转载自 https://www.cnblogs.com/SunHuaJ/p/7593239.html
ETL是EXTRACT(抽取)、TRANSFORM(转换)、LOAD(加载)的简称,实现数据从多个异构数据源加载到数据库或其他目标地址,是数据仓库建设和维护中的重要一环也是工作量较大的一块。当前知道的ETL工具有informatica, datastage,kettle,ETL Automation,sqoop,SSIS等等。这里我们聊聊kettle的学习吧(如果你有一定的kettle使用,推荐看看Pentaho Kettle解决方案,这里用kettle实践kimball的数据仓库理论。)。
内容有:认识kettle、安装kettle、简单入门实例、进阶实例、Linux中kettle部署、kettle发邮件、常见错误
认识kettle
kettle是纯java开发,开源的etl工具。可以在Linux、windows、unix中运行。有图形界面,也有命令脚本还可以二次开发。(官方社区:http://forums.pentaho.com/;官网wiki:http://wiki.pentaho.com/display/COM/Community+Wiki+Home;源码地址:https://github.com/pentaho/pentaho-kettle)
安装kettle
1、kettle是基于java开发的,所以需要java环境(下载jdk:http://www.oracle.com/technetwork/java/javase/downloads/jdk9-downloads-3848520.html)
2、kettle使用时,需要访问相关的关系型数据库,则需要下载对应的链接驱动。比如我们访问MySQL,则下载相应的驱动解压后放入kettle文件的lib目录下

3、下载kettle并解压到自定义位置。kettle其实是以前的叫法,现在官方称为:PDI(Pentaho Data Integeration)。在windows中,双击目录中的Spoon.bat启动kettle.

简单的kettle实例
1、新建作业/转换(功能区:文件 --> 新建 --> 作业;新建-->转换)
一个作业(job,文件以kjb结尾)的主体是转换(transform,以ktr结尾),job主要来设置调度,可以有影子拷贝,任一拷贝信息修改所有拷贝的都被修改;transform做主体的内容,控件名称唯一。
2、三个控件(start、转换、成功)和流程线(hop);
start:job开始的地方,可以设置开始的时间、频率、周期等(但要求kettle不能关闭,有点挫)
转换:后续详解
成功:job结束
流程线:关联两个控件(实体),指定数据流。同时还可以设置是否可用、分发模式、错误输出等;添加方式:按住shift进行鼠标拖动

3、转换的工作
新建的转换:job中需引用该转换文件
加入我们现在要同步MySQL中的一张表。在转换中要有输入和输出。
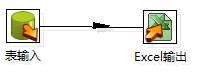
> 表输入:先配置链接(完成后测试一下是否OK),再输入查询sql(比如:select id from tab2 limit 10;)
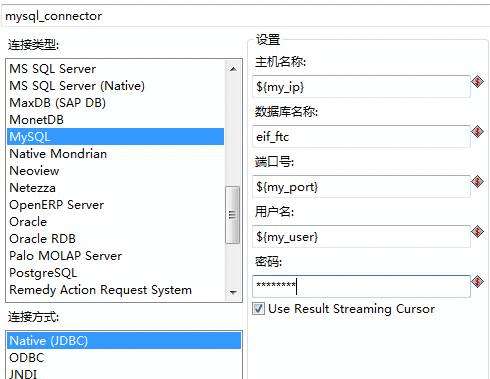
>excel输出。,指定输出路径
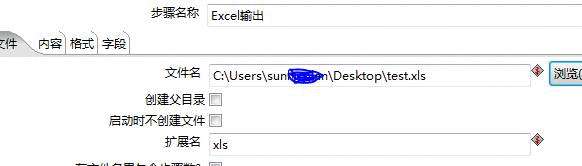
> 完成转换的配置后保存,在job中引用保存的文件。我们来跑一下吧~


> 完成,结束!
进阶实例:
百度上看到了一篇关于kettle的作业,但是没有详细的过程。这里以此说明,全图过程如下。
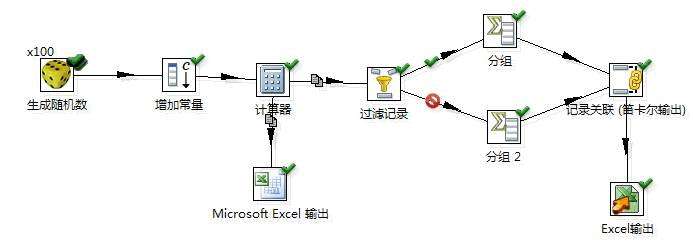
作业说明:生成 100 个随机数,随机数取值于[0,100)之间, 计算小于等于 50 的随机数个数和 大于50 的随机数个 数。 并把这两个统计数字放在数据库表的一行的两列中, 即输出的结果有一行,一行包括两列,每列是一个统 计值。
第一步:生成随机数(输入-->生成随机数;需要生成100个随机数,右击控件,选择"改变开始开始...数量"为100)
第二步:增加常量(转换-->增加常量;给变量取个名称,类型和值。)

第三步:计算器(转换-->计算器;给出你的计算逻辑和计算出的字段;)

第四步:两个分支,一个输出;一个过滤;输出指定Excel,并执行数据发送模式(√:复制发送模式)
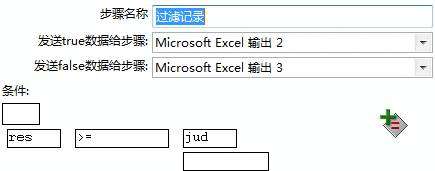
第五步:设置过滤(流程-->过滤记录);并双击控件填写对应的条件;
第六步:分组(统计-->分组),双击控件后有两个需要关注,一个是分组(相当于group by);一个是聚合(相当于count、sum等函数)
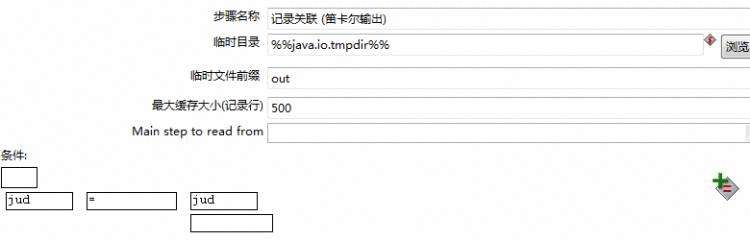
第七步:记录关联(连接-->记录关联(笛卡尔输出));这是一个join操作,但是没有on条件;但是控件中提供了sql中where条件的刷选
第八步:输出
Linux上部署kettle任务
kettle的"开始"控件虽然可以进行调度,但要求程序一直运行。在实际工作中通常在windos中测试,放到Linux中以crontab的方式进行调度。在Linux中以kitchen.sh执行job任务,pan.sh执行transform任务;这里我们以上面为实例,如何在Linux中进行部署。
第一步:通过WinSCP将kettle拷贝到Linux中,在拷贝路径中执行. kitchen.sh ,如果有参考消息输出则没有问题
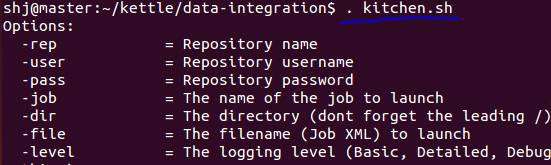
第二步:对于已在windos中执行成功的地址、文件名、用户等参数进行变量替换。执行export KETTLE_HOME=/home/shj,会生成/home/shj/.kettle目录,通过编辑目录下的kettle.properties文件来设置变量。实例中,我们仅仅需要替换两个输出文件的地址为变量即可。

第三步:修改kettle目录下的.sh文件权限为可执行(chmod a+x *.sh);并执行文件。

这里说明:/norep:表示不往资源库中写日志,Do not log into the repository
/file:使用文件,The filename (Job XML) to launch
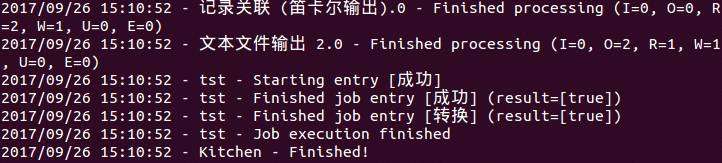
第四步:验证结果。
kettle中发送邮件
kettle发送邮件还是比较简单的,我们需要一个邮件发送的控件和对应的账号密码等自有信息
简单的流程:

需要配置发送邮件控件:
这样执行后,邮件就发送出去了。那么如何在kettle生产中利用邮件功能呢?我们可以将kettle的转换信息、统计信息、错误信息以文件的形式放入到指定的位置(或形成指定的参数),使用邮件以附件形式发送这些信息。
流程:

1、这里我们新增控件:添加文件到结果文件中;配置转换中的输出的文件
2、发送邮件中我们增加附件的配置,如下图
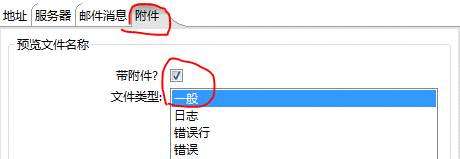
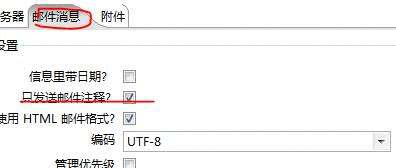
补充:如果觉得kettle发送的正文信息太多,可以配置邮件信息中,只发送邮件注释(注释信息需要自己写,如果是动态的话需要开发)
常见错误
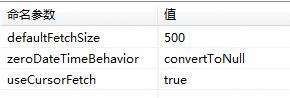
第一种:Timestamp:Unable to get timestamp from resultset at index 3**,如图。这个错误需要在db链接的选线中设置命令参数zeroDateTimeBehavior(值:convertToNull )

第二种:字段的空被替换成了null值。这是kettle默认的设置,需要我们在kettle.properties中增加设置(KETTLE_EMPTY_STRING_DIFFERS_FROM_NULL=Y)。

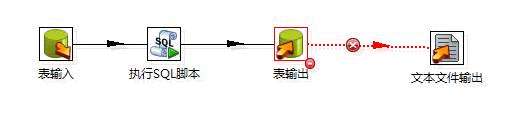
补充,在设计流程时我们并不希望出错了作业就停止了,而是继续执行并将错误信息以某种方式反馈出来。这时,我们可以通过“定义错误处理”来实现。
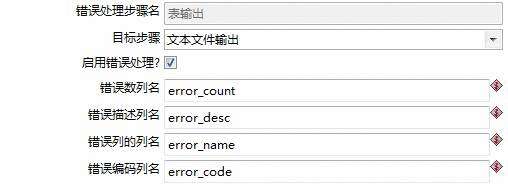
并将错误信息输出,供后续引用。






 京公网安备 11010802041100号
京公网安备 11010802041100号