Centos7部署ELK日志收集系统 一、ELK概述 :
ELK是一组开源软件的简称,其包括Elasticsearch、Logstash 和 Kibana。ELK最近几年发展迅速,已经成为目前最流行的集中式日志解决方案。
Elasticsearch : 能对大容量的数据进行接近实时的存储,搜索和分析操作。 本项目中主要通过Elasticsearch存储所有获取的日志。
Logstash : 数据收集引擎,它支持动态的的从各种数据源获取数据,并对数据进行过滤,分析,丰富,统一格式等操作,然后存储到用户指定的位置。
Kibana : 数据分析与可视化平台,对Elasticsearch存储的数据进行可视化分析,通过表格的形式展现出来。
Filebeat : 轻量级的开源日志文件数据搜集器。通常在需要采集数据的客户端安装Filebeat,并指定目录与日志格式,Filebeat就能快速收集数据,并发送给logstash进行解析,或是直接发给Elasticsearch存储。
Redis :NoSQL数据库(key-value),也数据轻型消息队列,不仅可以对高并发日志进行削峰还可以对整个架构进行解耦
传统ELK的经典框架 :
新型ELK框架 :
二、新型ELK搭建详细过程
下面是搭建过程中所需程序安装包:
1.客户端部署filebeat :
1)下载和安装key文件
rpm --import https://packages.elastic.co/GPG-KEY-elasticsearch
1)创建yum源文件
[root@localhost ~]# vim /etc/yum.repos.d/elk-elasticsearch.repo
3)安装启动
yum -y install filebeat
4)修改配置文件使filebeat获取的日志进入redis:
vm /etc/filebeat/filebeat.yml2.源码安装redis :
1)解压redis程序包:
tar zxf redis-3.2.9.tar.gz –C /usr/local
cd /usr/local/redis-3.2.9
vim /usr/local/redis/redis.conf
修改内容如下:
注 :此处是做演示,如果是线上部署elk建议开启持久化机制,保证数据不丢失
4)启动filebeat看看redis是否能接收到数据:
systemctl start filebeat
5)进入redis查看是否有数据:
#执行命令:
3.安装jdk
1)解压jdk安装包并创建软连接:
tar zxf /usr/local/src/jdk-8u131-linux-x64.tar.gz –C /usr/local/
2)配置环境变量:
vim /etc/profileJAVAHOME/lib:JAVA_HOME/lib: J A V A H O M E / l i b : CLASSPATHexportPATH=CLASSPATH export PATH= C L A S S P A T H e x p o r t P A T H = JAVAHOME/bin:JAVA_HOME/bin: J A V A H O M E / b i n :
source /etc/profile
3)查看jdk是否安装成功:
java -version4.安装Elasticsearch:
1)解压安装包并改名:
unzip elasticsearch-5.6.3.zip -d /usr/local/
vim /usr/local/elasticsearch/config/elasticsearch.yml
#这里指定的是集群名称,需要修改为对应的,开启了自发现功能后,ES会按照此集群名称进行集群发现
#目录需要手动创建
#ES监听地址任意IP都可访问
#若是集群,可在里面引号中添加,逗号隔开
··nable cors,保证_site类的插件可以访问es
Centos6不支持SecComp,而ES5.2.0默认bootstrap.system_call_filter为true进行检测,所以导致检测失败,失败后直接导致ES不能启动
注 :ES启动的时候回占用特别大的资源所以需要修改下系统参数,若不修改资源启动会异常退出
3)修改系统参数:
sysctl –p
soft nofile 65536 hard nofile 131072 soft nproc 65536 hard nproc 131072 5)设置用户资源参数:
6)创建用户并赋权:
useradd elk切换用户并后台启动ES:(elk用户修改了资源参数,如不切位elk用户启动会暴毙)
7)查看ES状况:
5.安装logstash:
tar /usr/local/src/logstash-5.3.1.tar.gz –C /usr/local/
2)测试
vim /usr/local/logstash/config/logstash-simple.conf
/usr/local/logstash/bin/logstash -f /usr/local/logstash/config/logstash-simple.conf
input {
通过配置文件启动服务查看效果:
nohup /usr/local/logstash/bin/logstash -f /usr/local/logstash/config/redis-spring.conf & curl http://10.254.254.201:9200/_search?pretty
6.安装ES插件:(elasticsearch-head)
注 :head安装需要从国外网站拉去东西,可能网速过慢导致安装失败(可以多试几次),下面有几种方法安装:
方法一、
安装phantomjs:
导入es-head程序包并解压:
查看端口状态:(端口默认9100)
方法二、
方法三、
查看刚刚从logstash推到ES中的数据:7.安装kibana
tar -zxvf /usr/local/kibana-5.3.1-linux-x86_64.tar.gz -C /usr/local/
2)修改kibana配置文件:
vim /usr/local/kibana-5.3.1-linux-x86_64/config/kibana.yml
3)后台启动kibana:
nohup /usr/local/kibana-5.3.1-linux-x86_64/bin/kibana >> /dev/null 2>&1 &
netstat –anot | grep 5601
4)使用Web访问kibana:
http://[Kibana IP]:5601
至此我们的ELK就安装OK了!!!!!!!!!!!



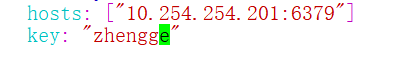























 京公网安备 11010802041100号
京公网安备 11010802041100号