▼ 关注「Apache Flink」,获取更多技术干货 ▼
第一部分
01
简介
Flink 可以同时支持有限数据集和无限数据集的分布式处理。在最近几个版本中,Flink 逐步实现了流批一体的 DataStream API 与 Table SQL API。大部分用户都同时有流处理与批处理的需求,流批一体的开发接口可以帮助这些用户减小开发、运维与保证两类作业处理结果一致性等方面的复杂度, 例如阿里巴巴双十一的场景[1] 。
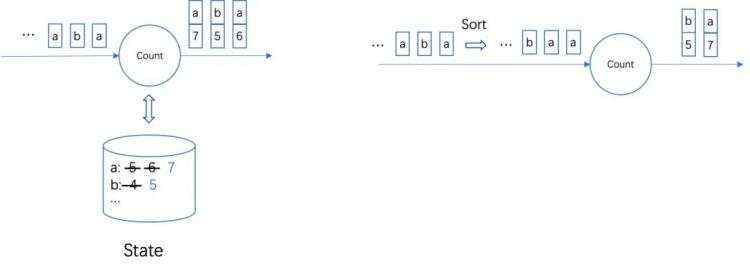
02
支持包含结束任务的 Checkpoint
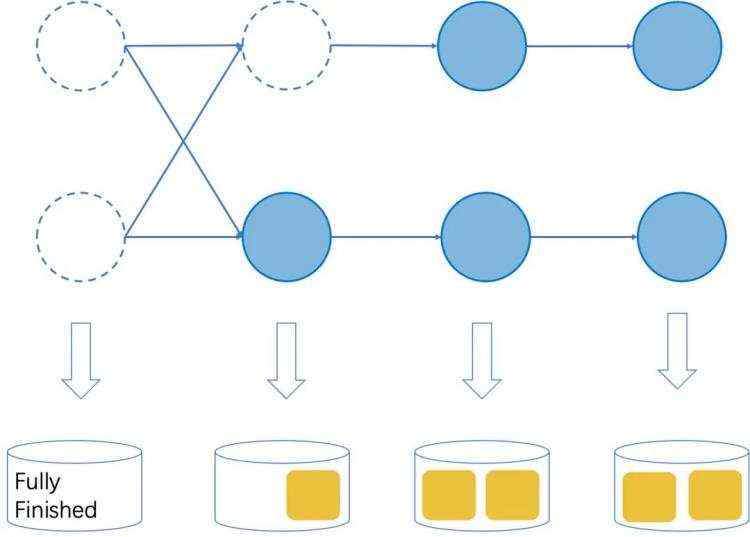
03
修正作业结束的流程

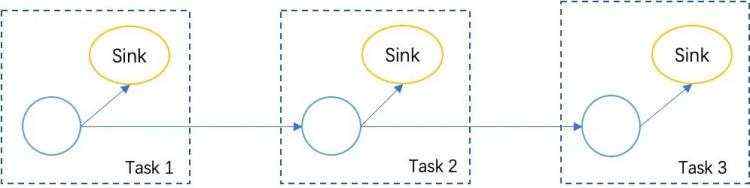
04
包含结束任务的 Checkpoint 实现
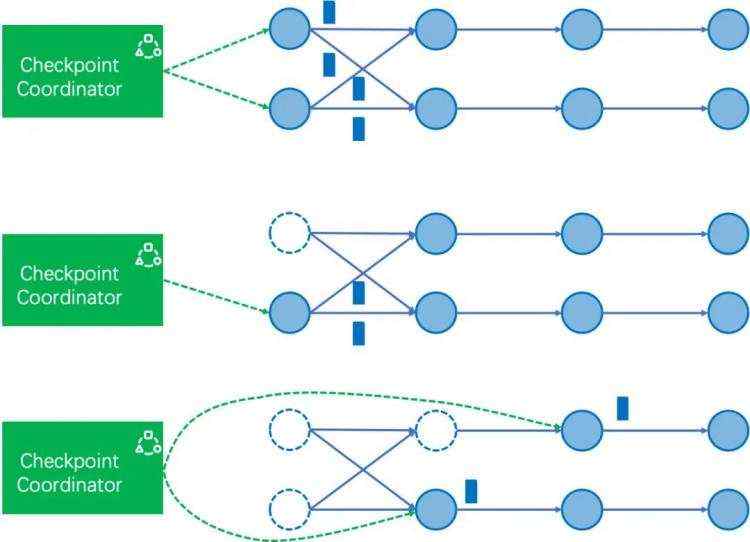
05
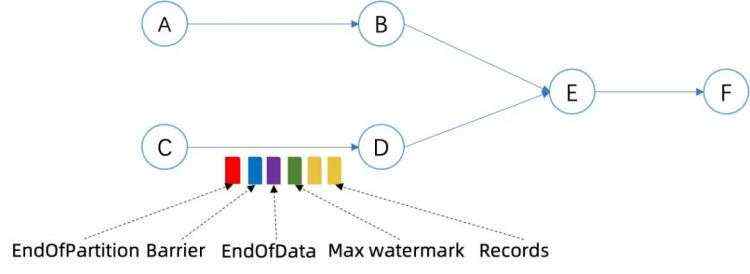
修正后的作业结束流程
MAX_WATERMARKLong.MAX_VALUE1. Source operators emit MAX_WATERMARK
2. On received MAX_WATERMARK for non-source operators
a. Trigger all the event-time timers
b. Emit MAX_WATERMARK
3. Source tasks finished
a. endInput(inputId) for all the operators
b. close() for all the operators
c. dispose() for all the operators
d. Emit EndOfPartitionEvent
e. Task cleanup
4. On received EndOfPartitionEvent for non-source tasks
a. endInput(int inputId) for all the operators
b. close() for all the operators
c. dispose() for all the operators
d. Emit EndOfPartitionEvent
e. Task cleanup
1. Trigger a savepoint
2. Sources received savepoint trigger RPC
a. If with –-drain
i. source operators emit MAX_WATERMARK
b. Source emits savepoint barrier
3. On received MAX_WATERMARK for non-source operators
a. Trigger all the event times
b. Emit MAX_WATERMARK
4. On received savepoint barrier for non-source operators
a. The task blocks till the savepoint succeed
5. Finish the source tasks actively
a. If with –-drain
ii. endInput(inputId) for all the operators
b. close() for all the operators
c. dispose() for all the operators
d. Emit EndOfPartitionEvent
e. Task cleanup
6. On received EndOfPartitionEvent for non-source tasks
a. If with –-drain
i. endInput(int inputId) for all the operators
b. close() for all the operators
c. dispose() for all the operators
d. Emit EndOfPartitionEvent
e. Task cleanup
1. Source tasks finished due to no more records or stop-with-savepoint.
a. if no more records or stop-with-savepoint –-drain
i. source operators emit MAX_WATERMARK
ii. endInput(inputId) for all the operators
iii. finish() for all the operators
iv. emit EndOfData[isDrain = true] event
b. else if stop-with-savepoint
i. emit EndOfData[isDrain = false] event
c. Wait for the next checkpoint the savepoint after operator finished complete
d. close() for all the operators
e. Emit EndOfPartitionEvent
f. Task cleanup
2. On received MAX_WATERMARK for non-source operators
a. Trigger all the event times
b. Emit MAX_WATERMARK
3. On received EndOfData for non-source tasks
a. If isDrain
i. endInput(int inputId) for all the operators
ii. finish() for all the operators
b. Emit EndOfData[isDrain = the flag value of the received event]
4. On received EndOfPartitionEvent for non-source tasks
a. Wait for the next checkpoint the savepoint after operator finished complete
b. close() for all the operators
c. Emit EndOfPartitionEvent
d. Task cleanup
06
结论
往期精选





 点击「阅读原文」,查看Flink中文学习网
点击「阅读原文」,查看Flink中文学习网




 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有