作者:mobiledu2502863483 | 来源:互联网 | 2023-05-29 09:02
ElasticSearch 是一个基于 Lucene 的高度可扩展的开源全文搜索和分析引擎。它能够做到可以快速、实时地存储、搜索和分析大量数据。它通常作为底层引擎/技术,为具有复杂搜索功能和要求的应用程序提供支持。
笔者在大学期间试着搭建过 ES 集群,当时也仅限于尝试着搭建玩玩。现在开始,想要去系统地学习和使用它。废话不多说,开始直接上手搭建工作。
首先,需要下载 ElasticSearch 安装包。我在系统中已经搭建好的是 ES 5.2.2 版本的,下载链接:https://www.elastic.co/downloads/past-releases/elasticsearch-5-2-2。下载完成之后,可以通过解压命令解压(笔者下载的是 .tar.gz的包,直接 tar -xzvf xxx.tar.gz 解压即可)。解压之后如下图所示:
#
这时候,我们启动elasticsearch:
$ bin/elasticsearch
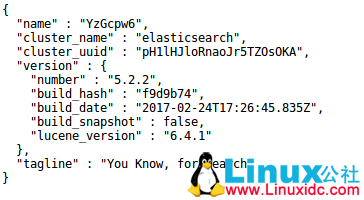
打开浏览器,输入: localhost:9200,这个时候,会输出下面的信息:
#
当然,你可以自行修改配置文件,配置文件:config/elasticsearch.yml。每个配置参数的字面意思也好理解,不再赘述。具体的参数是什么作用,也可以查询官网文档。
由于资源有限,目前我在本机只开了一个节点。接下来,我们需要下载 elasticsearch-head 插件。 ES 5.2.2 的插件不再集成在一起,我们需要下载下来,另起一个服务。
我们将代码克隆到本地:
$ git clone https://github.com/mobz/elasticsearch-head
#
这个时候,切换目录到 elasticsearch-head,运行 npm 指令:
$ npm install
注意,运行前,先要保证系统里面有 grunt 开发环境,笔者安装的时候,还出现了 node 版本问题导致的错误,建议安装最新的 node 版本。
如果安装过慢,可以通过代理来安装:
$ npm install cnpm --registry=https://registry.npm.taobao.org
指令执行完之后,可以启动服务:
$ grunt server
打开浏览器,将会看到:
#
可以发现,我们并没有连接上 ES。这个时候,需要我们去配置下elasticsearch.yml文件,在最后添加:
http.cors.enabled: true
http.cors.allow-origin: "*"
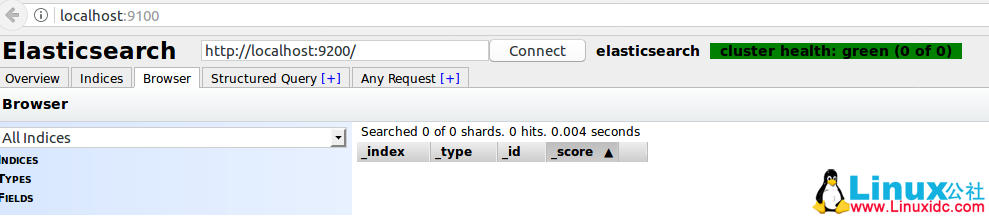
重启下elasticsearch,刷新下打开 elasticsearch-head 的页面,是不是发现变化成下面这样了?
#
这个时候,我们的 Elasticsearch 5.2.2 和 elasticsearch-head 插件就安装好了。have fun!
Linux上安装部署ElasticSearch全程记录 2015-09/123241.htm
Elasticsearch安装使用教程 2015-02/113615.htm
ElasticSearch 配置文件译文解析 2015-02/114244.htm
ElasticSearch集群搭建实例 2015-02/114243.htm
分布式搜索ElasticSearch单机与服务器环境搭建 2012-05/60787.htm
ElasticSearch的工作机制 2014-11/109922.htm
Elasticsearch的安装,运行和基本配置 2016-07/133057.htm
使用Elasticsearch + Logstash + Kibana搭建日志集中分析平台实践 2015-12/126587.htm
Ubuntu 14.04搭建ELK日志分析系统(Elasticsearch+Logstash+Kibana) 2016-06/132618.htm
Elasticsearch1.7升级到2.3实践总结 2016-11/137282.htm
Ubuntu 14.04中Elasticsearch集群配置 2017-01/139460.htm
Elasticsearch-5.0.0移植到Ubuntu 16.04 2017-01/139505.htm
ElasticSearch 的详细介绍:请点这里
ElasticSearch 的下载地址:请点这里










 京公网安备 11010802041100号
京公网安备 11010802041100号