
360搜索事业部云平台一直致力于将容器技术在生产环境中落地,已开源企业级Kubernetes管理平台Wayne(https://github.com/Qihoo360/wayne),并经历了在生产环境大规模应用的考验。当下Prometheus是被广泛应用的监控系统,既是容器时代的标配,也同时解决了应用指标监控的问题。然而它的报警模块alert manager还有一些地方不是很完善,使用起来不够灵活,针对这一问题,我们开发并开源了哆啦A梦报警平台。本文主要介绍Prometheus在360搜索云平台的落地应用,以及结合哆啦A梦报警平台的功能实践。
360 Prometheus架构

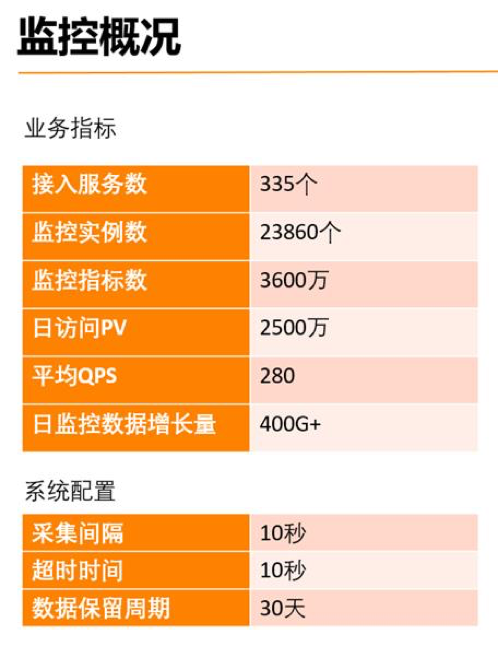
Prometheus全部使用容器部署,规模大,采用联邦架构。容器监控指标和物理机监控指标全部使用Prometheus采集。
Alertmanager的痛点
无法动态加载监控规则,需要修改配置文件
在使用Alertmanager的时候,需要修改Prometheus的配置文件将Alertmanager与Prometheus相关联
无法实现报警升级,不支持获取动态值班组,标签匹配不能动态配置(需要修改配置文件)
总而言之配置不够方便灵活,需要频繁修改配置文件,学习成本高。
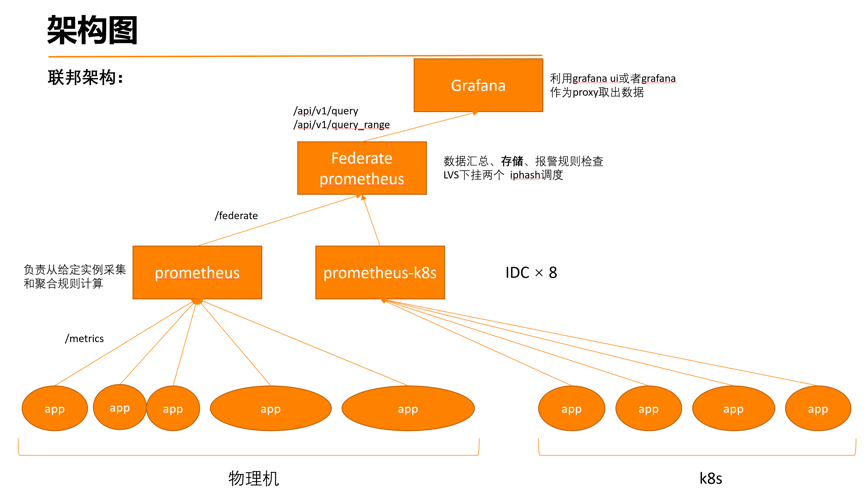
Doraemon的架构
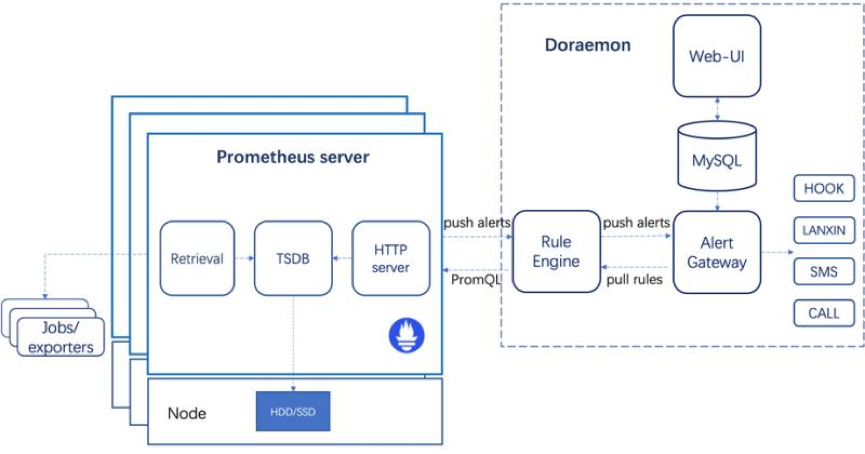
Rule Engine:从Alert Gateway动态拉取报警规则,并下发到多个Prometheus Server进行计算,与此同时接收从Prometheus Server发来的报警并转发给Alert Gateway。
Alert Gateway:接收从Rule Engine发送的报警,并根据报警策略聚合发送报警信息。
Web UI:用于运维人员添加报警规则,创建报警策略、维护组,进行报警确认或者查看历史报警。
术语
报警规则:与Prometheus中的 报警规则 概念相同。
数据源:Prometheus Server的URL,由Rule Engine将报警规则下发至该URL进行计算。
报警接收组:由多个报警接收人组成的组。
值班组:和报警接收组类似,但是它是动态的从接口中获取组成员的列表。
报警延迟:报警触发一段时间后才将报警发送给接收人。
报警周期:报警发送的周期。
报警计划:由多条报警策略组成的集合。
报警方式:对于内部用户,可以通过蓝信、短信和电话的方式进行报警。非内部用户可以采用hook的方式将报警转发到自定义的Web Server进行处理。
报警策略:一条报警策略包含报警延迟、报警周期、报警时间段、报警接收组、值班组以及报警方式等配置信息。
报警确认:如果需要短时间的暂停报警,可以通过勾选相应报警并填写暂停时长来确认报警。
维护组:如果希望屏蔽一些固定时间段内某些特定机器的报警,可以通过配置报警维护组策略来实现。
使用说明
创建报警计划
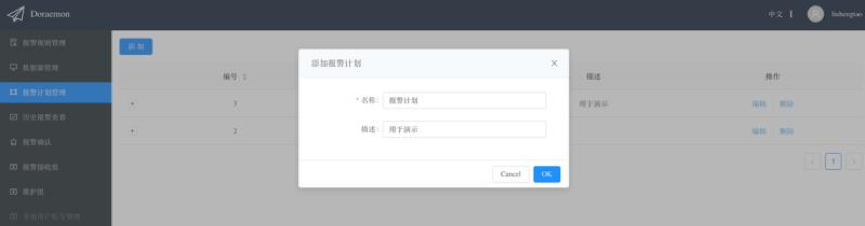
为报警计划添加报警策略:一个报警计划下面可以添加多个报警策略,通过这种方式既可以实现报警的定向发送也可以实现报警的升级。例如下面的报警计划实现了将含有标签idc=beijing的报警发给op1,将标签idc!=beijing的报警发送给op2,并且将所有超过60分钟还没有被确认的报警以电话形式通知leader。
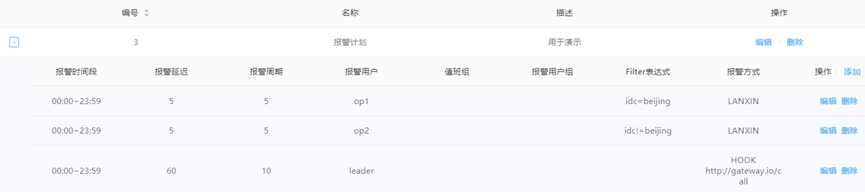
报警时间段:每天发送报警的时段
报警延迟:报警触发多长时间后才开始发送报警,可用于实现报警升级
报警周期:每隔多少分钟发送一次报警
报警用户:报警接收人,可以输入多个报警接收人
值班组:从接口动态获取报警值班人
报警用户组:可以创建报警用户组,一个报警用户组包含多个报警接收人
Filter表达式:通过label来过滤要发送的报警。支持“=”(等于),“!=”(不等于),“&”(与),“|”(或),“(”,“)”这几种运算符号,并且在保存Filter表达式之前会自动校验表达式的合法性,对于不合法的表达式会给出提示。例如只发送来自北京或上海机房并且app名称是search的报警,对应的Filter表达式就是“name=search&(idc=beijing|idc=shanghai)”
报警方式:支持hook方式将报警以HTTP POST请求的形式发送至指定报警网关
添加Prometheus信息
我们需要先配置好目标Prometheus Server的url,之后才能将报警规则下发到该Prometheus Server进行计算。
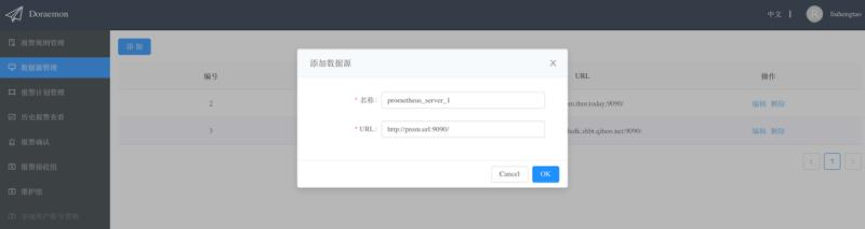
在完成前面两步之后,就可以添加报警规则了。
添加报警规则
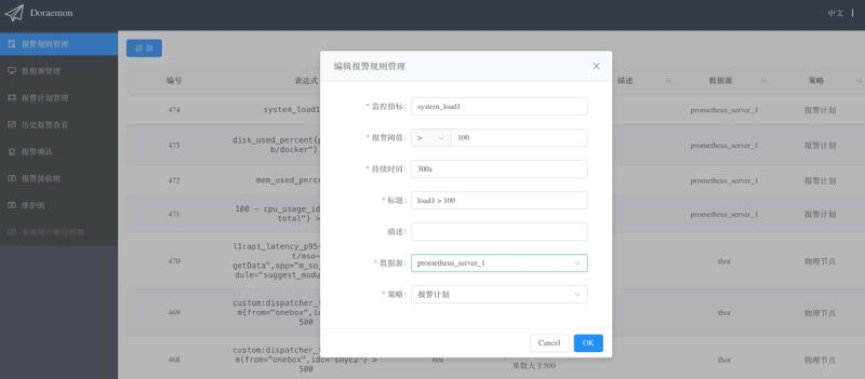
这里的配置和原生Prometheus的alerting rules配置一样,对于熟悉Prometheus的同学而言一目了然。

上面是Prometheus的配置。
下面是哆啦A梦添加报警规则的配置。
监控指标:对应Prometheus的alerting rules中的“expr”
报警阈值:expr的阈值
持续时间:对应Prometheus的alerting rules中的“for”
标题:对应Prometheus的alerting rules中的“summary”
描述:对应Prometheus的alerting rules中的“description”
数据源:关联到前面创建的Prometheus Server的信息,即将这条监控规则下发到该Prometheus进行计算
策略:关联到前面创建的报警计划
报警聚合
哆啦A梦所发送出来的报警都是从报警规则的维度进行聚合的,例如某个报警规则所关联的报警计划下面有两个报警策略,一条策略的报警周期是5分钟,则该条规则下的所有报警会每5分钟聚合一次并发送,另一条策略的报警周期是10分钟,则相应的报警会每10分钟聚合一次并发送。对于报警恢复的恢复信息会每分钟聚合一次并发送。对于同一条报警,根据报警策略的不同会以不同的报警延时,不同的报警周期聚合后发送给不同的接收者。
例如如下报警策略:报警持续5分钟后开始发出第一条报警,每5分钟发一次。假设在第0、1、2、3、4分钟的每一分钟都有2台不同的机器触发了rule A的报警,如果不聚合则在5-9分钟每分钟都会发出一个报警,每条报警包含两台机器的信息。这样当出现多条rule下的多台机器一起报警的时候,会出现在短时间内多条rule的报警交替出现,这样对运维人员不友好,不好辨别这一分钟里到底是哪几条rule触发的报警。
而聚合后,将在第5分钟将第0分钟触发的报警发出,第10分钟将第0、1、2、3、4分钟的报警聚合发出,即每五分钟聚合一次rule A的报警。如果某个报警在第1分钟到第9分钟内触发,并且在这期间又恢复了,则用户不会收到报警信息以及报警恢复信息。对于同一条报警,由于报警策略不同,会导致有的用户可能收到过该条报警,而有的用户没有,系统会保证该条报警的恢复信息只会发送给已经收到过该报警的用户。对于没有发出的报警可以在报警历史记录中查看。
报警确认
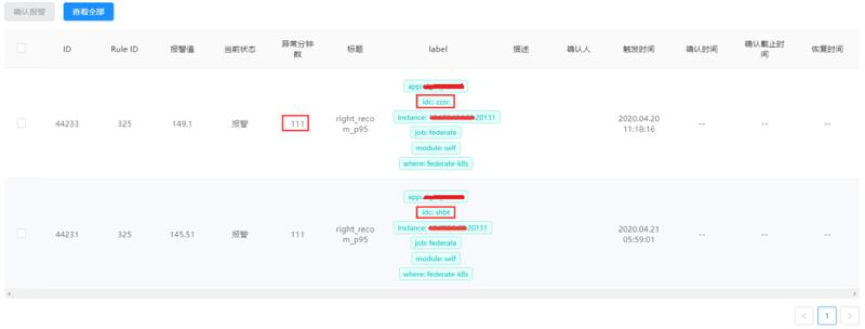
有两种方式进行报警确认,一种是点击报警信息中的确认链接,这种方式是从报警规则的维度进行报警确认的(因为报警是以报警规则的维度聚合发送的),例如,在报警策略中配置了报警延时为5分钟,只接收idc=zzzc和idc=shbt的报警,则点开报警确认链接只能看到以及确认满足该报警策略的报警。也就是说,不同的报警策略所展示的报警确认页面的内容也是不同的:

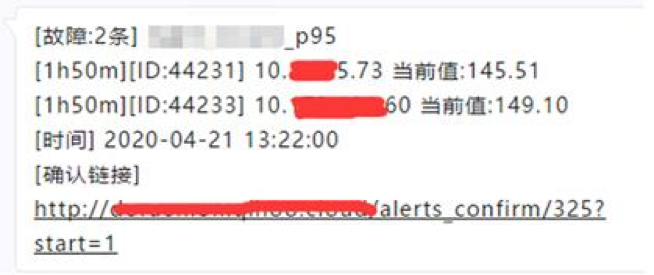
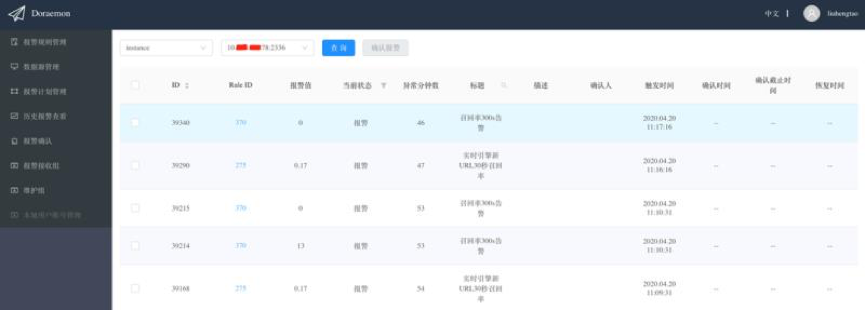
另一种报警确认方式是从label的维度进行报警确认,比如IP为10.0.0.1的机器宕机了,触发了多条报警规则的报警,此时从报警规则的维度进行报警确认效率很低,但如果从label的维度进行报警确认就会非常方便,因为含有“instance=10.0.0.1:9090”的报警都是该机器产生的报警我们可以一次性的确认。下图是从label的维度进行报警确认:
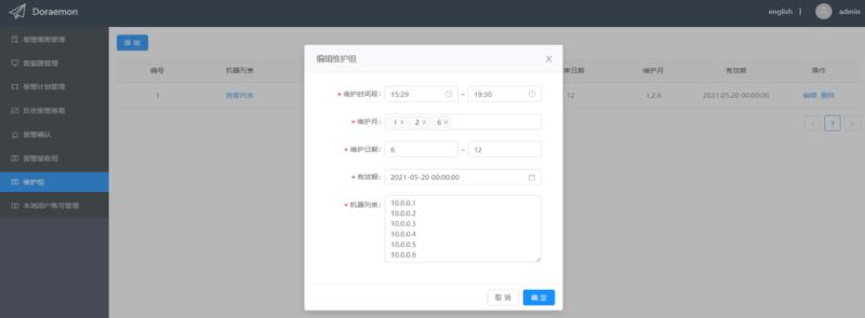
维护组
有些时候可能会有大批量的机器处于维护状态,或者某些机器在一段时间内出现故障,需要屏蔽来自这些机器的报警,此时就可以将这些机器的instance标签的值(不含端口号)作为机器的唯一识别信息加入维护组。
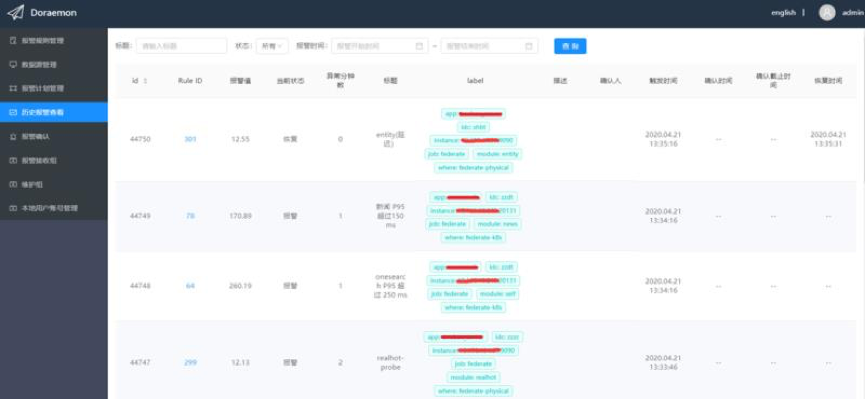
此外,在“历史报警查看” 页面可以看到历史报警。
哆啦A梦的快速部署
哆啦A梦提供了两种部署方式:一种是基于docker-compose本地部署,由于没有提供额外的高可用机制,因此这种方式仅用于本地测试。另一种方式是基于Kubernetes集群部署,用于生产环境。两种部署方式都非常简单。
后续计划
支持多租户。
Prometheus管理,一键部署Prometheus,Prometheus配置、规则管理。
Grafana面板集成,一键部署Grafana,Grafana配置、dashboard管理。
预制常用软件监控、容器监控规则。
报警方式支持微信、钉钉、邮件等方式。
该项目会在近期开源,目前在公司内部走开源流程。
Q&A
Q:告警支持哪些平台的接口呢?自由度怎么样呢?可以在产品中,配置定制化的接口的json格式呢?
A:支持hook和公司内部的蓝信、短信以及电话,对于公司外部的用户可以暂时使用hook模式,后续会支持微信、短信、邮件、钉钉。
Q:告警触发器是如何管理的?
A:Prometheus根据报警规则的阈值进行内部计算得来的。
Q:Prometheus如何对接多个Kubernetes集群实现集群Pod的弹性伸缩?
A:利用Kubernetes的HPA通过报警平台的hook机制来做弹性伸缩。
Q:Prometheus原生是单点,在告警和存储方面,哆啦A梦是如何支持集群模式的?
A:告警的存储使用MySQL,Prometheus只是用于计算规则的。集群模式可以使用多个Prometheus进行计算,至于Promeheus的架构由用户自身决定。
Q:Prometheus使用过程中存在哪些性能陷阱,能否举例。如何评估预判Prometheus性能容量?
A:在Prometheus的数据量非常大的时候会有性能瓶颈,特别是在计算直方图以及采集大量节点的时候,但一般场景下不会有这样的问题。
Q:Prometheus部署在集群内还是集群外,多个集群的实例如何统一监控告警?是否支持跨集群应用实例的监控告警?如何实现?
A:哆啦A梦不关心Prometheus是部署在集群内还是集群外,只要能通过url访问即可。目前不支持基于多个Prometheus的告警聚合,后续可以考虑实现。
Q:按刚才分享的案例看,其实这个系统可以类比为基于alert rule id --> pageduty的一个大系统么?
A:实际不是,因为真正的alerts和发送流程是由哆啦A梦控制的,而不是Prometheus,Prometheus只是负责计算报警规则。
Q:自动恢复这方面有考虑吗?比如告警触发对于脚本去自动恢复?
A:自动恢复目前没有做,这个不同公司不同场景差异很大。用户可以根据Doraemon发出的报警,自定义恢复逻辑。
关注本公众号(分布式实验室,ID:dockerone),回复:哆啦A梦,获取PPT下载方式。
基于Kubernetes的DevOps实战培训
基于Kubernetes的DevOps实战培训将于2020年5月15日在上海开课,3天时间带你系统掌握Kubernetes,学习效果不好可以继续学习。本次培训包括:容器特性、镜像、网络;Kubernetes架构、核心组件、基本功能;Kubernetes设计理念、架构设计、基本功能、常用对象、设计原则;Kubernetes的数据库、运行时、网络、插件已经落地经验;微服务架构、组件、监控方案等,点击下方图片或者阅读原文链接查看详情。







 京公网安备 11010802041100号
京公网安备 11010802041100号