
etcd 服务端的启动包括两大块:
etcdServer 主进程,直接或者间接包含了 raftNode、WAL、Snapshotter 等多个核心组件,可以理解为一个容器;
另一块则是 raftNode,对内部 Raft 协议实现的封装,暴露简单的接口,用来保证写事务的集群一致性。
etcd 可分为 Client 客户端层、API 网络接口层、etcd Raft 算法层、逻辑层和 etcd 存储层。如下图所示:
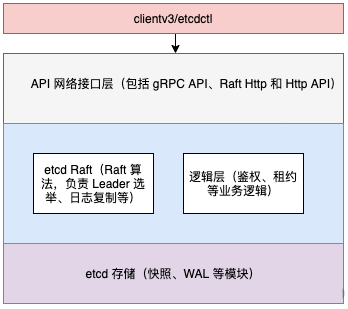
etcd 服务端对 EtcdServer 结构进行了抽象,其包含了 raftNode 属性,代表 Raft 集群中的一个节点。
etcd server 入口:
//etcdmain/main.go:25
func Main(args []string) {checkSupportArch()if len(args) > 1 {cmd := args[1]switch cmd {case "gateway", "grpc-proxy":if err := rootCmd.Execute(); err != nil {fmt.Fprint(os.Stderr, err)os.Exit(1)}return}}startEtcdOrProxyV2(args)
}
// 位于 etcdmain/etcd.go:52
func startEtcdOrProxyV2() {grpc.EnableTracing &#61; falsecfg :&#61; newConfig()defaultInitialCluster :&#61; cfg.ec.InitialCluster// 异常日志处理defaultHost, dhErr :&#61; (&cfg.ec).UpdateDefaultClusterFromName(defaultInitialCluster)var stopped <-chan struct{}var errc <-chan error// identifyDataDirOrDie 返回 data 目录的类型which :&#61; identifyDataDirOrDie(cfg.ec.GetLogger(), cfg.ec.Dir)if which !&#61; dirEmpty {switch which {// 以何种模式启动 etcdcase dirMember:stopped, errc, err &#61; startEtcd(&cfg.ec)case dirProxy:err &#61; startProxy(cfg)default:lg.Panic(..)}} else {shouldProxy :&#61; cfg.isProxy()if !shouldProxy {stopped, errc, err &#61; startEtcd(&cfg.ec)if derr, ok :&#61; err.(*etcdserver.DiscoveryError); ok && derr.Err &#61;&#61; v2discovery.ErrFullCluster {if cfg.shouldFallbackToProxy() {shouldProxy &#61; true}}}if shouldProxy {err &#61; startProxy(cfg)}}if err !&#61; nil {// ... 有省略// 异常日志记录}osutil.HandleInterrupts(lg)notifySystemd(lg)select {case lerr :&#61; <-errc:lg.Fatal("listener failed", zap.Error(lerr))case <-stopped:}osutil.Exit(0)
}
根据上述实现&#xff0c;我们可以绘制出如下的 startEtcdOrProxyV2 调用流程图&#xff1a;
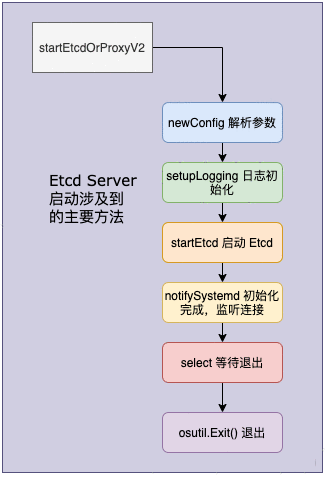
我们来具体解释一下上图中的每一个步骤。
cfg :&#61; newConfig()用于初始化配置&#xff0c;cfg.parse(os.Args[1:])&#xff0c;随后从第二个参数开始解析命令行输入参数。
setupLogging()&#xff0c;用于初始化日志配置。
identifyDataDirOrDie&#xff0c;判断 data 目录的类型&#xff0c;有 dirMember、dirProxy、dirEmpty&#xff0c;分别对应 etcd 目录、Proxy 目录和空目录。etcd 首先根据 data 目录的类型&#xff0c;判断启动 etcd 还是启动代理。如果是 dirEmpty&#xff0c;再根据命令行参数是否指定了 proxy 模式来判断。
startEtcd&#xff0c;核心的方法&#xff0c;用于启动 etcd&#xff0c;我们将在下文讲解这部分内容。
osutil.HandleInterrupts(lg) 注册信号&#xff0c;包括 SIGINT、SIGTERM&#xff0c;用来终止程序&#xff0c;并清理系统。
notifySystemd(lg)&#xff0c;初始化完成&#xff0c;监听对外的连接。
select()&#xff0c;监听 channel 上的数据流动&#xff0c;异常捕获与等待退出。
osutil.Exit()&#xff0c;接收到异常或退出的命令。
通过上述流程&#xff0c;我们可以看到 startEtcdOrProxyV2 的重点是 startEtcd。下面我们就来具体分析其启动的过程。
// startEtcd runs StartEtcd in addition to hooks needed for standalone etcd.
func startEtcd(cfg *embed.Config) (<-chan struct{}, <-chan error, error) {e, err :&#61; embed.StartEtcd(cfg)if err !&#61; nil {return nil, nil, err}osutil.RegisterInterruptHandler(e.Close)select {case <-e.Server.ReadyNotify(): // wait for e.Server to join the clustercase <-e.Server.StopNotify(): // publish aborted from &#39;ErrStopped&#39;}return e.Server.StopNotify(), e.Err(), nil
}
startEtcd启动 etcd 服务主要是通过调用StartEtcd方法&#xff0c;该方法的实现位于 embed 包&#xff0c;用于启动 etcd 服务器和 HTTP 处理程序&#xff0c;以进行客户端/服务器通信。
// 位于 embed/etcd.go:92
func StartEtcd(inCfg *Config) (e *Etcd, err error) {// 校验 etcd 配置if err &#61; inCfg.Validate(); err !&#61; nil {return nil, err}serving :&#61; false// 根据合法的配置&#xff0c;创建 etcd 实例e &#61; &Etcd{cfg: *inCfg, stopc: make(chan struct{})}cfg :&#61; &e.cfg// 为每个 peer 创建一个 peerListener(rafthttp.NewListener)&#xff0c;用于接收 peer 的消息if e.Peers, err &#61; configurePeerListeners(cfg); err !&#61; nil {return e, err}// 创建 client 的 listener(transport.NewKeepAliveListener) contexts 的 map&#xff0c;用于服务端处理客户端的请求if e.sctxs, err &#61; configureClientListeners(cfg); err !&#61; nil {return e, err}for _, sctx :&#61; range e.sctxs {e.Clients &#61; append(e.Clients, sctx.l)}// 创建 etcdServerif e.Server, err &#61; etcdserver.NewServer(srvcfg); err !&#61; nil {return e, err}e.Server.Start()// 在 rafthttp 启动之后&#xff0c;配置 peer Handlerif err &#61; e.servePeers(); err !&#61; nil {return e, err}// ...有删减return e, nil
}
根据上述代码&#xff0c;我们可以总结出如下的调用步骤&#xff1a;
inCfg.Validate()检查配置是否正确&#xff1b;
e &#61; &Etcd{cfg: *inCfg, stopc: make(chan struct{})}创建一个 etcd 实例&#xff1b;
configurePeerListeners 为每个 peer 创建一个 peerListener(rafthttp.NewListener)&#xff0c;用于接收 peer 的消息&#xff1b;
configureClientListeners 创建 client 的 listener(transport.NewKeepAliveListener)&#xff0c;用于服务端处理客户端的请求&#xff1b;
etcdserver.NewServer(srvcfg)创建一个 etcdServer 实例&#xff1b;
启动etcdServer.Start()&#xff1b;
配置 peer handler。
其中etcdserver.NewServer(srvcfg)和etcdServer.Start()分别用于创建一个 etcdServer 实例和启动 etcd&#xff0c;下面我们就分别介绍一下这两个步骤。
服务端初始化涉及比较多的业务操作&#xff0c;包括 etcdServer 的创建、启动 backend、启动 raftNode 等&#xff0c;下面我们具体介绍这些操作。
NewServer 方法用于创建一个 etcdServer 实例&#xff0c;我们可以根据传递过来的配置创建一个新的 etcdServer&#xff0c;在 etcdServer 的生存期内&#xff0c;该配置被认为是静态的。
我们来总结一下 etcd Server 的初始化涉及的主要方法&#xff0c;如下内容&#xff1a;
NewServer() |-v2store.New() // 创建 store&#xff0c;根据给定的命名空间来创建初始目录|-wal.Exist() // 判断 wal 文件是否存在|-fileutil.TouchDirAll // 创建文件夹|-openBackend // 使用当前的 etcd db 返回一个 backend|-restartNode() // 已有 WAL&#xff0c;直接根据 SnapShot 启动&#xff0c;最常见的场景|-startNode() // 在没有 WAL 的情况下&#xff0c;新建一个节点 |-tr.Start // 启动 rafthttp|-time.NewTicker() 通过创建 &EtcdServer{} 结构体时新建 tick 时钟
需要注意的是&#xff0c;我们要在 kv 键值对重建之前恢复租期。当恢复 mvcc.KV 时&#xff0c;重新将 key 绑定到租约上。如果先恢复 mvcc.KV&#xff0c;它有可能在恢复之前将 key 绑定到错误的 lease。
另外就是最后的清理逻辑&#xff0c;在没有先关闭 kv 的情况下关闭 backend&#xff0c;可能导致恢复的压缩失败&#xff0c;并出现 TX 错误。
创建好 etcdServer 实例之后&#xff0c;另一个重要的操作便是启动 backend。backend 是 etcd 的存储支撑&#xff0c;openBackend调用当前的 db 返回一个 backend。openBackend方法的具体实现如下&#xff1a;
// 位于 etcdserver/backend.go:68
func openBackend(cfg ServerConfig) backend.Backend {// db 存储的路径fn :&#61; cfg.backendPath()now, beOpened :&#61; time.Now(), make(chan backend.Backend)go func() {// 单独协程启动 backendbeOpened <- newBackend(cfg)}()// 阻塞&#xff0c;等待 backend 启动&#xff0c;或者 10s 超时select {case be :&#61; <-beOpened:return becase <-time.After(10 * time.Second):// 超时&#xff0c;db 文件被占用)}return <-beOpened
}
可以看到&#xff0c;我们在openBackend的实现中首先创建一个 backend.Backend 类型的 chan&#xff0c;并使用单独的协程启动 backend&#xff0c;设置启动的超时时间为 10s。beOpened <- newBackend(cfg)主要用来配置 backend 启动参数&#xff0c;具体的实现则在 backend 包中。
etcd 底层的存储基于 boltdb&#xff0c;使用newBackend方法构建 boltdb 需要的参数&#xff0c;bolt.Open(bcfg.Path, 0600, bopts)在给定路径下创建并打开数据库&#xff0c;其中第二个参数为打开文件的权限。如果该文件不存在&#xff0c;将自动创建。传递 nil 参数将使 boltdb 使用默认选项打开数据库连接。
在NewServer的实现中&#xff0c;我们可以基于条件语句判断 Raft 的启动方式&#xff0c;具体实现如下&#xff1a;
switch {case !haveWAL && !cfg.NewCluster:// startNodecase !haveWAL && cfg.NewCluster:// startNodecase haveWAL:// restartAsStandaloneNode// restartNodedefault:return nil, fmt.Errorf("unsupported Bootstrap config")
}
haveWAL变量对应的表达式为wal.Exist(cfg.WALDir())&#xff0c;用来判断是否存在 WAL&#xff0c;cfg.NewCluster则对应 etcd 启动时的--initial-cluster-state&#xff0c;标识节点初始化方式&#xff0c;该配置默认为new&#xff0c;对应的变量 haveWAL 的值为 true。new 表示没有集群存在&#xff0c;所有成员以静态方式或 DNS 方式启动&#xff0c;创建新集群&#xff1b;existing 表示集群存在&#xff0c;节点将尝试加入集群。
在三种不同的条件下&#xff0c;raft 对应三种启动的方式&#xff0c;分别是&#xff1a;startNode、restartAsStandaloneNode 和 restartNode。下面我们将结合判断条件&#xff0c;具体介绍这三种启动方式。
startNode
在如下的两种条件下&#xff0c;raft 将会调用 raft 中的startNode方法。
- !haveWAL && cfg.NewCluster
- !haveWAL && !cfg.NewCluster
- startNode(cfg, cl, cl.MemberIDs())
- startNode(cfg, cl, nil)
// startNode 的定义
func startNode(cfg ServerConfig, cl *membership.RaftCluster, ids []types.ID) (id types.ID, n raft.Node, s *raft.MemoryStorage, w *wal.WAL) ;
可以看到&#xff0c;这两个条件下都会调用 startNode 方法&#xff0c;只不过调用的参数有差异。在没有 WAL 日志&#xff0c;并且是新配置结点的场景下&#xff0c;需要传入集群的成员 ids&#xff0c;如果加入已有的集群则不需要。
我们以其中的一种 case&#xff0c;具体分析&#xff1a;
case !haveWAL && !cfg.NewCluster:// 加入现有集群时检查初始配置&#xff0c;如有问题则返回错误if err &#61; cfg.VerifyJoinExisting(); err !&#61; nil {return nil, err}// 使用提供的地址映射创建一个新 raft 集群cl, err &#61; membership.NewClusterFromURLsMap(cfg.Logger, cfg.InitialClusterToken, cfg.InitialPeerURLsMap)if err !&#61; nil {return nil, err}// GetClusterFromRemotePeers 采用一组表示 etcd peer 的 URL&#xff0c;并尝试通过访问其中一个 URL 上的成员端点来构造集群existingCluster, gerr :&#61; GetClusterFromRemotePeers(cfg.Logger, getRemotePeerURLs(cl, cfg.Name), prt)if gerr !&#61; nil {return nil, fmt.Errorf("cannot fetch cluster info from peer urls: %v", gerr)}if err &#61; membership.ValidateClusterAndAssignIDs(cfg.Logger, cl, existingCluster); err !&#61; nil {return nil, fmt.Errorf("error validating peerURLs %s: %v", existingCluster, err)}// 校验兼容性if !isCompatibleWithCluster(cfg.Logger, cl, cl.MemberByName(cfg.Name).ID, prt) {return nil, fmt.Errorf("incompatible with current running cluster")}remotes &#61; existingCluster.Members()cl.SetID(types.ID(0), existingCluster.ID())cl.SetStore(st)cl.SetBackend(be)// 启动 raft Nodeid, n, s, w &#61; startNode(cfg, cl, nil)cl.SetID(id, existingCluster.ID())
从上面的主流程来看&#xff0c;首先是做配置的校验&#xff0c;然后使用提供的地址映射创建一个新的 raft 集群&#xff0c;校验加入集群的兼容性&#xff0c;最后启动 raft Node。
StartNode 基于给定的配置和 raft 成员列表&#xff0c;返回一个新的节点&#xff0c;它将每个给定 peer 的 ConfChangeAddNode 条目附加到初始日志中。peers 的长度不能为零&#xff0c;如果长度为零将调用 RestartNode 方法。
RestartNode 与 StartNode 类似&#xff0c;但不包含 peers 列表&#xff0c;集群的当前成员关系将从存储中恢复。如果调用方存在状态机&#xff0c;则传入已应用到该状态机的最新一个日志索引值&#xff1b;否则直接使用零作为参数。
重启 raft Node
当已存在 WAL 文件时&#xff0c;raft Node 启动时首先需要检查响应文件夹的读写权限&#xff08;当集群初始化之后&#xff0c;discovery token 将不会生效&#xff09;&#xff1b;接着将会加载快照文件&#xff0c;并从 snapshot 恢复 backend 存储。
cfg.ForceNewCluster对应 etcd 配置中的--force-new-cluster&#xff0c;如果为 true&#xff0c;则会强制创建一个新的单成员集群&#xff1b;否则重新启动 raft Node。
restartAsStandaloneNode
当--force-new-cluster配置为 true 时&#xff0c;则会调用 restartAsStandaloneNode&#xff0c;即强制创建一个新的单成员集群。该节点将会提交配置更新&#xff0c;强制删除集群中的所有成员&#xff0c;并添加自身作为集群的一个节点&#xff0c;同时我们需要将其备份设置进行还原。
restartAsStandaloneNode 的实现中&#xff0c;首先读取 WAL 文件&#xff0c;并且丢弃本地未提交的 entries。createConfigChangeEnts 创建一系列 Raft 条目&#xff08;即 EntryConfChange&#xff09;&#xff0c;用于从集群中删除一组给定的 ID。如果当前节点self出现在条目中&#xff0c;也不会被删除&#xff1b;如果self不在给定的 ID 内&#xff0c;它将创建一个 Raft 条目以添加给定的self默认成员&#xff0c;随后强制追加新提交的 entries 到现有的数据存储中。
最后就是设置一些状态&#xff0c;构造 raftNode 的配置&#xff0c;重启 raft Node。
restartNode
在已有 WAL 数据的情况中&#xff0c;除了restartAsStandaloneNode场景&#xff0c;当--force-new-cluster为默认的 false 时&#xff0c;直接重启 raftNode。这种操作相对来说比较简单&#xff0c;减少了丢弃本地未提交的 entries 以及强制追加新提交的 entries 的步骤。接下来要做的就是直接重启 raftNode 还原之前集群节点的状态&#xff0c;读取 WAL 和快照数据&#xff0c;最后启动并更新 raftStatus。
分析完 raft Node 的启动&#xff0c;接下来我们看 rafthttp 的启动。Transport 实现了 Transporter 接口&#xff0c;它提供了将 raft 消息发送到 peer 并从 peer 接收 raft 消息的功能。我们需要调用 Handler 方法来获取处理程序&#xff0c;以处理从 peerURLs 接收到的请求。用户需要先调用 Start 才能调用其他功能&#xff0c;并在停止使用 Transport 时调用 Stop。
rafthttp 的启动过程中首先要构建 Transport&#xff0c;并将 m.PeerURLs 分别赋值到 Transport 中的 Remote 和 Peer 中&#xff0c;之后将 srv.r.transport 指向构建好的 Transport 即可。
接下来就是 etcd 的真正启动了&#xff0c;我们来看主要调用步骤&#xff1a;
// 位于 embed/etcd.go:220
e.Server.Start()
// 接收 peer 消息
if err &#61; e.servePeers(); err !&#61; nil {
return e, err
}
// 接收客户端请求
if err &#61; e.serveClients(); err !&#61; nil {
return e, err
}
// 提供导出 metrics
if err &#61; e.serveMetrics(); err !&#61; nil {
return e, err
}
serving &#61; true
启动 etcd Server&#xff0c;包括三个主要的步骤&#xff1a;首先e.Server.Start初始化 Server 启动的必要信息&#xff1b;接着实现集群内部通讯&#xff1b;最后开始接收 peer 和客户端的请求&#xff0c;包括 range、put 等请求。
e.Server.Start
在处理请求之前&#xff0c;Start方法初始化 Server 的必要信息&#xff0c;需要在Do和Process之前调用&#xff0c;且必须是非阻塞的&#xff0c;任何耗时的函数都必须在单独的协程中运行。Start方法的实现中还启动了多个 goroutine&#xff0c;这些协程用于选举时钟设置以及注册自身信息到服务器等异步操作。
集群内部通信
集群内部的通信主要由 Etcd.servePeers 实现&#xff0c;在 rafthttp.Transport 启动之后&#xff0c;配置集群成员的处理器。首先生成 http.Handler 来处理 etcd 集群成员的请求&#xff0c;并做一些配置校验。goroutine 读取 gRPC 请求&#xff0c;然后调用 srv.Handler 处理这些请求。srv.Serve总是返回非空的错误&#xff0c;当 Shutdown 或者 Close 时&#xff0c;返回的错误则是 ErrServerClosed。最后srv.Serve在独立协程启动对集群成员的监听。
处理客户端请求
Etcd.serveClients主要用来处理客户端请求&#xff0c;比如我们常见的 range、put 等请求。etcd 处理客户端的请求&#xff0c;每个客户端的请求对应一个 goroutine 协程&#xff0c;这也是 etcd 高性能的支撑&#xff0c;etcd Server 为每个监听的地址启动一个客户端服务协程&#xff0c;根据 v2、v3 版本进行不同的处理。在serveClients中&#xff0c;还设置了 gRPC 的属性&#xff0c;包括 GRPCKeepAliveMinTime 、GRPCKeepAliveInterval 以及 GRPCKeepAliveTimeout 等。








 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有