代码很有效,因为它避免了与线程创建和管理相关的开销。但是,如果你的代码需要执行CPU密集型操作,比如对一个大列表进行排序,那么你只有一个线程。因此,这将阻塞所有其他请求,直到排序完成。很少有理想的情况。
默认情况下,每个软件进程都有一个执行线程。这是操作系统在调度进程执行时管理的线程。例如,在Java中,你指定为代码入口点的main()
函数定义了该线程的行为。这个线程可以访问程序的环境和资源,比如打开的文件句柄和网络连接。当程序调用在代码中实例化的对象中的方法时,程序的运行时堆栈被用来传递参数和管理变量范围。标准编程语言运行时的东西,我们都知道和喜欢。这是一个连续的过程。
在你的系统中,你可以使用编程语言特性来创建和执行额外的线程。每个线程都是一个独立的执行序列,并且有自己的运行时堆栈来管理本地对象创建和方法调用。每个线程还可以访问进程的全局数据和环境。简单描述如图2所示。

在Java中,我们可以使用实现Runnable
接口并定义run()
方法的类来定义线程。下面的例子描述了一个简单的例子:
class NamingThread implements Runnable { private String name; public NamingThread(String threadName) {
name = threadName ;
System.out.println("Constructor called: " + threadName) ;
} public void run() { //Display info about this thread
System.out.println("Run called : " + name);
System.out.println(name + " : " + Thread.currentThread()); // and now terminate ....
}
}
要执行线程,我们需要使用Runnable
的实例构造一个thread对象,并调用start()
方法来在自己的执行上下文中调用代码。下面的代码示例显示了这一点,以及以粗体文本显示的运行代码的输出。注意,这个示例有两个线程——main()
线程和NamingThread
。主线程启动NamingThread
,它会异步执行,然后等待1秒,给NamingThread
中的run()
方法足够的时间来完成。
public static void main(String[] args) {
NamingThread name0 = new NamingThread("My first thread"); //Create the thread
Thread t0 = new Thread (name0); // start the threads
t0.start(); //delay the main thread for a second (1000 milliseconds)
try {
Thread.currentThread().sleep(1000);
} catch (InterruptedException e) {} //Display info about the main thread and terminate
System.out.println(Thread.currentThread());
}
===EXECUTION OUTPUT===
Constructor called: My first thread
Run called : My first thread
My first thread : Thread[Thread-0,5,main]
Thread[main,5,main]
为了说明这一点,我们还调用了静态currentThread()
方法,它返回一个包含以下内容的字符串:
系统生成线程标识符
线程优先级,默认情况下所有线程的优先级为5
父线程的标识符
注意,为了实例化一个线程,我们调用start()
方法,而不是在Runnable
中定义的run()
方法。start()
方法包含内部系统魔法,用于为要执行的单独线程创建执行上下文。如果我们直接调用run()
,代码将执行,但不会创建新的线程。run()
方法将作为主线程的一部分执行,就像你知道并喜欢的任何其他Java方法调用一样。你仍然会有一个单线程代码。
在这个例子中,我们使用sleep()
来暂停主线程的执行,并确保它不会在NamimgThread
之前终止。这种方法,即通过延迟一个绝对时间周期(例如示例中的1秒)来协调两个线程,并不是一种非常健壮的机制。如果由于某些原因——较慢的CPU、较长的读取磁盘延迟、方法中额外的复杂逻辑——我们的线程没有在预期的时间框架内终止,该怎么办?在这种情况下,main
将首先终止—这不是我们想要的。通常,如果你使用绝对时间来进行线程协调,那么你的做法是错误的。几乎总是。比如99.99999%的时间。
一个线程等待另一个线程完成其工作的简单而健壮的机制是使用join()
方法。我们可以将上面例子中的try-catch
块替换为:
t0.join();
这个方法导致调用线程(在本例中是main
)阻塞,直到t0
引用的线程终止。如果所引用的线程在调用join()
之前已经终止,那么方法调用将立即返回。通过这种方式,我们可以协调或同步多个线程的行为。
系统调度器(在Java中,它存在于JVM中)控制线程执行的顺序。从程序员的角度来看,执行的顺序是不确定的。非确定性的概念是理解多线程代码的基础。
我将通过构建前面的NamingThread
示例来说明这一点。我将创建并启动几个NamingThread
,而不是创建一个单独的NamingThread
。实际上有三个,如下面的代码示例所示。
NamingThread name0 = new NamingThread("thread0");
NamingThread name1 = new NamingThread("thread1");
NamingThread name2 = new NamingThread("thread2"); //Create the threads
Thread t0 = new Thread (name0);
Thread t1 = new Thread (name1);
Thread t2 = new Thread (name2); // start the threads
t0.start();
t1.start();
t2.start();
===EXECUTION OUTPUT===
Run called : thread0
thread0 : Thread[Thread-0,5,main]
Run called : thread2
Run called : thread1
thread1 : Thread[Thread-1,5,main]
thread2 : Thread[Thread-2,5,main]
Thread[main,5,main]
所示的输出只是一次执行的示例。你可以看到代码依次启动了三个线程,即t0、t1和t2。查看输出,我们看到线程t0在其他线程开始之前完成。接下来调用t2的run()
方法,然后调用t1的run()
方法,即使t1在t2之前启动。然后,线程t1在t2之前运行到结束,最终主线程和程序终止。
这只是一种可能的执行顺序。如果我们再次运行这个程序,我们几乎肯定会看到一个不同的执行轨迹。这是因为JVM调度器决定执行哪个线程以及执行多长时间。简单地说,一旦调度程序在CPU上给了线程一个执行时隙,它就可以在指定的时间段之后中断线程并安排另一个线程运行。这种中断被称为抢占。抢占确保每个线程都有机会进行进程。因此,线程在完成之前是独立和异步运行的,调度程序根据调度算法决定哪个线程运行。
并发编程的基本问题是协调多个线程的执行,以便不管它们以什么顺序执行,它们都能产生正确的答案。如果线程可以非确定性地启动和抢占,那么任何中等复杂的程序基本上都会有无限个可能的执行顺序。这些系统不容易测试。
所有并发程序都需要避免两个基本问题:竞争条件和死锁。
线程的非确定性执行意味着组成线程的代码语句:
将按每个线程中定义的顺序执行
可以以任何顺序跨线程重叠。这是因为为每个线程执行槽执行的语句数量是由调度器决定的。
因此,当许多线程在一个处理器上执行时,它们的执行是交错的。CPU从一个线程执行一些步骤,然后从另一个线程执行一些步骤,以此类推。如果我们在多核CPU上执行,那么我们可以在每个核上执行一个线程。然而,每个线程执行的语句仍然以一种不确定的方式交织在一起。
现在,如果每个线程只是做它自己的事情,并且是完全独立的,这不是一个问题。每个线程都会执行,直到它被终止,就像我们简单的NamingThread
示例一样。
不幸的是,完全独立的线程并不是大多数多线程系统的行为方式。如果你回顾图2,你会发现多个线程在一个进程内共享全局数据。在Java中,这既是全局数据也是静态数据。
线程可以使用共享的数据结构来协调它们的工作和跨线程通信状态。例如,我们可能有线程处理来自Web客户机的请求,每个请求一个线程。我们还希望保持每天处理请求的总数。当一个线程完成一个请求时,它会增加一个全局的RequestCounter
对象,所有线程在每次请求后都会共享和更新这个对象。
下面的代码展示了一个非常简单的实现,它模拟了请求反例场景。它创建50k线程来更新一个共享计数器。注意,为了简洁起见,我们使用了lambda函数来创建线程。
public class RequestCounter { final static private int NUMTHREADS = 50000; private int count = 0; public void inc() {
count++;
} public int getVal() { return this.count;
} public static void main(String[] args) throws InterruptedException { final RequestCounter counter = new RequestCounter(); for (int i = 0; i
Runnable thread = () -> {counter.inc(); }; new Thread(thread).start();
}
Thread.sleep(5000);
System.out.println("Value should be " + NUMTHREADS + "It is: " + counter.getVal());
}
}
在10次执行中,我的平均值是49995。我一次也没有得到50000这个正确答案。为什么?
答案在于如何在机器上执行抽象的高级编程语言语句(在本例中是Java)。在这个例子中,要执行计数器的增量,CPU必须(1)将当前值加载到寄存器中,(2)增加寄存器值,(3)将结果写回原来的内存位置。这个简单的增量实际上是三个机器级操作的序列。
如图3所示,在机器级别上,这三个操作是独立的,而不是单个原子操作。原子的意思是一个不能被中断的操作,因此一旦启动就会一直运行到完成。

由于增量操作在机器级别上不是原子操作,一个线程可以将计数器值从内存加载到CPU寄存器中,但在将增量值写回之前,调度器会抢占该线程并允许另一个线程启动。这个线程从内存中加载计数器的旧值,并写回增加的值。最终,原始线程再次执行,并回写其加1的值,该值恰好与内存中已经存在的值相同。
这意味着我们失去了最新消息。从我们对上面计数器代码的10次测试中,我们看到这种情况在50000个增量中平均发生了5次。因此,这样的事件很少见,但即使它发生在1000万次中1次,你仍然会得到一个错误的结果。
当我们以这种方式丢失更新时,它被称为竞争条件。当多个线程对某些共享状态进行更改时,就会发生竞争条件,在本例中是一个简单的计数器。从本质上讲,不同的线交织可以产生不同的结果。
竞态条件是潜伏的、有害的错误,因为它们的发生通常很罕见,而且很难检测到,因为大多数时候答案都是正确的。尝试使用1000而不是50000个线程运行多线程计数器代码示例,你将看到实际效果。
所以,这种情况可以总结为“相同的代码,偶尔不同的结果”。如果你采取一些预防措施,根除它们是很简单的。
关键是识别和保护关键部分。临界段是更新共享数据结构的一段代码,因此如果被多个线程访问,就必须以原子方式执行。递增共享计数器的例子就是临界区的例子。另一种方法是从列表中删除一项。我们需要删除列表的头节点,并将对列表头的引用从被删除的节点移动到列表中的下一个节点。这两个操作都必须以原子方式执行,以保持列表的完整性。这是一个关键的部分。
在Java中,synchronized
关键字定义了一个临界区。如果用于修饰一个方法,那么当多个线程试图在同一个共享对象上调用该方法时,只有一个线程被允许进入临界区。所有其他线程都将阻塞,直到线程退出同步方法,此时调度器将选择下一个线程来执行临界区段。我们说临界区段的执行是序列化的,因为一次只能有一个线程执行其中的代码。
为了修复这个反例,你只需要将inc()
方法标识为一个临界区,并使它成为一个同步方法,即:
synchronized public void inc() {
count++;
}
想测试多少就测试多少次。总会得到正确的答案。更正式一点说,这意味着调度程序向我们抛出的任何线程交错都将总是产生正确的结果。
synchronized
关键字也可以应用于方法中的语句块。例如,我们可以将上面的例子重写为:
public void inc() {synchronized(this){
count++;
}
}
在底层,每个Java对象都有一个监视器锁(有时称为内在锁),作为其运行时表示的一部分。显示屏就像长途汽车上的卫生间,一次只允许一个人进入,使用时,门锁阻止其他人进入。
在我们的Java运行时环境中,线程必须获得监视器锁才能进入同步方法或同步语句块。在任何时候,只有一个线程可以拥有锁,因此执行是序列化的。这基本上就是Java和类似语言实现关键部分的方式。
根据经验,应该使关键部分尽可能小,以使序列化代码最小化。这对性能和可伸缩性有积极的影响。正如Amdahl所描述的,同步块是系统的序列化部分,它们执行的时间越长,系统可伸缩性的潜力就越小。
当两个或多个线程被永久阻塞,并且没有一个线程可以继续时,就会发生死锁。当线程需要独占访问一组共享资源,并且线程以不同的顺序获取锁时,就会发生这种情况。见下面的例子中,两个线程需要独占访问关键部分A和B。线程1获得锁的关键部分,和线程2的锁临界段B。
两个线程通过同步块共享对两个共享变量的访问:
线程1:进入临界区A
线程2:进入临界区B
线程1:进入临界区B时阻塞
线程2:进入临界区A时阻塞
两个线程都永远等待
死锁最经典的例子是哲学家就餐问题,如下:
五个哲学家围坐在一张共享的桌子旁。作为哲学家,他们花很多时间进行深入思考。在深思之间,他们会吃摆在面前的一盘食物来补充大脑功能。因此,哲学家要么在吃,要么在思考,要么在这两种状态之间转换。
桌子上只有五根筷子,放在每个哲学家之间。当一个哲学家想要吃东西时,他们会遵循先拿左手筷子,然后再拿右手筷子的规矩。一旦他们准备重新思考,他们首先返回右边的筷子,然后是左边的。

图4描绘了我们的哲学家,每个哲学家都有一个唯一的数字。由于每个哲学家都在同时进食或思考,我们可以将每个哲学家建模为一个线程。
共享筷子由Java Object类的实例表示。因为在任何时候只有一个物体可以保持一个物体上的显示器锁,所以它们被用作哲学家获取他们需要吃的筷子的关键部分的入口条件。吃完饭,把筷子放回桌子上,打开筷子上的锁,这样旁边的哲学家就可以随时吃饭了。
1 public class Philosopher implements Runnable {23 private final Object leftChopStick;4 private final Object rightChopStick;56 Philosopher(Object leftChopStick, Object rightChopStick) {7 this.leftChopStick = leftChopStick;8 this.rightChopStick = rightChopStick;9 }10 private void LogEvent(String event) throws InterruptedException {11 System.out.println(Thread.currentThread()12 .getName() + " " + event);13 Thread.sleep(1000);14 }1516 public void run() {17 try {18 while (true) {19 LogEvent(": Thinking deeply");20 synchronized (leftChopStick) {21 LogEvent( ": Picked up left chop stick");22 synchronized (rightChopStick) {23 LogEvent(": Picked up right chopstick – eating");24 LogEvent(": Put down right chopstick");25 }26 LogEvent(": Put down left chopstick. Ate too much");27 }28 } // end while29 } catch (InterruptedException e) {30 Thread.currentThread().interrupt();31 }32 }33 }
为了使上面描述的哲学家栩栩如生,我们必须为每个哲学家实例化一个线程,并让每个哲学家使用相邻的筷子。通过下面例子中第16行中的线程构造函数调用完成的。在for循环中,我们创建了5个哲学家,并将它们作为独立的线程开始,其中每根筷子可以被两个线程访问,一个作为左筷子,一个作为右筷子。
private final static int NUMCHOPSTICKS = 5 ;private final static int NUMPHILOSOPHERS = 5;public static void main(String[] args) throws Exception { final Philosopher[] ph = new Philosopher[NUMPHILOSOPHERS];
Object[] chopSticks = new Object[NUMCHOPSTICKS]; for (int i = 0; i
} for (int i = 0; i
Object rightChopStick = chopSticks[(i + 1) % chopSticks.length];
ph[i] = new Philosopher(leftChopStick, rightChopStick);
}
Thread th = new Thread(ph[i], "Philosopher " + (i + 1));
th.start();
}
}
运行这段代码会在第一次尝试时产生以下输出。如果你运行代码,你几乎肯定会看到不同的输出,但最终结果将是相同的。
Philosopher 4 : Thinking deeply
Philosopher 5 : Thinking deeply
Philosopher 1 : Thinking deeply
Philosopher 2 : Thinking deeply
Philosopher 3 : Thinking deeply
Philosopher 4 : Picked up left chop stick
Philosopher 1 : Picked up left chop stick
Philosopher 3 : Picked up left chop stick
Philosopher 5 : Picked up left chop stick
Philosopher 2 : Picked up left chop stick
10行输出,然后……什么都没有!我们陷入僵局了。这是典型的循环等待死锁。想象一下以下场景:
每个哲学家都沉浸在长时间的思考中
同时,他们都觉得饿了,伸手去拿左边的筷子。
没有一个哲学家能吃,没有人能拿起他们的右手筷子一样
在这种情况下,真正的哲学家会想出一些方法,放下一根或两根筷子,直到他们的一个或多个同事可以吃东西。我们有时可以在我们的软件中通过使用阻塞操作的超时来做到这一点。当超时到期时,线程释放临界区并重试,让其他被阻塞的线程有机会继续。但是这并不是最优的,因为阻塞的线程会影响性能,并且超时值的设置并不精确。
因此,最好设计一个没有死锁的解决方案。这意味着一个或多个线程总是能够取得进展。对于循环等待死锁,这可以通过在共享资源上强加资源分配协议来实现,这样线程就不会总是以相同的顺序请求资源。
在用餐哲学家的问题中,我们可以通过让我们的一位哲学家先拿起他们右手的筷子来做到这一点。让我们假设我们让哲学家4这样做。这将导致如下操作的可能序列:
Philosopher 0 picks up left chopstick (chopStick[0]) then right (chopStick[1])Philosopher 1 picks up left chopstick (chopStick[1]) then right (chopStick[2])Philosopher 2 picks up left chopstick (chopStick[2]) then right (chopStick[3])Philosopher 3 picks up left chopstick (chopStick[3]) then right (chopStick[4])Philosopher 4 picks up right chopstick (chopStick[0]) then left (chopStick[4])
在这个例子中,哲学家4必须阻塞,因为哲学家0已经获得了对筷子[0]的访问权。当哲学家4被阻止时,哲学家3被保证可以使用筷子[4],然后可以继续满足他们的胃口。
哲学家用餐解决方案如下所示。
if (i == NUMPHILOSOPHERS - 1) { // The last philosopher picks up the right fork first
ph[i] = new Philosopher(rightChopStick, leftChopStick);
} else { // all others pick up the left chop stick first
ph[i] = new Philosopher(leftChopStick, rightChopStick);
}
}
在更正式的情况下,我们对获取共享资源作出命令,如下:
chopStick[0]
这意味着每个线程总是尝试在使用[1]之前获取[0],在使用[2]之前获取[1],等等。对于哲学家4来说,这意味着它将在筷子[4]之前尝试获得筷子[0],从而打破了循环等待死锁的可能性。
死锁是一个复杂的主题,在许多分布式系统中j将看到死锁。例如,用户请求获得对Students数据库表中的某些数据的锁,然后必须更新Classes表中的行以反映学生出勤率。同时,另一个用户请求获得Classes表上的锁,next必须更新Students表中的一些信息。如果这些请求相互交错,使得每个请求以重叠的方式获得锁,就会出现死锁。
多线程系统有一个系统调度程序,它决定在什么时候运行哪些线程。在Java中,调度器被称为抢占式的、基于优先级的调度器。简而言之,这意味着它选择执行希望运行的最高优先级的线程。
每个线程都有一个优先级(默认为5,范围从0到10)。线程从它的父线程继承它的优先级。高优先级线程比低优先级线程更频繁地被调度,但在大多数应用程序中,将所有线程作为默认优先级就足够了。
调度器根据线程的行为,在四个不同的状态中循环线程。如下:
创建
线程对象已创建,但尚未调用其start()
方法。一旦start()
被调用,线程就进入可运行状态。
可运行的
线程可以运行。调度程序将以先进先出(FIFO)的方式选择执行哪个线程——一个线程可以在任何时候分配给节点中的每个核心。然后线程执行直到阻塞(例如,在一个同步语句上),执行yield(), suspend()或sleep()语句,run()方法终止,或被调度程序抢占。抢占发生在高优先级线程变得可运行时,或当系统特定的时间段(称为时间片)到期时。基于时间切片的抢占允许调度程序确保所有线程最终都有机会执行——没有渴求执行的线程可以霸占CPU。
阻塞
如果线程正在等待一个锁,一个通知事件发生(例如,睡眠计时器到期,resume()方法执行),或者正在等待一个网络或磁盘请求完成,线程就会被阻塞。当阻塞线程正在等待的特定事件发生时,它将移回可运行状态。
终止
线程的run()
方法已经完成,或者已经调用stop()
方法。该线程将不再被调度。
该方案如图5所示。调度器有效地为每个线程优先级维护处于可运行状态的FIFO队列。高优先级线程通常用于响应事件(如紧急计时器),并在短时间内执行。低优先级线程用于后台正在进行的任务,例如通过重新计算校验和来检查磁盘上的文件是否损坏。后台线程基本上会耗尽空闲的CPU周期。

有许多问题需要具有不同角色的线程来协调它们的活动。假设有一组线程,每个线程接受来自用户的文档,对文档进行一些处理(例如生成pdf),然后将处理后的文档发送到共享的打印机池。每个打印机一次只能打印一个文档,因此它们从共享打印队列读取文档,按文档到达的顺序抓取和打印文档。
这个印刷问题是典型的生产者-消费者问题的一个例证。生产者通过共享的FIFO缓冲区生成和发送消息给消费者。使用者检索这些消息,处理它们,然后从缓冲区请求更多的工作。图4-6是这个问题的一个简单说明。这有点像一个24小时,365天的自助餐厅——厨房一直在生产,服务员收集食物并把它放在自助餐厅,饥饿的食客自己取用。

与几乎所有实际资源一样,缓冲区的容量有限。生产者生成新项,但如果缓冲区已满,它们必须等待一些项被消耗后才能将新项添加到缓冲区。类似地,如果消费者的消费速度快于生产者的生产速度,那么如果缓冲区中没有商品,他们就必须等待,并且在新商品到达时以某种方式收到警报。
生产者等待缓冲区中的空间或消费者等待项的一种方法是不断重试操作。生产者可以休眠一秒钟,然后重试put操作,直到操作成功。消费者也可以这样做。
这种解决方案称为轮询,或忙等待。它工作得很好,但正如第二个名字所暗示的那样,每个生产者和消费者在每次重试和失败时都在使用资源(CPU、内存,也许是网络?)如果这不是问题,那很好,但在可伸缩系统中,我们总是致力于优化资源使用,而轮询可能造成浪费。
更好的解决方案是让生产者和消费者阻塞,直到他们想要的操作(分别是put或get)成功。阻塞线程不消耗资源,因此提供了一种有效的解决方案。为了实现这一点,线程编程模型提供了阻塞操作,使线程能够在事件发生时向其他线程发出“信号”。对于生产者-消费者问题,基本方案如下:
当生产者向缓冲区中添加条目时,它会向任何被阻塞的消费者发送一个信号,通知他们缓冲区中有条目
当消费者从缓冲区中检索到一个条目时,它会向任何被阻塞的生产者发送一个信号,通知他们缓冲区中有容纳新条目的容量。
在Java中,有两个基本原语,即wait()
和notify()
,可用于实现此信令方案。简单地说,它们是这样工作的:
如果线程要求的某些条件不为真,它可以在同步块中调用wait()
。例如,线程可能试图从缓冲区检索消息,但如果缓冲区没有消息可检索,它调用wait()
并阻塞,直到另一个线程添加消息,将条件设置为true,并在同一对象上调用notify()
。
Notify()
唤醒在对象上调用了wait()
的线程。
这些Java原语用于实现保护块。被保护的块使用一个条件作为保护,在线程恢复执行之前必须保持这个条件。下面的代码片段显示了如何使用保护条件来阻止试图从空缓冲区检索消息的线程。
while (empty) { try {
System.out.println("Waiting for a message");
wait();
} catch (InterruptedException e) {}
}
当另一个线程向缓冲区添加消息时,它将执行下面代码片段中的notify()
。
// Store message.this.message = message;
empty = false;// Notify consumer that message is availablenotify();
与生产者-消费者问题相关的一个例子是java.util.concurrent.BlockingQueue
中的BlockingQueue接口。BlockingQueue
实现提供了一个线程安全的对象,可以在生产者-消费者场景中用作缓冲区。BlockingQueue
接口有5种不同的实现。使用其中一个LinkedBlockingQueue
来实现生产者-消费者。如下所示。
class ProducerConsumer { public static void main(String[] args)
BlockingQueue buffer = new LinkedBlockingQueue();
Producer p = new Producer(buffer);
Consumer c = new Consumer(buffer); new Thread(p).start(); new Thread(c).start();
}
}class Producer implements Runnable { private boolean active = true; private final BlockingQueue buffer; public Producer(BlockingQueue q) { buffer = q; } public void run() { try { while (active) { buffer.put(produce()); }
} catch (InterruptedException ex) { // handle exception}
} Object produce() { // details omitted, sets active=false }
} class Consumer implements Runnable { private boolean active = true;
private final BlockingQueue buffer; public Consumer(BlockingQueue q) { buffer = q; } public void run() { try { while (active) { consume(buffer.take()); }
} catch (InterruptedException ex) { // handle exception }
} void consume(Object x) { // details omitted, sets active=false }
}
这种解决方案使程序员不必操心如何协调对共享缓冲区的访问,并极大地简化了代码。
许多多线程系统需要创建和管理执行类似任务的线程集合。例如,在生产者-消费者问题中,我们可以有一个生产者线程集合和一个消费者线程集合,同时添加和删除项,并协调地访问共享缓冲区。
这些集合称为线程池。线程池由几个工作线程组成,这些工作线程通常执行类似的目的,并作为一个集合进行管理。我们可以创建一个生产者线程池,所有这些线程都等待一个项目处理,将最终产品写入缓冲区,然后等待接受另一个项目处理。当我们停止生成项时,池可以以安全的方式关闭,这样就不会因为意外的异常而丢失部分处理的项。
在java.util.concurrent
包中,execuorservice
接口支持线程池。这将使用一组方法扩展基本Executor
接口,以管理和终止池中的线程。以下示例中显示了使用固定大小线程池的简单生产者-消费者示例。生产者类是一个Runnable
,它向缓冲区发送一条消息,然后终止。Consumer
只是从缓冲区获取消息,直到接收到空字符串,然后终止。
class Producer implements Runnable { private final BlockingQueue buffer; public Producer(BlockingQueue q) { buffer = q; } @Override
public void run() { try {
sleep(1000);
buffer.put("hello world");
} catch (InterruptedException ex) { // handle exception
}
}
}class Consumer implements Runnable { private final BlockingQueue buffer; public Consumer(BlockingQueue q) { buffer = q; } @Override
public void run() { boolean active = true; while (active) { try {
String s = (String) buffer.take();
System.out.println(s); if (s.equals("")) active = false;
} catch (InterruptedException ex) {
handle exception
}
}
System.out.println("Consumer terminating");
}
}
我们创建一个单一的消费者从缓冲区获取消息。然后我们创建一个大小为5的固定线程池来管理我们的生产者。这导致JVM预分配5个线程,这些线程可用于执行池所执行的任何Runnable
对象。
在for()
循环中,我们使用ExecutorService
运行20个生产者。由于线程池中只有5个线程可用,因此最多只能同时执行5个生产者。其他所有线程都被放置在一个由线程池管理的等待队列中。当一个生成程序终止时,等待队列中的下一个Runnable
将使用池中的任何可用线程执行。
一旦我们请求线程池执行所有的生产者,我们就在线程池上调用shutdown()
方法。这告诉ExecutorService
不要再接受任何运行的任务。接下来,我们调用awaitterminate()
方法,该方法将阻塞调用线程,直到线程池管理的所有线程都处于空闲状态,并且等待队列中不再有工作等待。一旦awaitterminate()
返回,我们就知道所有消息都已经发送到缓冲区,因此向缓冲区发送一个空字符串,该字符串将作为消费者的终止值。
public static void main(String[] args) throws InterruptedException
{
BlockingQueue buffer = new LinkedBlockingQueue(); //start a single consumer
(new Thread(new Consumer(buffer))).start();
ExecutorService producerPool = Executors.newFixedThreadPool(5); for (int i = 0; i <20; i++)
{
Producer producer = new Producer(buffer) ;
System.out.println("Producer created" );
producerPool.execute(producer);
}
producerPool.shutdown();
producerPool.awaitTermination(10, TimeUnit.SECONDS); //send termination message to consumer
buffer.put("");
}
Executor
框架中有许多更复杂的特性,可以用来创建多线程程序。线程池很重要,因为它们使我们的系统能够合理地使用线程资源。每个线程都会消耗内存,例如,线程的堆栈大小通常在1MB左右。此外,当我们切换执行上下文以运行一个新线程时,这将消耗CPU周期。如果我们的系统以不规范的方式创建线程,我们最终将耗尽内存,系统将崩溃。线程池允许我们控制我们创建的线程的数量,并有效地利用它们。
线程是我们用来构建可伸缩分布式系统的数据处理和数据库平台的固有组件。在许多情况下,你可能不会显式地编写多线程代码。但是,你编写的代码将在多线程环境中调用,这意味着你需要注意线程安全。许多平台还通过配置参数公开它们的并发性,这意味着要调优系统的性能,你需要了解更改各种线程和线程池设置的影响。基本上,在可伸缩的分布式系统中,并发是不可避免的。
虽然并发编程原语在不同的编程语言中有所不同,但基本问题是不变的,需要仔细设计多线程代码以避免竞争条件和死锁。无论你是使用c/c++中的pthreads库,还是经典的受CSP启发的Go并发模型,你需要避免的问题都是相同的。








 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有