小测试
想必在日常生活中,我们总会有一种感觉,身边认识的一些人,明明没有任何血缘关系,但是长得却可能很像,尤其对于脸盲的同学,真的是傻傻分不清楚。
我们这里有一组题,来测测大家的人脸识别水平。
先来一道简单的,【人脸识别四级】水平的,下面两位男明星分别是谁?

很简单是吧?
答案应该不需要公布了
应该难不倒大家
趁热打铁,我们再来一道【人脸识别六级】的,下面两位女明星分别是谁?

估计已经有一部分人答不出来了
当然很可能原因是
你不认识左边的是谁
答案在这里也不公布了,感兴趣的可以试一下我们的百度识图:http://image.baidu.com/?fr=shitu,一定可以告诉你满意的答案。
有的读者肯定觉得,答出以上两题很easy啊,好吧,下一题。
我们的压轴【人脸识别八级】来了!
不定项选择题
下面的9张照片中,假设从左到右,按顺序依次是1-3,4-6,7-9,那么,和2号照片同一个人的是几号?()
A、3号 B、4号 C、5号 D、9号

公布答案
没有!
上面的9张照片是9个人!!
一点也不意外是不是?
是的
在某些特殊情况下,人脸识别对于人类已经快成为Impossible mission了。
度量学习的引入
随着人脸识别技术逐渐在身份核验中承担越来越重要的作用,门禁准入,机场安检,金融服务等等领域都对于准确性提出了高要求,如何更精确的区分样本的特征也成为人脸识别技术的巨大挑战。
2002年,Eric Xing在NIPS2002提出度量学习 (Metric Learning)的概念。其中度量在数学中的定义为:一个度量(或距离函数)是一个定义集合中元素之间距离的函数。一个具有度量的集合被称为度量空间。常见的度量算法如下表所示。
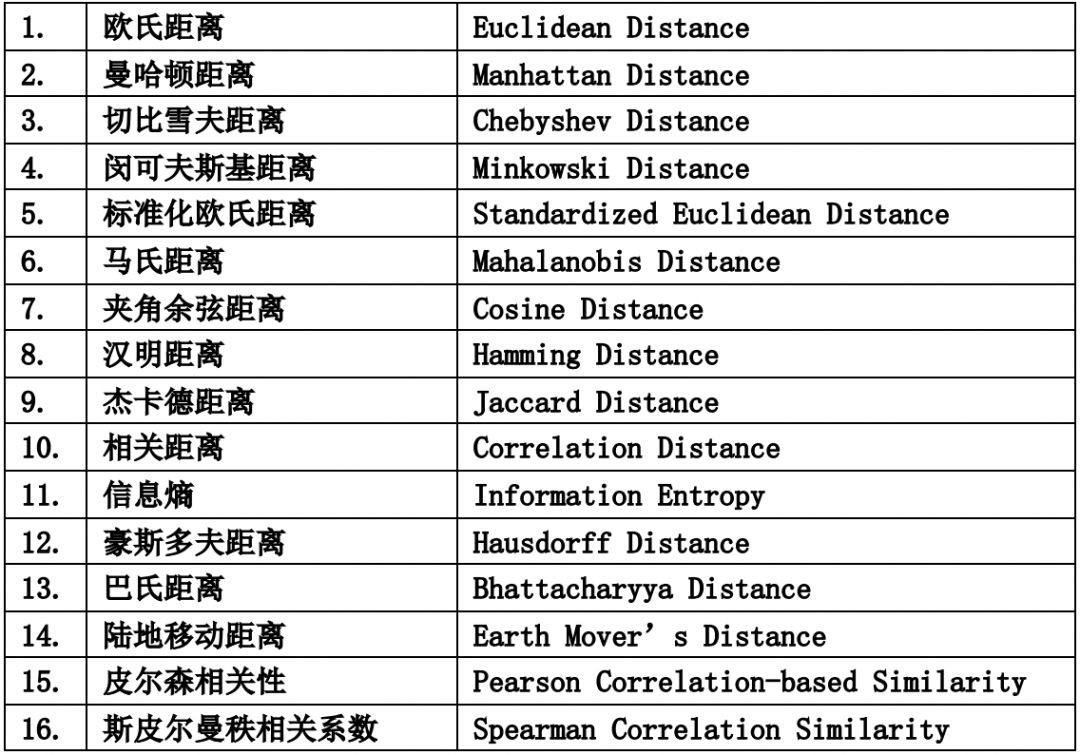
度量学习目的是在特征空间中,让同一个类别的样本具有较小的特征距离,不同类的样本具有较大的特征距离。算法越来越依赖于在输入空间给定的好的度量。
假设我们需要计算图像之间的相似度(或距离),例如识别人脸时,我们需要构建一个距离函数去强化合适的特征(如脸型,五官等);而如果我们想识别姿势,就需要构建一个捕获姿势相似度的距离函数(如关节,动作)。为了处理各种各样的特征相似度,我们需要在特定的任务选择合适的特征并手动构建距离函数。这种方法会需要很大的人工投入,也可能对数据的改变非常不鲁棒。
度量学习作为一个理想的替代,可以根据不同的任务来自主学习出针对某个特定任务的度量距离函数。随着深度学习技术的发展,基于深度神经网络的度量学习方法极大的推动了人脸识别、人脸校验、行人重识别和图像检索等众多计算机视觉任务的性能提升。
飞桨的深度度量学习实现
在本章节,我们将为大家介绍在飞桨里实现的几种度量学习方法和使用方法,具体包括数据准备,模型训练,模型微调,模型评估,模型预测。
安装与依赖
运行本章节代码需要在Paddle Fluid v0.14.0 或更高的版本环境。如果你的设备上的Paddle Fluid版本低于v0.14.0,请及时安装和更新。
数据准备
Stanford Online Product(SOP) 数据集下载自eBay,包含120053张商品图片,有22634个类别。我们使用该数据集进行实验。训练时,使用59551张图片,11318个类别的数据;测试时,使用60502张图片,11316个类别。
SOP数据集的ftp网址:
ftp://cs.stanford.edu/cs/cvgl/Stanford_Online_Products.zip。
如果下载速度太慢,也可以到百度AI Studio公开数据集里面下载:
https://aistudio.baidu.com/aistudio/datasetDetail/5103
模型训练
为了训练度量学习模型,首先,我们需要选择一个神经网络模型作为骨架模型(例如ResNet50),其次,我们选择一个代价函数来进行训练(例如softmax 或者 arcmargin)。举例如下:
python train_elem.py \--model=ResNet50 \--train_batch_size=256 \--test_batch_size=50 \--lr=0.01 \--total_iter_num=30000 \--use_gpu=True \--pretrained_model=${path_to_pretrain_imagenet_model} \--model_save_dir=${output_model_path} \--loss_name=arcmargin \--arc_scale=80.0 \ --arc_margin=0.15 \--arc_easy_margin=False
其中,参数介绍:
model: 使用的模型名字. 默认:"ResNet50".
train_batch_size: 训练的 mini-batch大小. 默认: 256.
test_batch_size: 测试的 mini-batch大小. 默认: 50.
lr: 初始学习率. 默认:0.01.
total_iter_num: 总的训练迭代轮数. 默认:30000.
use_gpu: 是否使用GPU. 默认:True.
pretrained_model: 预训练模型的路径. 默认:None.
model_save_dir: 保存模型的路径. 默认:"output".
loss_name: 优化的代价函数. 默认:"softmax".
arc_scale: arcmargin的参数. 默认: 80.0.
arc_margin:arcmargin的参数. 默认: 0.15.
arc_easy_margin: arcmargin的参数. 默认: False.
模型微调
模型微调是在指定的任务上加载已有的模型来微调网络。在用softmax和arcmargin训完网络后,可以继续使用triplet,quadruplet或eml来微调网络。下面是一个使用eml来微调网络的例子:
python train_pair.py \--model=ResNet50 \--train_batch_size=160 \--test_batch_size=50 \--lr=0.0001 \--total_iter_num=100000 \--use_gpu=True \--pretrained_model=${path_to_pretrain_arcmargin_model} \--model_save_dir=${output_model_path} \--loss_name=eml \--samples_each_class=2
其中,参数介绍同训练过程一致。
模型评估
模型评估主要是评估模型的检索性能。这里需要设置path_to_pretrain_model。可以使用下面命令来计算Recall@Rank-1。
python eval.py \--model=ResNet50 \--batch_size=50 \--pretrained_model=${path_to_pretrain_model} \
模型预测
模型预测主要是基于训练好的网络来获取图像数据的特征,举例如下:
python infer.py \--model=ResNet50 \--batch_size=1 \ --pretrained_model=${path_to_pretrain_model}
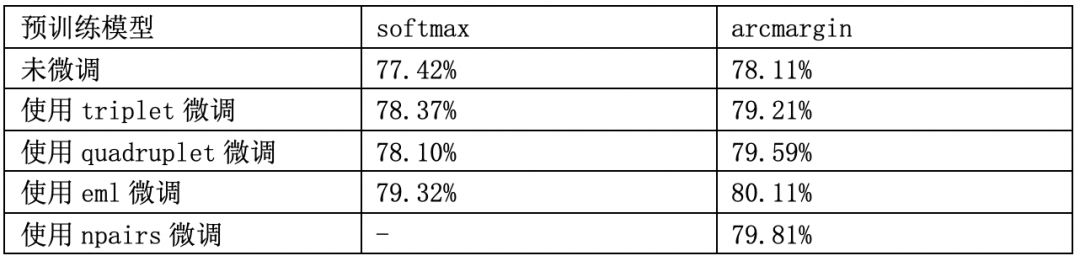
模型性能
下面列举了几种度量学习的代价函数在SOP数据集上的检索效果,这里使用Recall@Rank-1来进行评估。
更多详细内容可以参见:
https://github.com/PaddlePaddle/models/tree/v1.4/PaddleCV/metric_learning








 京公网安备 11010802041100号
京公网安备 11010802041100号