作者:mindylee | 来源:互联网 | 2023-09-06 20:36
线程池原理介绍线程池是一种多线程处理形式,处理过程中将任务添加到队列,然后在创建线程后自动启动这些任务。线程池线程都是后台线程。每个线程都使用默认的堆栈大小,以默认的优先级运行,并
线程池原理介绍
线程池是多线程处理的一种形式,在处理过程中向队列中添加任务,创建线程后自动启动任务。 线程池线程都是后台线程。 每个线程都使用缺省的堆栈大小,以缺省优先级运行,并位于多线程单元内。
线程池的组成部分:
线程池管理器:用于创建和管理线程池
“工作线程”:线程池中的线程
任务接口(Task ) :每个任务都必须实现的接口,才能调度任务的执行。
任务队列:用于存储未完成的任务。 提供缓冲机构。
多线程技术主要解决处理器单元内多个线程执行的问题,大大缩短处理器单元的空闲时间,提高处理器单元的吞吐量。
假设服务器完成任务所需的时间是T1线程的创建时间、T2线程执行任务的时间和T3线程的丢弃时间。
如果T1 T3远大于T2,则可以使用线程池来提高服务器的性能。
线程池有四个基本组件:
1、线程池管理器(ThreadPool ) )用于创建和管理线程池。 包括创建线程池、销毁线程池和添加新任务。
2、工作线程(PoolWorker )线程池内的线程在没有任务时处于等待状态,可以循环执行任务;
3、任务接口(Task )各任务是工作人员线程为调度任务执行而必须实现的接口,主要规定了任务的入口、任务执行后的完成、任务的执行状态等。
4、任务队列(taskQueue ) )用于存储未处理的任务。 提供缓冲机构。
分享一个手写线程池的视频讲解:手把手写线程池 更多Linux服务器开发高阶视频Nginx,ZeroMQ,MySQL,Redis,fastdfs,MongoDB,ZK,流媒体,CDN,P2P,K8S,Docker,TCP/IP,协程,DPDK等等,请后台私信【学习资料】获取 。
。
线程池技术关注缩短或调整T1、T3时间的技术,提高了服务程序的性能。 这将T1、T3分别配置在服务器程序的启动和结束的时间段或空闲时间段,使得服务器程序处理来自客户机的请求时没有T1、T3的开销。
线程池不仅可以调整T1、T3生成的时间段,还可以大幅减少要创建的线程数量。 让我们来看一个例子。
假设一个服务器每天处理50000个请求,每个请求需要一个单独的线程。 在线程池中,线程数通常是固定的,因此生成的线程总数不会超过线程池中的线程数。 如果服务器不使用线程池处理这些请求,则线程总数为50000。 一般线程池的大小远远小于50000。 因此,使用线程池的服务器程序在处理请求以创建50000时不会浪费时间,从而提高了效率。
代码实现没有实现任务接口,而是将Runnable对象添加到线程池管理器[threadpool]中,其余的工作由线程池管理器[threadpool]完成。
为了充分利用多核的优势,我们利用多线程进行了任务处理,但线程也同样不能滥用。 会发生以下问题。
1 )线程本身有开销,系统必须对每个线程分配堆栈、TLS (线程本地存储)、寄存器等。
2 )线程管理给系统带来开销,上下文切换也同样给系统带来成本。
3 )线程本身是可重复使用的资源,不需要每次都进行初始化。
因此,在大多数情况下,在使用中不需要将线程和task任务一对一地对应,只要预先初始化有限的线程数来处理无限的task任务即可。 线程池的产生,原理也是一样的。
线程池的具体配置如下:
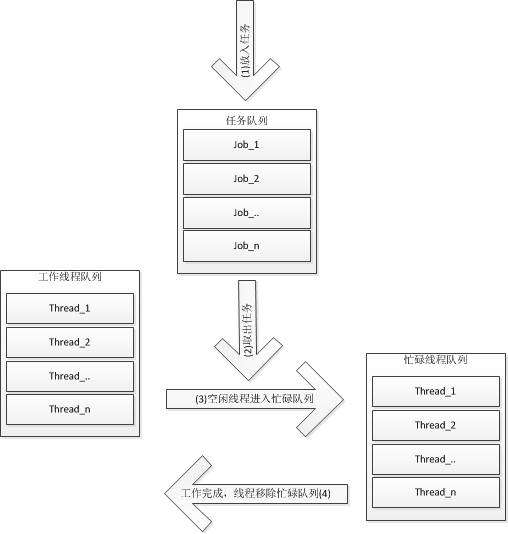
主要有三个队列
工作队列
工作机线程队列
繁忙线程队列
工作队列是阻塞队列,任务(伪函数)任务不进入推送)由notify阻塞获取的工作线程),工作线程队列)直接从该队列获取任务执行)在wait中获取,
代码实现:
# #一次程序
# # ifndef网格_轮询_ h
# #定义thread _ pool _ h
# #包括向量机
# #包含队列
# #包括
e
#include
//#include
//#include
//#include
#include
namespace std
{
//线程池最大容量,应尽量设害羞的巨人点
#define THREADPOOL_MAX_NUM 16
//#define THREADPOOL_AUTO_GROW
//线程池,可以提交变参函数或拉姆达表达式的匿名函数执行,可以获取执行返回值
//不直接支持类成员函数, 支持类静态成员函数或全局函数,Opteron()函数等
class threadpool
{
using Task = function;//定义类型
vector _pool; //线程池
queue _tasks; //任务队列
mutex _lock; //同步
condition_variable _task_cv; //条件阻塞
atomic _run{ true }; //线程池是否执行
atomic _idlThrNum{ 0 }; //空闲线程数量
public:
inline threadpool(unsigned short size = 4) { addThread(size); }
inline ~threadpool()
{
_run=false;
_task_cv.notify_all(); // 唤醒所有线程执行
for (thread& thread : _pool) {
//thread.detach(); // 让线程“自生自灭”
if(thread.joinable())
thread.join(); // 等待任务结束, 前提:线程一定会执行完
}
}
public:
// 提交一个任务
// 调用.get()获取返回值会等待任务执行完,获取返回值
// 有两种方法可以实现调用类成员,
// 一种是使用 bind: .commit(std::bind(&Dog::sayHello, &dog));
// 一种是用 mem_fn: .commit(std::mem_fn(&Dog::sayHello), this)
template
auto commit(F&& f, Args&&... args) ->future
{
if (!_run) // stoped ??
throw runtime_error("commit on ThreadPool is stopped.");
using RetType = decltype(f(args...)); // typename std::result_of::type, 函数 f 的返回值类型
auto task = make_shared>(
bind(forward(f), forward(args)...)
); // 把函数入口及参数,打包(绑定)
future future = task->get_future();
{ // 添加任务到队列
lock_guard lock{ _lock };//对当前块的语句加锁 lock_guard 是 mutex 的 stack 封装类,构造的时候 lock(),析构的时候 unlock()
_tasks.emplace([task](){ // push(Task{...}) 放到队列后面
(*task)();
});
}
#ifdef THREADPOOL_AUTO_GROW
if (_idlThrNum <1 && _pool.size() addThread(1);
#endif // !THREADPOOL_AUTO_GROW
_task_cv.notify_one(); // 唤醒一个线程执行
return future;
}
//空闲线程数量
int idlCount() { return _idlThrNum; }
//线程数量
int thrCount() { return _pool.size(); }
#ifndef THREADPOOL_AUTO_GROW
private:
#endif // !THREADPOOL_AUTO_GROW
//添加指定数量的线程
void addThread(unsigned short size)
{
for (; _pool.size() 0; --size)
{ //增加线程数量,但不超过 预定义数量 THREADPOOL_MAX_NUM
_pool.emplace_back( [this]{ //工作线程函数
while (_run)
{
Task task; // 获取一个待执行的 task
{
// unique_lock 相比 lock_guard 的好处是:可以随时 unlock() 和 lock()
unique_lock lock{ _lock };
_task_cv.wait(lock, [this]{
return !_run || !_tasks.empty();
}); // wait 直到有 task
if (!_run && _tasks.empty())
return;
task = move(_tasks.front()); // 按先进先出从队列取一个 task
_tasks.pop();
}
_idlThrNum--;
task();//执行任务
_idlThrNum++;
}
});
_idlThrNum++;
}
}
};
}
#endif //https://github.com/lzpong/
##C++11语言细节 即使懂原理也不代表能写出程序,上面用了众多c++11的“奇技淫巧”,下面简单描述之。
using Task = function 是类型别名,简化了 typedef 的用法。function 可以认为是一个函数类型,接受任意原型是 void() 的函数,或是函数对象,或是匿名函数。void() 意思是不带参数,没有返回值。
pool.emplace_back([this]{...}) 和 pool.push_back([this]{...}) 功能一样,只不过前者性能会更好;
pool.emplace_back([this]{...}) 是构造了一个线程对象,执行函数是拉姆达匿名函数 ;
所有对象的初始化方式均采用了 {},而不再使用 () 方式,因为风格不够一致且容易出错;
匿名函数: [this]{...} 不多说。[] 是捕捉器,this 是引用域外的变量 this指针, 内部使用死循环, 由cv_task.wait(lock,[this]{...}) 来阻塞线程;
delctype(expr) 用来推断 expr 的类型,和 auto 是类似的,相当于类型占位符,占据一个类型的位置;auto f(A a, B b) -> decltype(a+b) 是一种用法,不能写作 decltype(a+b) f(A a, B b),为啥?! c++ 就是这么规定的!
commit 方法是不是很奇葩!可以带任意多的参数,第一个参数是 f,后面依次是函数 f 的参数(注意:参数要传struct/class的话,建议用pointer,小心变量的作用域)! 可变参数模板是 c++11 的一大亮点,够亮!至于为什么是 Arg... 和 arg... ,因为规定就是这么用的!
commit 直接使用智能调用stdcall函数,但有两种方法可以实现调用类成员,一种是使用 bind: .commit(std::bind(&Dog::sayHello, &dog)); 一种是用 mem_fn: .commit(std::mem_fn(&Dog::sayHello), &dog);
make_shared 用来构造 shared_ptr 智能指针。用法大体是 shared_ptr p = make_shared(4) 然后 *p == 4 。智能指针的好处就是, 自动 delete !
bind 函数,接受函数 f 和部分参数,返回currying后的匿名函数,比如 bind(add, 4) 可以实现类似 add4 的函数!
forward() 函数,类似于 move() 函数,后者是将参数右值化,前者是... 肿么说呢?大概意思就是:不改变最初传入的类型的引用类型(左值还是左值,右值还是右值);
packaged_task 就是任务函数的封装类,通过 get_future 获取 future , 然后通过 future 可以获取函数的返回值(future.get());packaged_task 本身可以像函数一样调用 () ;
queue 是队列类, front() 获取头部元素, pop() 移除头部元素;back() 获取尾部元素,push() 尾部添加元素;
lock_guard 是 mutex 的 stack 封装类,构造的时候 lock(),析构的时候 unlock(),是 c++ RAII 的 idea;
condition_variable cv; 条件变量, 需要配合 unique_lock 使用;unique_lock 相比 lock_guard 的好处是:可以随时 unlock() 和 lock()。 cv.wait() 之前需要持有 mutex,wait 本身会 unlock() mutex,如果条件满足则会重新持有 mutex。
最后线程池析构的时候,join() 可以等待任务都执行完再结束,很安全!







 京公网安备 11010802041100号
京公网安备 11010802041100号