作者:DD906114329 | 来源:互联网 | 2023-02-02 11:22
Elasticsearch在2.x版本的时候把filter查询给摘掉了,因此在query dsl里面已经找不到filter query了。其实es并没有完全抛弃filter query,而是它的设计与之前的query太重复了。因此直接给转移到了bool查询中。
Bool查询现在包括四种子句,must,filter,should,must_not。
为什么filter会快?
#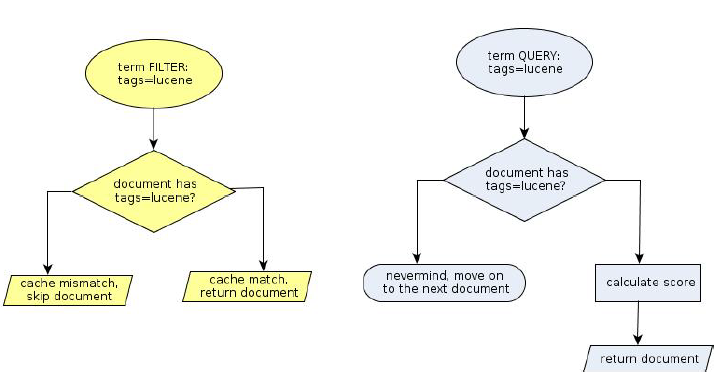
看上面的流程图就能很明显的看到,filter与query还是有很大的区别的。
比如,query的时候,会先比较查询条件,然后计算分值,最后返回文档结果;
而filter则是先判断是否满足查询条件,如果不满足,会缓存查询过程(记录该文档不满足结果);满足的话,就直接缓存结果。
综上所述,filter快在两个方面:
bool查询的使用
Bool查询对应Lucene中的BooleanQuery,它由一个或者多个子句组成,每个子句都有特定的类型。
must
返回的文档必须满足must子句的条件,并且参与计算分值
filter
返回的文档必须满足filter子句的条件。但是不会像Must一样,参与计算分值
should
返回的文档可能满足should子句的条件。在一个Bool查询中,如果没有must或者filter,有一个或者多个should子句,那么只要满足一个就可以返回。minimum_should_match参数定义了至少满足几个子句。
must_nout
返回的文档必须不满足must_not定义的条件。
如果一个查询既有filter又有should,那么至少包含一个should子句。
bool查询也支持禁用协同计分选项disable_coord。一般计算分值的因素取决于所有的查询条件。
bool查询也是采用more_matches_is_better的机制,因此满足must和should子句的文档将会合并起来计算分值。
{
"bool" : {
"must" : {
"term" : { "user" : "kimchy" }
},
"filter": {
"term" : { "tag" : "tech" }
},
"must_not" : {
"range" : {
"age" : { "from" : 10, "to" : 20 }
}
},
"should" : [
{
"term" : { "tag" : "wow" }
},
{
"term" : { "tag" : "elasticsearch" }
}
],
"minimum_should_match" : 1,
"boost" : 1.0
}
}
bool.filter的分值计算
在filter子句查询中,分值将会都返回0。分值会受特定的查询影响。
比如,下面三个查询中都是返回所有status字段为active的文档
第一个查询,所有的文档都会返回0:
GET _search
{
"query": {
"bool": {
"filter": {
"term": {
"status": "active"
}
}
}
}
}
下面的bool查询中包含了一个match_all,因此所有的文档都会返回1
GET _search
{
"query": {
"bool": {
"must": {
"match_all": {}
},
"filter": {
"term": {
"status": "active"
}
}
}
}
}
constant_score与上面的查询结果相同,也会给每个文档返回1:
GET _search
{
"query": {
"constant_score": {
"filter": {
"term": {
"status": "active"
}
}
}
}
}
使用named query给子句添加标记
如果想知道到底是bool里面哪个条件匹配,可以使用named query查询:
{
"bool" : {
"should" : [
{"match" : { "name.first" : {"query" : "shay", "_name" : "first"} }},
{"match" : { "name.last" : {"query" : "banon", "_name" : "last"} }}
],
"filter" : {
"terms" : {
"name.last" : ["banon", "kimchy"],
"_name" : "test"
}
}
}
}
ElasticSearch 最新版本 2.20 发布下载了 2016-02/128166.htm
Linux上安装部署ElasticSearch全程记录 2015-09/123241.htm
Elasticsearch安装使用教程 2015-02/113615.htm
ElasticSearch 配置文件译文解析 2015-02/114244.htm
ElasticSearch集群搭建实例 2015-02/114243.htm
分布式搜索ElasticSearch单机与服务器环境搭建 2012-05/60787.htm
ElasticSearch的工作机制 2014-11/109922.htm
Elasticsearch的安装,运行和基本配置 2016-07/133057.htm
使用Elasticsearch + Logstash + Kibana搭建日志集中分析平台实践 2015-12/126587.htm
Ubuntu 14.04搭建ELK日志分析系统(Elasticsearch+Logstash+Kibana) 2016-06/132618.htm
Elasticsearch1.7升级到2.3实践总结 2016-11/137282.htm
ElasticSearch 的详细介绍:请点这里
ElasticSearch 的下载地址:请点这里






 京公网安备 11010802041100号
京公网安备 11010802041100号