作者:顾久君_152_599 | 来源:互联网 | 2023-10-12 16:11
SwinTransformer感觉是基于ViT提出的,ViT打破了CV和NLP之间的壁垒,但是由于Transformer与CNN相比,少了一些归纳偏置,使得其在数据集较小的时候
Swin Transformer感觉是基于ViT提出的,ViT打破了CV和NLP之间的壁垒,但是由于Transformer与CNN相比,少了一些归纳偏置,使得其在数据集较小的时候性能较差,另外由于其使用低分辨率特征映射且计算复杂度是图像大小的二次方,其体系结构不适合用于密集视觉任务的通用主干网络或输入图像分辨率较高时,Swin Transformer就是在ViT的基础上将层次性、局部性和平移不变性等先验引入Transformer网络结构设计从而能在视觉任务中取得更好的性能,能适用于多种CV任务,且其复杂度相对图片大小为线性相关,计算效率也十分不错。
主要特点 将层次性、局部性和平移不变性等先验引入Transformer网络结构设计。
核心创新:移位窗口(shifted window)设计: 1)自注意的计算在局部的非重叠窗口内进行。这一设计有两方面的好处,一是复杂度从此前的和图像大小的平方关系变成了线性关系,也使得层次化的整体结构设计、局部先验的引入成为可能,二是因为采用非重叠窗口,自注意计算时不同query会共享同样的key集合,从而对硬件友好,更实用。 2)在前后两层的Transformer模块中,非重叠窗口的配置相比前一层做了半个窗口的移位,这样使得上一层中不同窗口的信息进行了交换。 相比于卷积网络以及先驱的自注意骨干网络(Local Relation Net和SASA)中常见的滑动窗(Sliding window)设计,这一新的设计牺牲了部分平移不变性,但是实验发现平移不变性的部分丢失不会降低准确率,甚至以为正则效应效果更好。同时,这一设计对硬件更友好,从而更实用而有希望成为主流。(摘自胡瀚老师在ReadPaper网站的回答)
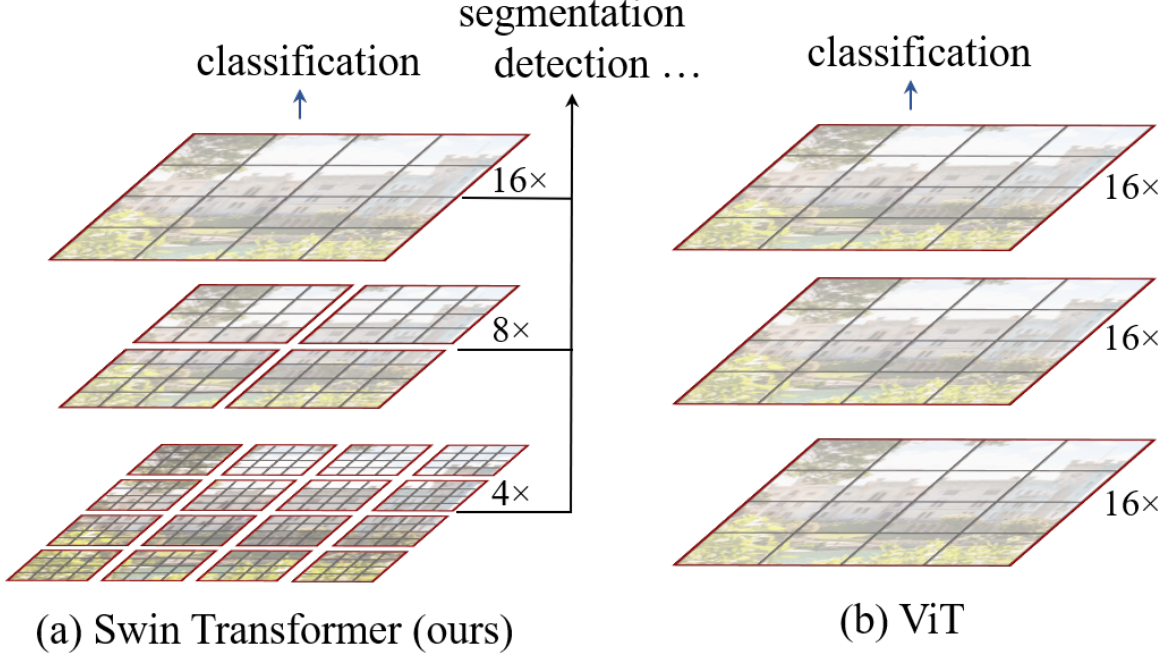
Swin Transformer采用了分层结构,通过从小尺寸的patchs(以灰色勾勒)开始,并逐渐将相邻patchs合并到更深的Transformer层中来构建层次表示。有了这些分层特征映射,Swin Transformer模型可以方便地利用先进技术进行密集预测,如特征金字塔网络(FPN)或U-Net。线性计算复杂度是通过在分割图像的非重叠窗口内局部计算自注意力来实现的(a)所提出的Swin Transformer通过在更深的层中合并图像块(以灰色显示)来构建分层特征图,并且由于仅在每个局部窗口(以红色显示)内计算自注意力,因此对于输入图像大小具有线性计算复杂度。因此,它可以作为图像分类和密集识别任务的通用主干。(b)相比之下,以前的vision Transformer产生单一低分辨率的特征图,并且由于全局计算自注意力,输入图像大小具有二次计算复杂性。

在所提出的Swin Transformer架构中,用于计算自注意力的移位窗口方法的示例。在层l(左),采用规则的窗口划分方案,并在每个窗口内计算自注意力。在下一层l+1(右)中,窗口分区被移动,从而产生新窗口。新窗口中的自注意力计算跨越层中以前窗口的边界,提供它们之间的连接。
总体结构如下:

(a) Swin Transformer(Swin-T)的结构;(b)两个连续的Swin Transformer块。W-MSA和SW-MSA分别是具有规则和移位窗口配置的多头自注意力模块。

论文中提出了一种向左上方向循环移位的高效批处理计算移位配置方法,在该移位之后,批处理窗口可能由多个子窗口组成,这些子窗口在特征图中不相邻,因此采用mask机制将自注意力计算限制在每个子窗口内。使用循环移位,批处理窗口的数量与常规窗口分区的数量相同,因此也是有效的。












 京公网安备 11010802041100号
京公网安备 11010802041100号