总结先根遍历得到的非递归算法思想如下:
1)入栈,主要是先头结点入栈,然后visit此结点
2)while,循环遍历当前结点,直至左孩子没有结点
3)if结点的右孩子为真,转入1)继续遍历,否则退出当前结点转入父母结点遍历转入1)
先看符合此思想的算法:
代码如下:
int PreOrderTraverseNonRecursiveEx(const BiTree &T, int (*VisitNode)(TElemType data))
{
if (T == NULL)
{
return -1;
}
BiTNode *pBiNode = T;
SqStack S;
InitStack(&S);
Push(&S, (SElemType)T);
while (!IsStackEmpty(S))
{
while (pBiNode)
{
VisitNode(pBiNode->data);
if (pBiNode != T)
{
Push(&S, (SElemType)pBiNode);
}
pBiNode = pBiNode->lchild;
}
if(pBiNode == NULL)
{
Pop(&S, (SElemType*)&pBiNode);
}
if ( pBiNode->rchild == NULL)
{
Pop(&S, (SElemType*)&pBiNode); //如果此时栈已空,就有问题
}
pBiNode = pBiNode->rchild;
}
return 0;
}
注意:1)这里使用了栈结构,可参看上文顺序结构存储的栈
2)这里在保存结点的时候,我保存的是指针也就是结点的地址,将其变为int型存储,在pop的时候里面使用的是指针,所以取的是&pBiNode,而不是pBiNode,为什么请自行思考指针的使用,最好理解的就是BiTNode *pBiNode;定义改为BiTree pBiNode就很好理解了。
上面这个算法其实是错误的!为什么呢? 这里我检查好久,期间出现还出现过无限循环,也出现过从左子树退出后右边子树不显示,最后我修改了第一个while判断条件,为什么呢?因为如果在pop之后,栈已空但是右子树还有,就无法继续了,这个在我写出后并没有进行太多验证,后面再阐述,这里并没有压入null指针,看一下压入空指针的例子,主要是左子树为空的时候才压入栈的,如下:
代码如下:
int PreOrderTraverseNonRecursive(const BiTree &T, int (*VisitNode)(TElemType data))
{
if (T == NULL)
{
return -1;
}
BiTNode *pBiNode = T;
SqStack S;
InitStack(&S);
Push(&S, (SElemType)T);
while (!IsStackEmpty(S))
{
GetTop(S, (SElemType*)&pBiNode);
while (pBiNode)
{
VisitNode(pBiNode->data);
pBiNode = pBiNode->lchild;
Push(&S, (SElemType)pBiNode);
}
if(pBiNode == NULL)
{
Pop(&S, (SElemType*)&pBiNode);
}
if ( !IsStackEmpty(S))
{
Pop(&S, (SElemType*)&pBiNode);
pBiNode = pBiNode->rchild;
Push(&S, (SElemType)pBiNode);
}
}
return 0;
}
这里是这样的,先压入根节点,然后判断左子树是否为空,不为空就压入栈,否则退出while循环之后就将NULL结点出栈,再判断当前栈是否为空,如果非空就出栈得到父节点然后判断右孩子,压入右孩子结点,再判断此右子树的左孩子是否为空,继续循环。
这里有两个浪费的地方:一个就是压入空孩子结点入栈,二就是频繁使用GetTop获得栈顶元素
这里返回过来再看初开始设计的算法,那里正好没有压入NULL指针或者说空的孩子结点,但是并不能输出完整,这里我们想到可以在判断栈的时候加入,当前的结点是否为NULL就可以了,这样就不会出现不会显示退出左子树结点不能显示右子树结点的尴尬了,如下:
代码如下:
//非递归先序遍历二叉树
int PreOrderTraverseNonRecursiveEx(const BiTree &T,
int (*VisitNode)(TElemType data))
{
if (T == NULL)
{
return -1;
}
BiTNode *pBiNode = T;
SqStack S;
InitStack(&S);
Push(&S, (SElemType)T);
while ( !IsStackEmpty(S) || pBiNode) //主要修改的就是这句
{
while (pBiNode)
{
VisitNode(pBiNode->data);
if (pBiNode != T)
{
Push(&S, (SElemType)pBiNode);
}
pBiNode = pBiNode->lchild;
}
if(pBiNode == NULL)
{
Pop(&S, (SElemType*)&pBiNode);
}
if ( pBiNode->rchild == NULL)
{
Pop(&S, (SElemType*)&pBiNode); //如果此时栈已空,就有问题
}
pBiNode = pBiNode->rchild;
}
return 0;
}
在第一个while循环加入这个之后,就可以了,测试用例与二叉树先序遍历类似。如下测试上节的二叉树例子:
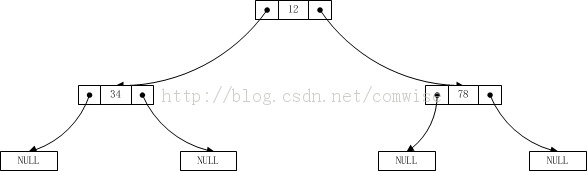
此时输入的数据仍然还是 12 34 0 0 78 0 0,测试结果如下:
--- BiTree ---
Please Enter BiTree Node data:
12
Please Enter BiTree Node data:
34
Please Enter BiTree Node data:
0
Please Enter BiTree Node data:
0
Please Enter BiTree Node data:
78
Please Enter BiTree Node data:
0
Please Enter BiTree Node data:
0
12 34 78
这个还不足以测试,再看如下的二叉树
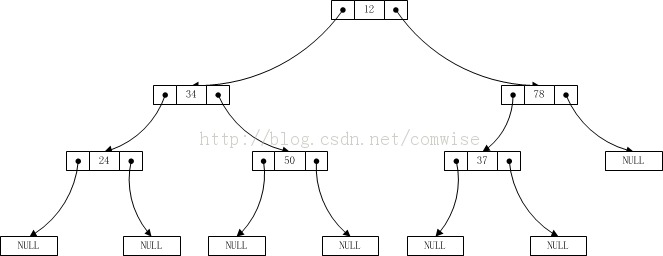
此时输入数据应该为:12 34 24 0 0 50 0 0 78 37 0 0 0,测试结果如下:
--- BiTree ---
Please Enter BiTree Node data:
12
Please Enter BiTree Node data:
34
Please Enter BiTree Node data:
24
Please Enter BiTree Node data:
0
Please Enter BiTree Node data:
0
Please Enter BiTree Node data:
50
Please Enter BiTree Node data:
0
Please Enter BiTree Node data:
0
Please Enter BiTree Node data:
78
Please Enter BiTree Node data:
37
Please Enter BiTree Node data:
0
Please Enter BiTree Node data:
0
Please Enter BiTree Node data:
0
12 34 24 50 78 37
由先序遍历可知,正好是正确的,另外这些算法不光是对先序遍历的,如果想变为中序或者后序,只需将上面算法中的visit之类的先去掉,然后将它加入合适的位置,就可以了






 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有 