logstash的处理过程
logstash在处理日志的整个过程是一个流的形式,按照 input -> filter-> output 这样的顺序进行。
(严格的说法是input -> decode -> filter -> encode -> output 这样的一个流,这里为了便于说明,简略下)
如图:
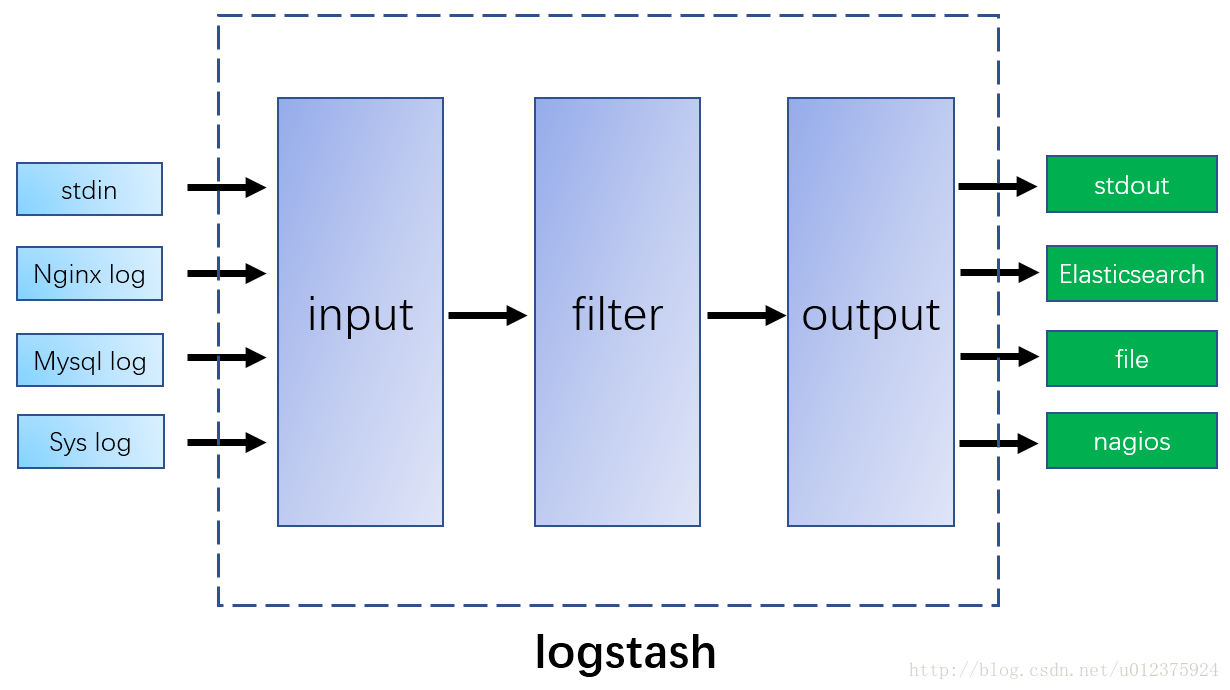
input:负责日志的接收,服务端角色。比如收集各服务器的nginx日志,MySQL日志,系统日志,php慢日志等。
filter: 对日志进行预处理等,后面会着重说下。
output: 负责日志的输出,比如储存到哪个地方或者执行某些动作。
可以通过如下方式来接收日志:
file:顾名思义,直接读文件
stdin: 标准输入,调试配置的时候玩玩
syslog: syslog协议的日志格式,比如linux的rsyslog
tcp/udp:使用tcp或udp传输过来的日志
看一个file的配置
input {file {path => ["/var/log/*.log", "/var/log/message"]type => "system"start_position => "beginning"codec => "json"}
}
这些参数用途如下:
path: 日志文件或目录的绝对路径,也可以是通配符的。
type: 类型,自定义
start_position: logstash 从什么位置开始读取文件数据,默认是结束位置,也就是说 logstash 进程会以类似 tail -F 的形式运行。如果你是要导入原有数据,把这个设定改成 "beginning",logstash 进程就从头开始读取,类似 less +F 的形式运行。
codec: codec配置,通过它可以更好更方便的与其他有自定义数据格式的运维产品共存,比如 graphite、fluent、netflow、collectd,以及使用 msgpack、json、edn 等通用数据格式的其他产品等。
再看一个tcp的配置
input {tcp {port => 8888mode => "server"ssl_enable => false}tcp {port => 9999mode => "server"ssl_enable => false}
}
这里可以看到它支持ssl加密,传输更安全。
更多input的插件请参考: Logstash Input
filter配置
这是今天的主菜:过滤器。
logstash收集到日志后,这些日志是原始的,但需求是多变的,比如日志中的有些内容要拆分成不同的字段,或者要把多种日志格式(比如有nginx日志,mysql慢日志等)统一成一种数据格式(比如json)等等,这些都通过filter来实现。
同input一样,filter也有各种各样的插件来处理日志,常见的有grok,ruby,kv,date等。这里主要介绍grok和ruby,详细参考Logstash Filter Plugin
如果你的日志在生成阶段就已经处理好了,不需要额外的处理时,可以不用filter,logstash可这样配置:
input {file {path => "/opt/logstash/log"codec => "json"}
}
output{stdout{codec=>rubydebug}
}
grok
grok类似于grep命令,是一个正则表达式的插件,通过正则匹配出我们需要的内容。
比如nginx的日志如下:
172.16.91.200 - - [19/Jan/2017:17:20:17 +0800] "GET /favicon.ico HTTP/1.1" 200 0 "http://172.16.93.237:9881/" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.95 Safari/537.36"
我想把里面的ip 172.16.91.200存储到clientip中,之后我在kibana中查看时,通过clientip就能查到ip了。
看一下grok是怎么匹配的
%{IPORHOST:clientip} - - \[%{HTTPDATE:request_time}\] \"(?:%{WORD:method} %{URIPATH:url}(?:%{URIPARAM:params})?(?: HTTP/%{NUMBER:httpversion})?|%{DATA:rawrequest})\" %{NUMBER:status} (?:%{NUMBER:bytes:int}|-) \"%{DATA:referrer}\" \"%{DATA:agent}\"
可以发现,它的形式并不像我们平常写的正则表达式。
看下grok语法:
%{PATTERN_NAME:capture_name:data_type}
这里有三部分PATTERN_NAME,capture_name,data_type。
1. PATTERN_NAM
正则变量,指向一个正则表达式,可以自定义,如
USERNAME [a-zA-Z0-9._-]+
USER %{USERNAME}
logstash默认提供了很多的正则表达式,具体可参考:Logstash Grok Patterns。
在调试grok时,可以借助下Grok Debugger。
回到刚才的grok,匹配客户端ip的部分是:
%{IPORHOST:clientip}
这里的正则用了IPORHOST,它实际内容如下:
IPORHOST (?:%{HOSTNAME}|%{IP})
可以看到它引用了两个正则变量HOSTNAME和IP,这两个的实际内容如下:
HOSTNAME \b(?:[0-9A-Za-z][0-9A-Za-z-]{0,62})(?:\.(?:[0-9A-Za-z][0-9A-Za-z-]{0,62}))*(\.?|\b)
IP (?:%{IPV6}|%{IPV4})
IP又引用了两个正则变量IPV4和IPV6。
2. capture_name
可以理解为把匹配的值存储到哪个field中。比如这里的ip匹配,存储为clientip。
3. data_type
数据类型,不是必填项。默认是字符串,其他类型还有float,int等。
了解了这三部分内容后,再看grok的配置就明了了。
看一个完整的配置:
input {file {path => "/opt/logstash/log"}
}filter {grok {match => {"message" => "%{IPORHOST:clientip} - - \[%{HTTPDATE:request_time}\] \"(?:%{WORD:method} %{URIPATH:url}(?:%{URIPARAM:params})?(?: HTTP/%{NUMBER:httpversion})?|%{DATA:rawrequest})\" %{NUMBER:status} (?:%{NUMBER:bytes:int}|-) \"%{DATA:referrer}\" \"%{DATA:agent}\""}}
}output{stdout{codec=>rubydebug}
}
ruby
通过filters/ruby插件,可以在filter中使用ruby,极大地方便了日志处理。
看一个官方的示例:
filter {ruby {init => "@kname = ['client','servername','url','status','time','size','upstream','upstreamstatus','upstreamtime','referer','xff','useragent']"code => "new_event = LogStash::Event.new(Hash[@kname.zip(event.get('message').split('|'))])new_event.remove('@timestamp')event.append(new_event)"}
}
参数如下:
init:用来预定义参数。
code:要运行的ruby语句。
比如我想对nginx日志进行一个简单的归类,区分下动态和静态资源。把css,图片,字体归为静态资源,其他的划为动态。配置示例如下:
input {file {path => "/opt/logstash/log"codec => "json"}
}filter {if [url] {ruby {code => "url_match = /(.*).(css|js|png|html|gif|png|woff)/.match(event.get('url'))if ( url_match )url_type = 'static'elseurl_type = 'dynamic'endevent.set('url_type',url_type)"}}
}output{stdout{codec=>rubydebug}
}
用logstash运行测试下,可以看到多了个值url_type
/opt/logstash/bin/logstash -f /etc/logstash/conf.d/test.conf
output配置
output负责把处理好日志输出到指定的地方,和input一样,output也有丰富的插件:
elasticsearch:可以通过http等方式存入elasticsearch 中
email:通过邮件发送出去
file: 存到文件中
nagios:发送到nagios中
exce: 执行某个程序或命令
statsd:输出到statsd中
stdout:有标准输入,那就有标准输出
tcp/udp:通过tcp/udp输出
HDFS:输出到hadoop中,搞大数据:)
这里主要看下输出到elasticsearch的配置。
output {elasticsearch {hosts => ["192.168.0.2:9200"]index => "logstash-%{type}-%{+YYYY.MM.dd}"document_type => "%{type}"flush_size => 20000idle_flush_time => 10sniffing => truetemplate_overwrite => true}
}
主要参数如下:
host: es的主机和端口
index:写入es的索引名称
document_type:es的document_type
flush_size:指定数据达到多少条时再发送
idle_flush_time:结合flush_size使用,指在这个时间内即使没攒够flush_size数,也发送。比如flush_size设置1000条,idle_flush_time设置为5秒,则在这5秒中,即使数目没达到1000条也会发送。而如果到3秒时就有1000条了,则会立即发送。
结语
logstash的input,filter,output三个阶段都有很丰富的插件,可根据自己的需求来搭配使用。
每部分可配置多个不同的内容,比如input可以同时配置file和tcp,并且配置多个tcp。
参考
Logstash 到底该怎么用
logstash使用指南








 京公网安备 11010802041100号
京公网安备 11010802041100号