20. 为什么dropout在训练期间神经元将被连接到两倍于( 平均) 的输入神经元。 为了弥补这个事实,我们需要在训练之后将每个神经元的输入连接权重乘以 1-p??
有一个小而重要的技术细节。 假设 p = 50% ,在这种情况下,在测试期间,输入的信号是训练新号的两倍,因为训练的时候对输入信号进行了dropout(p=0.5),而测试的时候不进行dropout,所以训练的时候输入信号只是测试的一半,一般的在训练期间神经元将被连接到两倍于( 平均) 的输入神经元。 为了保证输入信号的量不会发生巨大变化,造成网络的不稳定。我们将训练之后将每个神经元的输入连接权重乘以 0.5。这样保证了测试的信号输入量和训练的是一样的。更一般地说,我们需要将每个输入连接权重乘以训练后的保持概率(1-p)。
或者:在训练时,激活神经元的平均数量为原来的 p倍。而在测试时,所有的神经元都是可以激活的,这会造成训练和测试时网络的输出不一致。为了缓解这个问题,在测试时需要将每一个神经元的输出乘以 p,也相当于把不同的神经网络做了平均。
大型网络但是数据集缺少的时候可以使用dropout防止过拟合,对于小型网络或者说不缺数据集的网络不推荐使用。
21. dropout 是否会减慢训练? 它是否会减慢预测( 即预测新的实例) ?
是的,dropout确实会减慢训练的速度,一般来说,大约是两倍。然而,它对预测没有影响,因为它只在训练时打开。
22.Dropout 是如何用训练好的网络来预测输出?即如何将训练好的网络组合起来?和bagging一样吗?
而做预测Dropout是关闭的状态,代表着做预测时是所有训练时结构不同的神经网络一起做的最后的预测。整个过程就是多个不同神经网络最后投票做决定给出预测值。
当层较宽时,丢弃所有从输入到输出的可能路径的概率变小,所以这个问题对于层较宽的网络不是很重要。
这里我们再讲一种和Bagging类似但是又不同的正则化方法:Dropout。
所谓的Dropout指的是在用前向传播算法和反向传播算法训练DNN模型时,一批数据迭代时,随机的从全连接DNN网络中去掉一部分隐藏层的神经元。
比如我们本来的DNN模型对应的结构是这样的:
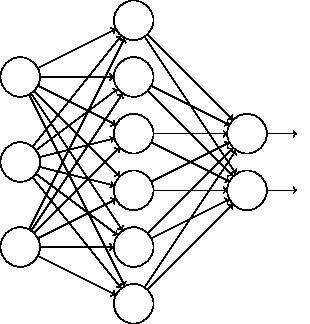
在对训练集中的一批数据进行训练时,我们随机去掉一部分隐藏层的神经元,并用去掉隐藏层的神经元的网络来拟合我们的一批训练数据。如下图,去掉了一半的隐藏层神经元:
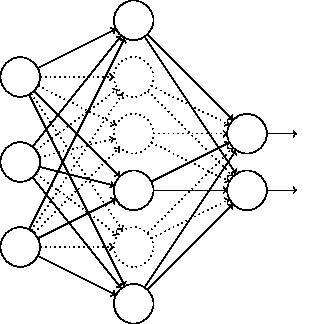
然后用这个去掉隐藏层的神经元的网络来进行一轮迭代,更新所有的W,b。这就是所谓的dropout。
当然,dropout并不意味着这些神经元永远的消失了。在下一批数据迭代前,我们会把DNN模型恢复成最初的全连接模型,然后再用随机的方法去掉部分隐藏层的神经元,接着去迭代更新W,b。当然,这次用随机的方法去掉部分隐藏层后的残缺DNN网络和上次的残缺DNN网络并不相同。
总结下dropout的方法: 每轮梯度下降迭代时,它需要将训练数据分成若干批,然后分批进行迭代,每批数据迭代时,需要将原始的DNN模型随机去掉部分隐藏层的神经元,用残缺的DNN模型来迭代更新W,b。每批数据迭代更新完毕后,要将残缺的DNN模型恢复成原始的DNN模型。
从上面的描述可以看出dropout和Bagging的正则化思路还是很不相同的。dropout模型中的W,b是一套,共享的(很多博客都说共享,一直不理解,原来才是W,b是只有一组,每用不同的网络训练一次,就更新一次W.b)。所有的残缺DNN迭代时,更新的是同一组W,b;而Bagging正则化时每个DNN模型有自己独有的一套W,b参数,相互之间是独立的。当然他们每次使用基于原始数据集得到的分批的数据集来训练模型,这点是类似的。
使用基于dropout的正则化比基于bagging的正则化简单,这显而易见,当然天下没有免费的午餐,由于dropout会将原始数据分批迭代,因此原始数据集最好较大,否则模型可能会欠拟合。
24. dropout可以比较有效地减轻过拟合的发生,一定程度上达到了正则化的效果。论其原因而言,主要可以分为两个方面:
达到了一种Vote的作用。对于全连接神经网络而言,我们用相同的数据去训练5个不同的神经网络可能会得到多个不同的结果,我们可以通过一种vote机制来决定多票者胜出,因此相对而言提升了网络的精度与鲁棒性。同理,对于单个神经网络而言,如果我们将其进行分批,虽然不同的网络可能会产生不同程度的过拟合,但是将其公用一个损失函数,相当于对其同时进行了优化,取了平均,因此可以较为有效地防止过拟合的发生。
减少神经元之间复杂的共适应性。当隐藏层神经元被随机删除之后,使得全连接网络具有了一定的稀疏化,从而有效地减轻了不同特征的协同效应。也就是说,有些特征可能会依赖于固定关系的隐含节点的共同作用,而通过Dropout的话,它强迫一个神经单元,和随机挑选出来的其他神经单元共同工作,达到好的效果。消除减弱了神经元节点间的联合适应性,增强了泛化能力。
由于每次用输入网络的样本进行权值更新时,隐含节点都是以一定概率随机出现,因此不能保证每2个隐含节点每次都同时出现,这样权值的更新不再依赖于有固定关系隐含节点的共同作用,阻止了某些特征仅仅在其它特定特征下才有效果的情况。
---------------------
bagging与dropout:
- 在bagging中,所有的分类器都是独立的,而在dropout中,所有的模型都是共享参数的。
- 在bagging中,所有的分类器都是在特定的数据集下训练至收敛,而在dropout中没有明确的模型训练过程。网络都是在一步中训练一次(输入一个样本,随机训练一个子网络)
- (相同点)对于训练集来说,每一个子网络的训练数据是通过原始数据的替代采样得到的子集。(这个意思就是,对于bagging来说,训练集是从整个样本中又放回的随机采样得到的,而对于dropout来说是相当于随机采样整个网络的权值,但是这里面不会有重复采样的权值,两个方法都是每次训练新的网络或者森林从完整的数据中进行采样)
主要参考:https://www.cnblogs.com/pinard/p/6472666.html(强烈推荐)
https://blog.csdn.net/m0_37477175/article/details/77145459
https://blog.csdn.net/fu6543210/article/details/84450890











 京公网安备 11010802041100号
京公网安备 11010802041100号