什么是ElasticSearch
Elasticsearch是一个基于Lucene的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。Elasticsearch是用Java语言开发的,并作为Apache许可条款下的开放源码发布,是一种流行的企业级搜索引擎。Elasticsearch用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。官方客户端在Java、.NET(C#)、PHP、Python、Apache Groovy、Ruby和许多其他语言中都是可用的。根据DB-Engines的排名显示,Elasticsearch是最受欢迎的企业搜索引擎,其次是Apache Solr,也是基于Lucene。
简单来说:就是用于做全文搜索,结构化搜索,分析使用;
1.ElasticSearch的安装
注意:对于java的JDK要求,最低也得1.8
点击进入es官网地址下载
IK分词器下载
Kibana华为云镜像下载
1.1ES的启动
- 启动成功,出现
127.0.0.1/9200

- 访问一下呗~

2.安装ES的可视化界面:es-head
点击获取es-head的下载地址
注意:在windows下,安装head插件需要NodeJS的环境;
在head插件中,输入cmd打开终端窗口,输入npm run start 启动前端项目

- 打开页面,发现已经启动好了head插件

注意:第一次启动head插件的时候可能会出现跨域错误,改如何解决:
打开es->找到config文件夹->打开elasticsearch.yml->配置下图内容即可:

2.1利用head插件创建一个索引
对于初学:我自己的建议是把es看做一张数据库表就可以了,然后可以在数据库中创建表等一些操作.

3.kibana的安装
3.1kibana的介绍
Kibana是一个开源的分析与可视化平台,设计出来用于和Elasticsearch一起使用的。你可以用kibana搜索、查看存放在Elasticsearch中的数据。Kibana与Elasticsearch的交互方式是各种不同的图表、表格、地图等,直观的展示数据,从而达到高级的数据分析与可视化的目的。
Elasticsearch、Logstash和Kibana这三个技术就是我们常说的ELK技术栈,可以说这三个技术的组合是大数据领域中一个很巧妙的设计。一种很典型的MVC思想,模型持久层,视图层和控制层。Logstash担任控制层的角色,负责搜集和过滤数据。Elasticsearch担任数据持久层的角色,负责储存数据。而我们这章的主题Kibana担任视图层角色,拥有各种维度的查询和分析,并使用图形化的界面展示存放在Elasticsearch中的数据。
作者:叩丁狼教育
链接:https://www.jianshu.com/p/8001ac47c378
来源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
简单来说:就是用于es的可视化平台,用来搜索,查看交互存储在es中的索引数据.
下载地址:kibana对应的华为云的镜像地址
直接点击启动即可:




4.ES核心概念
记住一个观点:ES是面向文档
关系型数据和ES的比较:
| 关系型数据库 | ElaticSearch |
|---|
| 数据库 | 索引(index) |
| 表 | 类型 |
| 行 | 文档 |
| 字段 | 属性名称 |
elasticsearch(集群)中可以包含多个索引(数据库),每个索引中可以包含多个类型(表),每个类型下又包含多个文档(行),每个文档中又包含多个字段(列)。
物理设计:
es把后台的索引分片成多个,每片分片可以在集群的不同的服务器迁移;
就算es只有一台,那么对于它自己而言,它一个就是集群;
文档–>(一条数据)
之前说elasticsearch是面向文档的,那么就意味着索引和搜索数据的最小单位是文档,elasticsearch中,文档有几个重要属性:
自我包含,一篇文档同时包含字段和对应的值,也就是同时包含key:value !
可以是层次型的,一个文档中包含自文档,复杂的逻辑实体就是这么来的! {就是一个json对象 ! fastjson进行自动转换 !}
灵活的结构,文档不依赖预先定义的模式,我们知道关系型数据库中,要提前定义字段才能使用,在elasticsearch中,对于字段是非常灵活的,有时候,我们可以忽略该字段,或者动态的添加一个新的字段。
类型—>(一张表)
类型是文档的逻辑容器,就像关系型数据库一样,表格是行的容器。类型中对于字段的定义称为映射,比如name映射为字符串类型。我们说文档是无模式的,它们不需要拥有映射中所定义的所有字段,比如新增一个字段,那么elasticsearch是怎么做的呢?
elasticsearch会自动的将新字段加入映射,但是这个字段的不确定它是什么类型,elasticsearch就开始猜,如果这个值是18,那么elasticsearch会认为它是整形。但是elasticsearch也可能猜不对,所以最安全的方式就是提前定义好所需要的映射,这点跟关系型数据库殊途同归了,先定义好字段,然后再使用,别整什么幺蛾子。
索引–>(相当于一个数据库,里面可以有很多表)
索引是映射类型的容器, elasticsearch中的索引是一个非常大的文档集合。 索引存储了映射类型的字段和其他设置。然后它们被存储到了各个分片上了。我们来研究下分片是如何工作的。
5.ES的倒排索引
简单说就是 按&#xff08;文章关键字&#xff0c;对应的文档<0个或多个>&#xff09;形式建立索引&#xff0c;根据关键字就可直接查询对应的文档&#xff08;含关键字的&#xff09;&#xff0c;无需查询每一个文档&#xff0c;如下图
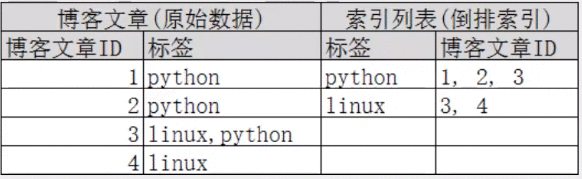 比如说我们去查询有python的数据&#xff0c;
比如说我们去查询有python的数据&#xff0c;我们可以不再根据id一个个来查询标签&#xff0c;而是直接找到标签所对应的文章id即可&#xff0c;完全过滤掉无关的数据&#xff0c;提高查询效率。
6.IK分词器(elasticsearch插件)
可以理解为&#xff1a;中文分词器
6.1 IK分词器有什么用呢?
分词&#xff1a;即把一段中文或者别的划分成一个个的关键字&#xff0c;我们在搜索时候会把自己的信息进行分词&#xff0c;会把数据库中或者索引库中的数据进行分词&#xff0c;然后进行一一个匹配操作&#xff0c;默认的中文分词是将每个字看成一个词&#xff08;不使用用IK分词器的情况下&#xff09;&#xff0c;比如“我爱中国”会被分为”我”&#xff0c;”爱”&#xff0c;”狂”&#xff0c;”神” &#xff0c;这显然是不符合要求的&#xff0c;所以我们需要安装中文分词器ik来解决这个问题。
6.2 下载地址:
https://github.com/medcl/elasticsearch-analysis-ik/releases
6.3如何使用
1.下载完毕后&#xff0c;放入es的plugins目录下
 2.然后&#xff0c;重启我们的es;
2.然后&#xff0c;重启我们的es;
3.测试:
1.ik_smart&#xff1a;最少切分&#xff08;意思是:尽量组成词语&#xff0c;少做切分&#xff09;

2.ik_max_word&#xff1a;最细粒度划分&#xff08;穷尽词库的可能&#xff0c;尽量组成词语&#xff0c;多做切分&#xff0c;提高查询的可能性&#xff09;
 3.从上面看&#xff0c;感觉分词都比较正常&#xff0c;但是大多数&#xff0c;分词都满足不了我们的想法&#xff0c;如下例
3.从上面看&#xff0c;感觉分词都比较正常&#xff0c;但是大多数&#xff0c;分词都满足不了我们的想法&#xff0c;如下例
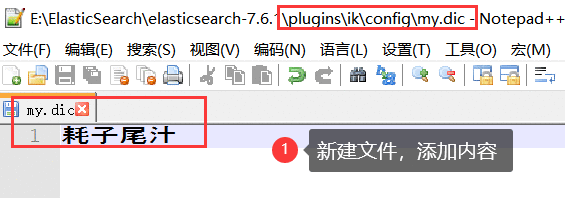
 那么&#xff0c;我们需要手动将该词添加到分词器的词典当中
那么&#xff0c;我们需要手动将该词添加到分词器的词典当中












 京公网安备 11010802041100号
京公网安备 11010802041100号