点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
转载自:极市平台 | 作者:冯承健
导读
本文提出了一个开放世界的目标检测器PromptDet,它能够在没有任何手动标注的情况下检测新类别,其中提出区域prompt学习方法和针对网络图像的自训练方法,性能表现SOTA。

主页:https://fcjian.github.io/promptdet
论文:https://arxiv.org/abs/2203.16513
代码:https://github.com/fcjian/PromptDet
本文提出了一个开放世界的目标检测器PromptDet,它能够在没有任何手动标注的情况下检测新类别(如下图绿色检测框),其中提出区域prompt学习方法和针对网络图像的自训练方法,性能表现SOTA。

Abstract
这项工作的目标是建立一个可扩展的pipeline,使用零手动标注将目标检测器扩展到新的/看不见的类别。为了实现这一点,我们做出了以下四项贡献:(i)为了追求泛化性,我们提出了一个两阶段的开放词汇目标检测器,使用来自预训练视觉语言模型的文本编码器对类别无关的物体提议区域进行分类;(ii) 为了将RPN 提议区域的视觉潜在空间与预训练文本编码器的潜在空间配对,我们提出了区域prompt学习的想法,以将文本嵌入空间与物体区域的视觉特征对齐;(iii) 为了扩大学习过程以检测更广泛的类别,我们通过一种新颖的自训练框架利用可用的在线资源,该框架允许在大量嘈杂的未经处理的网络图像上训练所提出的检测器。最后,(iv)为了评估我们提出的检测器,称为PromptDet,我们对具有挑战性的 LVIS 和MS-COCO数据集进行了广泛的实验。与现有方法相比,PromptDet使用更少的额外训练图像和零手动标注,表现出卓越的检测性能。
Motivation
目标检测一直是计算机视觉中研究最广泛的问题之一,其目标是同时对图像中的目标进行定位和分类。在最近的文献中,检测社区通过对大规模数据集的训练取得了巨大的成功,例如PASCAL VOC,MS-COCO,它们详尽标注了特定类别的物体边界框和类别。然而,这种训练机制的可扩展性显然是有限的,因为该模型只能在易于收集和标注大规模数据的封闭且小范围的类别上表现良好。
另一方面,最近大规模的视觉语言预训练在开放词汇图像分类方面取得了巨大成功,这为扩展检测器词汇提供了可操作的机会。具体来说,这些视觉语言模型(例如CLIP和 ALIGN)通常通过噪声对比学习在十亿规模的嘈杂的图像-文本对上进行训练,展示出了理解图像中显著物体的能力(即‘what’)。然而,以相同的方式使用图像-文本对训练检测器,显然对可扩展性提出了重大挑战,因为它不仅要求文本要包含对象的语义(即‘what’),还需要空间信息(即'where')。因此,社区在开放词汇目标检测中考虑了一个稍微保守的场景:给定现有的在某些基本类别的大量数据上进行训练的目标检测器,我们希望用最少的人力扩展检测器定位和识别新类别的能力。
本文描述了一种将视觉潜在空间与预训练的语言编码器配对的简单想法,即继承CLIP的文本编码器作为“分类器”生成器,只训练检测器的视觉骨干和与类别无关的区域提取网络。我们方法的新颖之处在于对齐视觉和文本潜在空间的两个步骤。首先,我们提出在文本编码器端学习一定数量的prompt向量,称为区域prompt学习(简称RPL),从而可以转换其潜在空间,以更好地与以物体为中心的视觉特征配对。其次,我们通过从互联网上检索一组未经处理的候选图像来进一步迭代优化prompt向量,并在检索到的候选图像上生成伪标签,对检测器进行自训练(self-training)。我们命名这个检测器为PromptDet。在实验上,尽管候选图像中存在噪声,但这种自训练机制在开放词汇泛化方面,特别是在没有可用标注框的类别上,显示出显著的提升。
Methodology
Open Vocabulary Object Detector
一般来说,流行的两阶段目标检测器,例如Mask-RCNN,由视觉骨干编码器(ENC)、区域提议网络(RPN)和分类模块(CLS)组成:
因此,构建一个开放词汇的目标检测器需要解决两个后续问题:(1)有效地生成与类别无关的提议区域,以及(2)准确地将这些提议区域分类到一组闭集之外的视觉类别(新类别),即开放式词汇分类。
Class-agnostic region proposal networks():指不管它们的类别如何,提取所有可能有物体的区域的能力。在这里,我们以与类别无关的方式对anchor分类、box回归和mask预测进行参数化,即为所有类别共享参数。
Open-vocabulary classification():旨在对固定大小词汇之外的视觉对象进行分类。我们假设视觉和自然语言之间存在一个共同的潜在空间,我们可以在语言潜在空间中寻找其最接近的嵌入来对任何视觉对象进行分类,例如,将区域特征分类为“almond”或“dog”,可以计算出“almond”的分类概率:
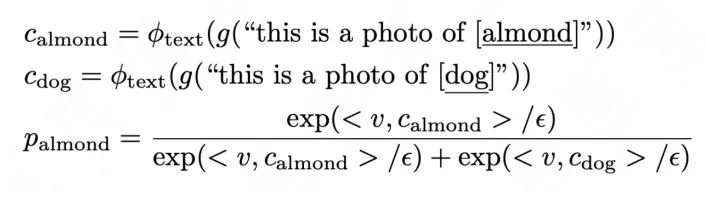
Naive Alignment via Detector Training
在本节中,我们的目标是在基本类别上训练一个开放词汇的目标检测器(基于Mask-RCNN),即只使用基本类别来优化视觉骨干和与类别无关的RPN,与继承自CLIP的预训练文本编码器的分类器对齐。
然而,正如我们的实验所表明的那样,将视觉潜在空间与文本空间自然对齐只会产生非常有限的开放词汇检测性能(新类别7.4 AP)。我们推测泛化能力差主要来自三个方面:
(i)仅使用类名计算类别嵌入是次优的,因为它们可能不够精确,无法描述视觉概念,导致词汇歧义,例如,“almond”可能是指具有硬壳的可食用的椭圆形坚果,也可以是指其生长的树;
(ii)用于训练CLIP的网络图像以场景为中心,物体仅占图像的一小部分,而来自RPN的物体提议区域通常会紧密定位对象,导致视觉表示上存在明显的域差距;
(iii)用于检测器训练的基本类别的多样性明显低于用于训练CLIP的类别多样性,因此,可能不足以保证对新类别的泛化。
Alignment via Regional Prompt Learning
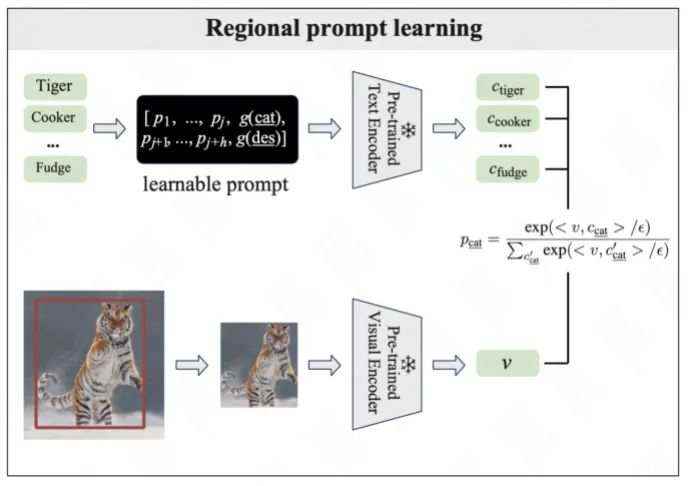
我们提出了一个简单的区域prompt学习 (RPL) 概念,引导文本潜在空间以更好地拟合以物体为中心的图像。具体来说,在计算类别分类器或嵌入时,我们将一系列可学习向量添加到文本输入中,称为“连续prompt向量”。此外,我们还在prompt模板中包含更详细的描述以减轻词汇的歧义,例如,{category: “almond”, description: “oval-shaped edible seed of the almond tree”}。因此,每个单独类别的嵌入可以生成为:
由于可学习向量与类别无关,并且为所有类别共享,因此它们可以在训练后迁移到新类别。我们从LVIS中获取基本类别的物体裁剪区域,相应地调整它们的大小,并通过冻结的CLIP视觉编码器生成图像嵌入,使用标准的交叉熵损失对这些图像嵌入进行分类。为了优化prompt向量,我们将视觉和文本编码器都冻结,只更新可学习的prompt向量。
PromptDet: Alignment via Self-training
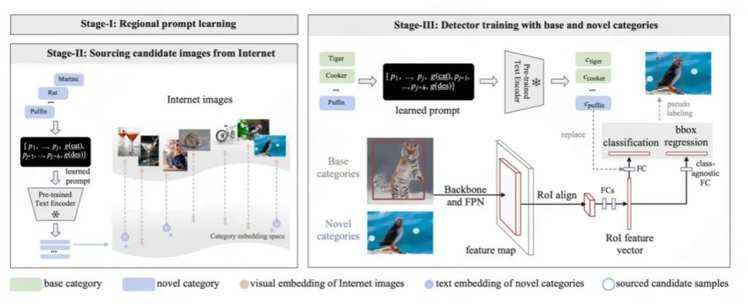
我们通过将视觉骨干与prompt文本编码器对齐,获得了一个开放词汇的目标检测器。然而,RPL仅利用了有限的视觉多样性,即仅使用基本类别。在本节中,我们释放了这种限制,并建议利用大规模、未经处理、嘈杂的网络图像来进一步改进对齐。如图所示,我们描述了一个学习框架,它迭代RPL和候选图像检索过程,然后生成检索图片的伪标签,并自训练开放词汇目标检测器。
Sourcing candidate images: 我们将LAION-400M数据集作为初始图像语料库,为了获取每个类别的候选图像,我们计算所有图像的视觉嵌入和类别嵌入之间的相似度分数,保留具有最高相似性的图像。
Iterative prompt learning and image sourcing: 我们迭代区域prompt学习的过程,然后以高精度检索图像。实验表明,这种迭代程序有利于以高精度挖掘以物体为中心的图像,它能够生成更准确的伪标签,因此在自训练后大大提高新类别的检测性能。
Bounding box generation: 我们使用我们的开放词汇检测器对检索到的图像进行推理,保留其RPN分数最高的前K个建议框,然后将具有最大分类分数的建议框作为图像的伪标签,用于自训练目标检测器。
Experiment
Dataset
开放词汇LVIS基准使用的数据集统计如下表所示:

Comparison with the State-of-the-Art
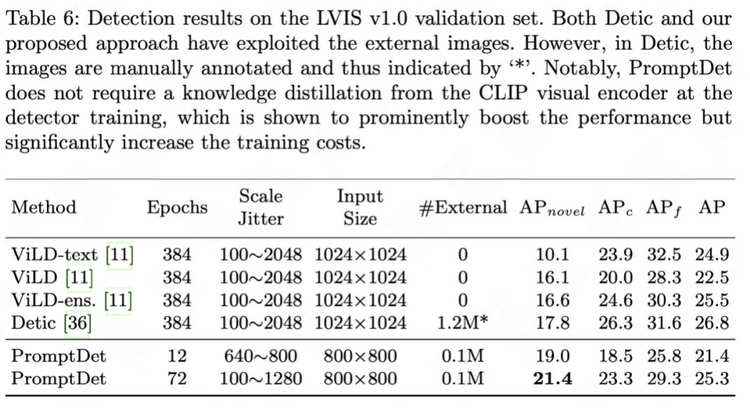
开放词汇LVIS基准目标检测结果。我们最好的模型只训练了72 个epoch,在新类别中达到了21.4 AP,分别超过了最近最先进的 ViLD-ens和Detic 4.8 AP 和 3.6 AP。
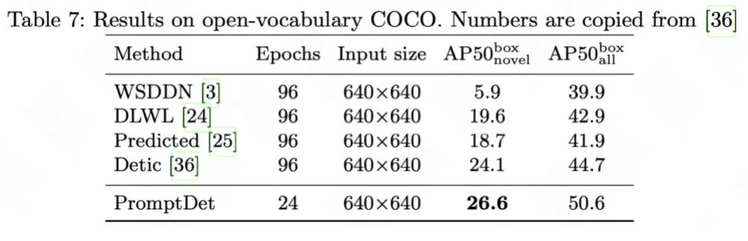
开放词汇COCO基准目标检测结果。训练了24个epoch的PromptDet在新类别mAP(26.6 AP 对 24.1 AP)和整体 mAP(50.6 AP 对 44.7 AP)上都优于Detic。
Ablation Study
区域prompt学习(RPL) 消融分析:

自训练(Self-training)消融分析:

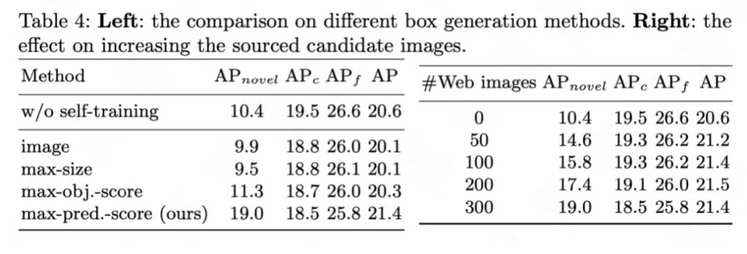
框生成(Box generation)和检索图像数量消融分析:
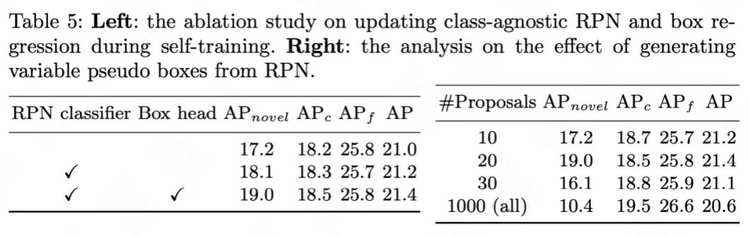
RPN和检测头更新以及伪标签生成中候选框数量消融分析:
Conclusion
本文提出区域prompt学习(RPL)方法调整预训练语言编码器的潜在空间,以更好地适应下游的目标检测任务。
本文提出目标图像检索和模型自训练(self-training)的完整学习方案,能够精准检索和有效利用未经处理的线上资源,大大提升目标检测器的性能。
我们希望本文提出的RPL和自训练方案能够给CV社区带来一些启发,高效地利用多模态大模型和丰富的线上资源,提升下游任务的性能。
点击进入—> CV 微信技术交流群
CVPR 2022论文和代码下载
后台回复:CVPR2022,即可下载CVPR 2022论文和代码开源的论文合集
后台回复:Transformer综述,即可下载最新的3篇Transformer综述PDF
目标检测和Transformer交流群成立
扫描下方二维码,或者添加微信:CVer222,即可添加CVer小助手微信,便可申请加入CVer-目标检测或者Transformer 微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer等。
一定要备注:研究方向+地点+学校/公司+昵称(如目标检测或者Transformer+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群▲扫码或加微信号: CVer222,进交流群
CVer学术交流群(知识星球)来了!想要了解最新最快最好的CV/DL/ML论文速递、优质开源项目、学习教程和实战训练等资料,欢迎扫描下方二维码,加入CVer学术交流群,已汇集数千人!▲扫码进群
▲点击上方卡片,关注CVer公众号
整理不易,请点赞和在看





 京公网安备 11010802041100号
京公网安备 11010802041100号